Modifier le Job converti
Vous pouvez mettre à jour les composants, si nécessaire, pour finaliser un processus de transformation de données dans le framework Spark Streaming.
Un cluster Kafka est utilisé au lieu du système DBFS afin de fournir les données relatives au streaming de films au Job. Les données des cinéastes sont ingérées depuis DBFS dans le flux Lookup.
Avant de commencer
-
Le cluster Databricks à utiliser a été correctement configuré et est en cours de fonctionnement.
-
L'administrateur du cluster doit avoir donné les droits d'accès en lecture/écriture à l'utilisateur ou l'utilisatrice accédant aux données et répertoires dans DBFS et dans le système de stockage Azure ADLS Gen2.
Procédure
-
Dans le Repository, double-cliquez sur le Job aggregate_movie_director_spark_streaming pour l'ouvrir dans l'espace de modélisation graphique.
L'icône
 indique que les composants utilisés dans le Job original n'existent pas dans le framework du Job courant, Spark Streaming. Dans cet exemple, les composants manquants sont le tHDFSInput et le tHDFSOutput.
indique que les composants utilisés dans le Job original n'existent pas dans le framework du Job courant, Spark Streaming. Dans cet exemple, les composants manquants sont le tHDFSInput et le tHDFSOutput. -
Cliquez-droit sur le tMap et, dans le menu contextuel, sélectionnez Row > out1, puis cliquez sur le nouveau tFileOutputDelimited afin de relier tMap à ce composant.
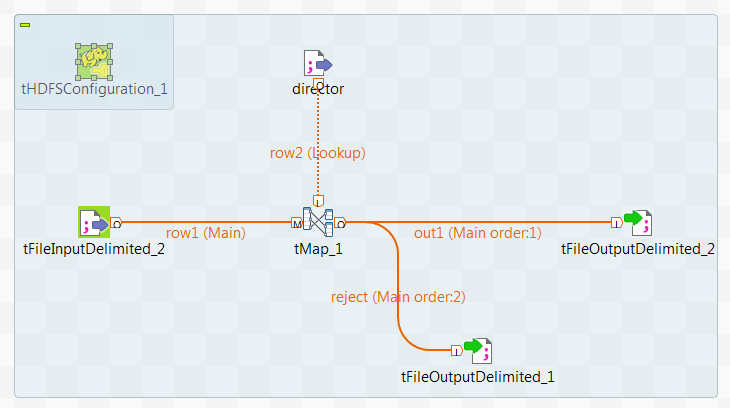
-
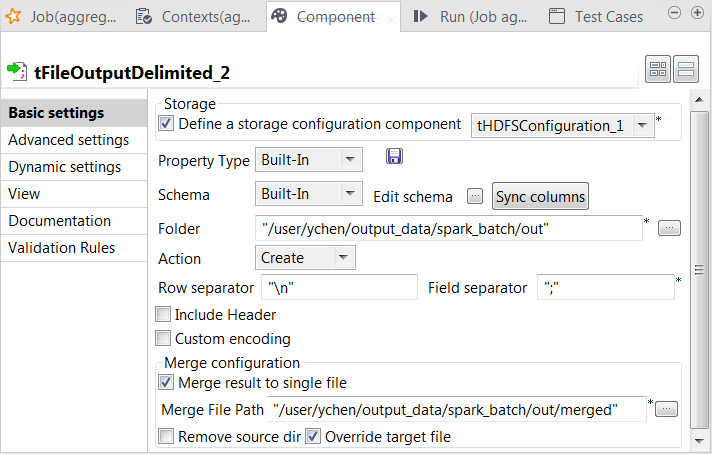
Double-cliquez sur le nouveau tFileOutputDelimited pour ouvrir sa vue Component.
-
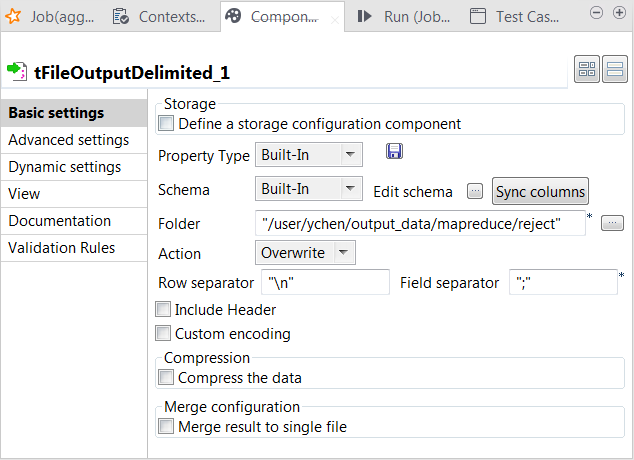
Double-cliquez sur l'autre tFileOutputDelimited recevant le lien reject du tMap pour ouvrir sa vue Component.
