
Appliquer une préparation à un échantillon de données dans un Job Apache Spark Streaming
Ce scénario s'applique uniquement aux solutions Talend Real-Time Big Data Platform et Talend Data Fabric.
Pour plus de technologies supportées par Talend, consultez Composants Talend.
Le composant tDataprepRun vous permet de réutiliser une préparation existante créée dans Talend Data Preparation ou Talend Cloud Data Preparation, directement dans un Job d'intégration de données. En d'autres termes, vous pouvez opérationnaliser le processus d'application d'une préparation à des fichiers d'entrée ayant le même modèle.
Le scénario suivant décrit un Job simple qui :
- utilise un petit échantillon de données de clients,
- applique une préparation existante sur ces données,
- affiche le résultat de la transformation dans la console.
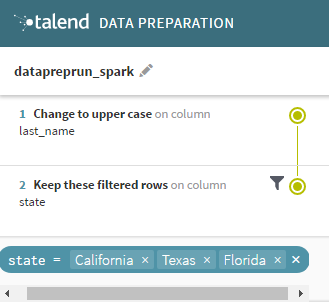
Cela présuppose qu'une préparation ait été précédemment créée, sur un jeu de données ayant le même schéma que vos données d'entrée dans le Job. Dans ce cas, la préparation existante est nommée datapreprun_spark.
Cette préparation assez simple met les noms des employés en majuscule, et applique un filtre pour n'afficher que les clients originaires de Californie, du Texas et de Floride.
Notez que si une préparation contient des actions affectant une seule ligne ou des cellules, elles seront ignorées par le composant tDataprepRun au cours du Job. Les fonctions Make as header ou Delete Row, par exemple, ne fonctionnent pas dans un contexte Big Data.
James;Butt;California
Daniel;Fox;Connecticut
Donna;Coleman;Alabama
Thomas;Webb;Illinois
William;Wells;Florida
Ann;Bradley;California
Sean;Wagner;Florida
Elizabeth;Hall;Minnesota
Kenneth;Jacobs;Florida
Kathleen;Crawford;Texas
Antonio;Reynolds;California
Pamela;Bailey;Texas
Patricia;Knight;Texas
Todd;Lane;New Jersey
Dorothy;Patterson;Virginia
Le tHDFSConfiguration est utilisé dans ce scénario par Spark afin de se connecter au système HDFS où sont transférés les fichiers Jar dépendant du Job.
-
Yarn mode (Yarn Client ou Yarn Cluster) :
-
Lorsque vous utilisez Google Dataproc, spécifiez un bucket dans le champ Google Storage staging bucket de l'onglet Spark configuration.
-
Lorsque vous utilisez HDInsight, spécifiez le blob à utiliser pour le déploiement du Job, dans la zone Windows Azure Storage configuration de l'onglet Spark configuration.
- Lorsque vous utilisez Altus, spécifiez le bucket S3 ou le stockage Azure Data Lake Storage (aperçu technique) pour le déploiement du Job, dans l'onglet Spark configuration.
- Lorsque vous utilisez Qubole, ajoutez tS3Configuration à votre Job pour écrire vos données métier dans le système S3 avec Qubole. Sans tS3Configuration, ces données métier sont écrites dans le système Qubole HDFS et détruites une fois que vous arrêtez votre cluster.
-
Lorsque vous utilisez des distributions sur site (on-premises), utilisez le composant de configuration correspondant au système de fichiers utilisé par votre cluster. Généralement, ce système est HDFS et vous devez utiliser le tHDFSConfiguration (en anglais).
-
-
Standalone mode : utilisez le composant de configuration correspondant au système de fichiers que votre cluster utilise, comme le tHDFSConfiguration Apache Spark Batch ou le tS3Configuration Apache Spark Batch (en anglais).
Si vous utilisez Databricks sans composant de configuration dans votre Job, vos données métier sont écrites directement dans DBFS (Databricks Filesystem).
Prérequis : assurez-vous de la bonne installation et du bon fonctionnement du cluster Spark.