Editing the converted Job
Update the components to finalize a data transformation process that runs in the Spark Streaming framework.
A Kafka cluster is used instead of the DBFS system to provide the streaming movie data to the Job. The director data is still ingested from DBFS in the lookup flow.
Before you begin
-
The Databricks cluster to be used has been properly configured and is running.
-
The administrator of the cluster has given read/write rights and permissions to the username to be used for the access to the related data and directories in DBFS and the Azure ADLS Gen2 storage system.
Procedure
-
In the Repository, double-click the aggregate_movie_director_spark_streaming Job to
open it in the workspace.
The
 icons indicate that the
components that are used in the original Job do not exist in the current Job
framework, Spark Batch. They are tHDFSInput and tHDFSOutput in this example.
icons indicate that the
components that are used in the original Job do not exist in the current Job
framework, Spark Batch. They are tHDFSInput and tHDFSOutput in this example. -
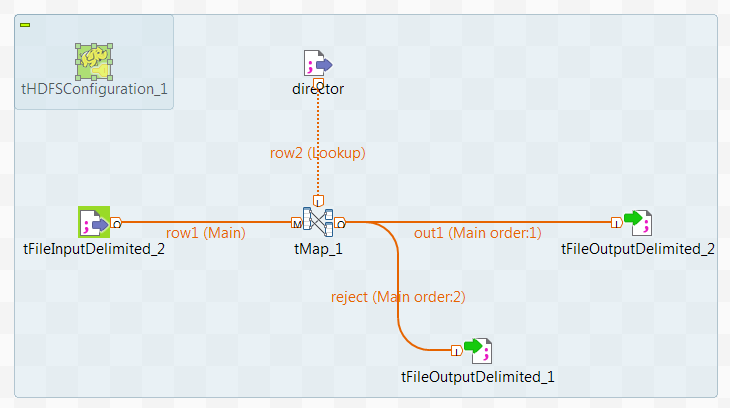
Right-click tMap, then from the
context menu, select Row > out1 and click the new
tFileOutputDelimited to connect tMap to this component.
-
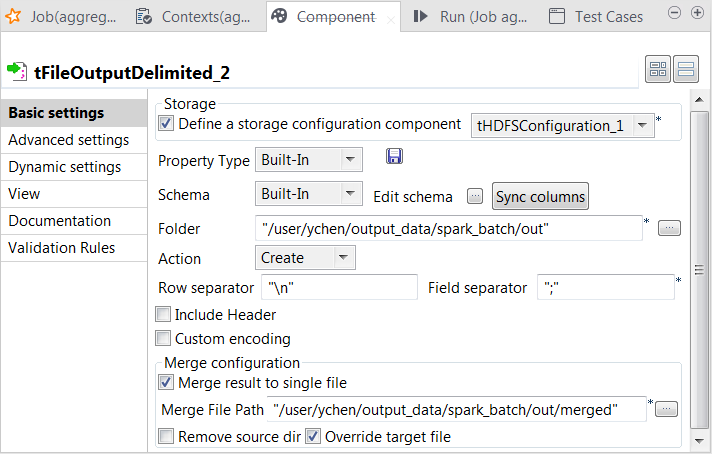
Double-click the new tFileOutputDelimited component to open its Component view.
-
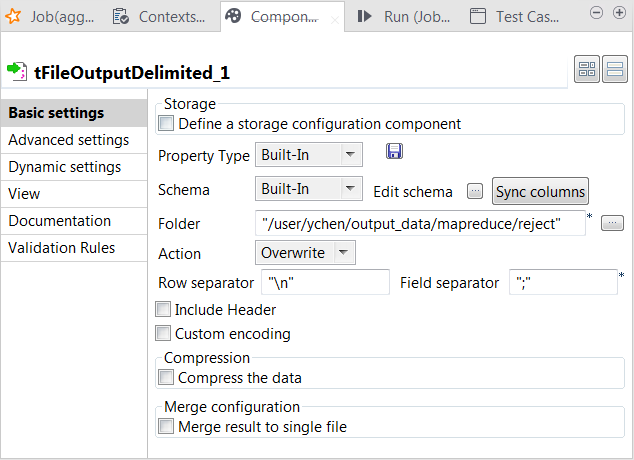
Double-click the other tFileOutputDelimited component which receives the reject link from tMap to
open its Component view.
-
In the Run view, click the Spark configuration tab to verify that the Hadoop/Spark connection metadata
has been properly inherited from the original Job.
You always need to use this Spark Configuration tab to define the connection to a given Hadoop/Spark distribution for the whole Spark Batch Job and this connection is effective on a per-Job basis.
Results
The Run view is automatically opened in the lower part of the Studio and shows the execution progress of this Job.
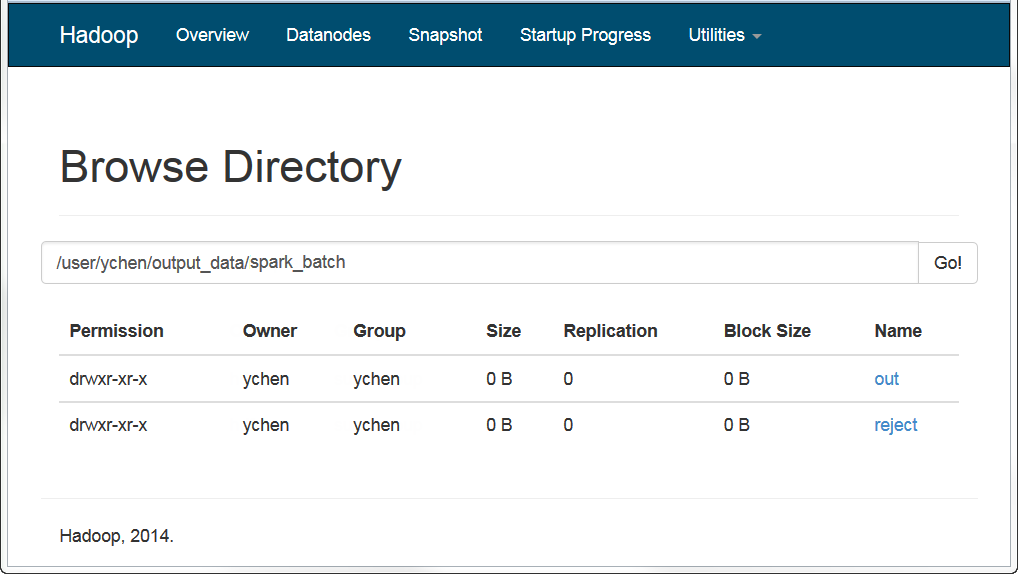
Once done, you can check, for example in the web console of your HDFS system, that the output has been written in HDFS.