-
Dans la vue Run, cliquez sur l'onglet Spark configuration afin de vérifier que les métadonnées de connexion à Hadoop/Spark ont bien été héritées du Job original.
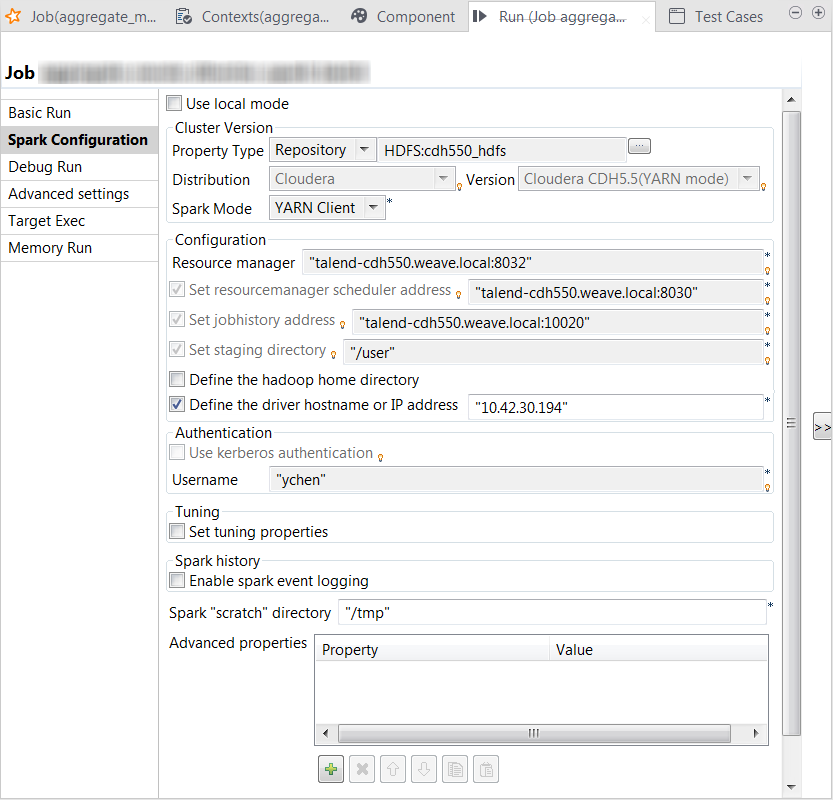
Vous devez toujours utiliser l'onglet Spark Configuration pour définir la connexion à une distribution Hadoop/Spark donnée pour le Job complet Spark Batch. Cette connexion est effective uniquement pour le Job dans lequel elle est définie.
Résultats
La vue Run s'ouvre automatiquement dans la partie inférieure du Studio et affiche l'avancement de l'exécution du Job.
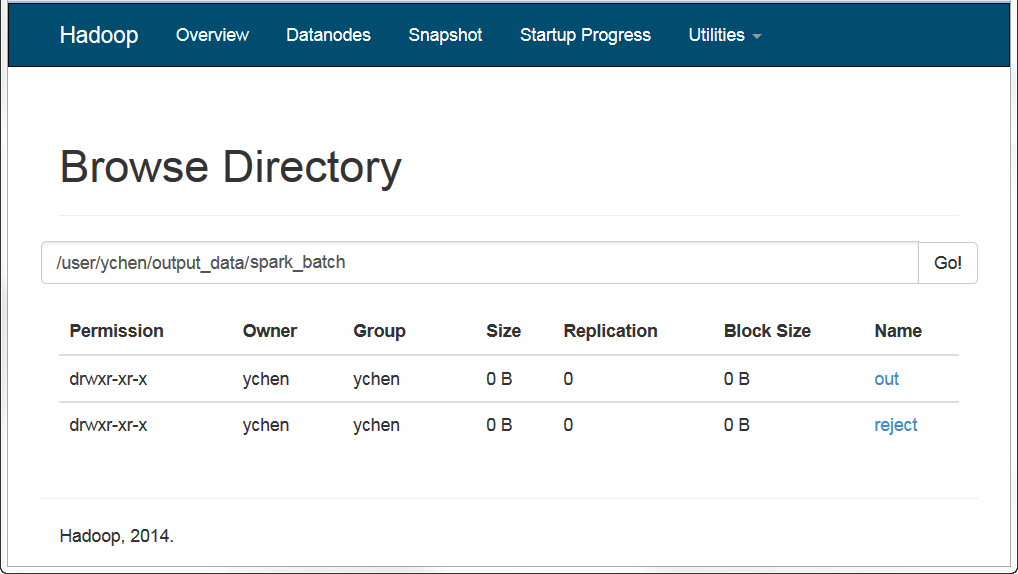
Cela fait, vous pouvez vérifier, par exemple, dans la console Web de votre système HDFS, que la sortie a bien été écrite dans HDFS.