编辑已转换的作业
更新组件以完成在 Spark Streaming 框架中运行的数据转换流程。
使用 Kafka 集群而非 DBFS 系统,将流式处理影片数据提供给作业。在查找流中,仍然从 DBFS 提取导演数据。
开始之前
-
要使用的 Databricks 集群已正确配置,并且正在运行。
-
集群管理员已经为用户名提供读取/写入权限,使其能够访问 DBFS 和 Azure ADLS Gen2 存储系统中的相关数据和目录。
步骤
-
在 Repository (存储库) 中,双击 aggregate_movie_director_spark_streaming 作业以在工作区中将其打开。
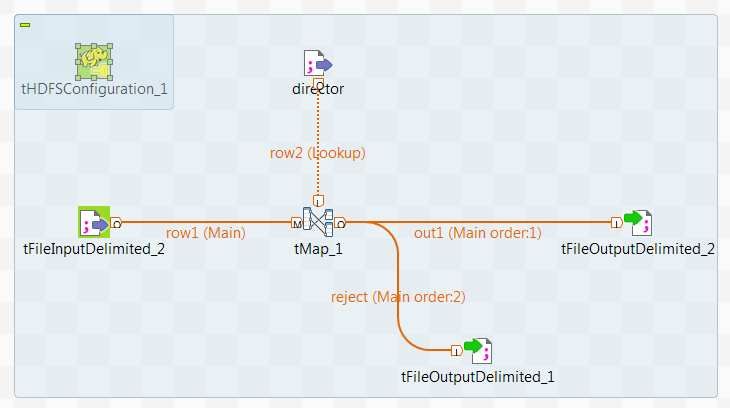
 图标表示当前的作业框架 Spark Batch 中不存在原始作业中所用的组件。在本示例中,是 tHDFSInput 和 tHDFSOutput。
图标表示当前的作业框架 Spark Batch 中不存在原始作业中所用的组件。在本示例中,是 tHDFSInput 和 tHDFSOutput。 -
右键单击 tMap,然后从上下文菜单中选择 Row (行) > out1 并单击新的 tFileOutputDelimited 将 tMap 连接到此组件。
-
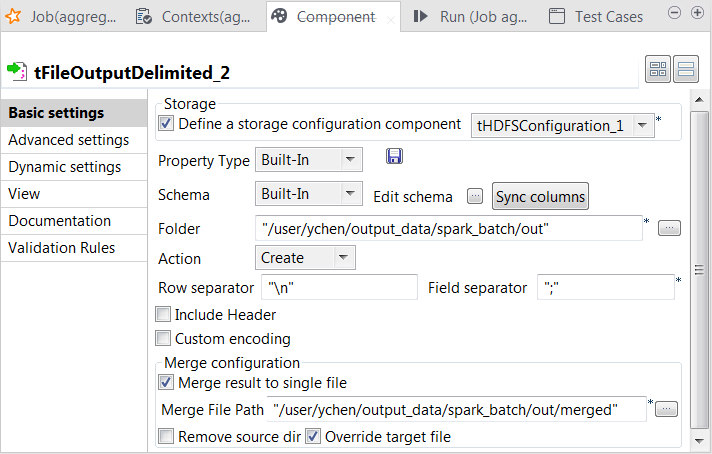
双击新的 tFileOutputDelimited 组件打开其 Component (组件) 视图。
-
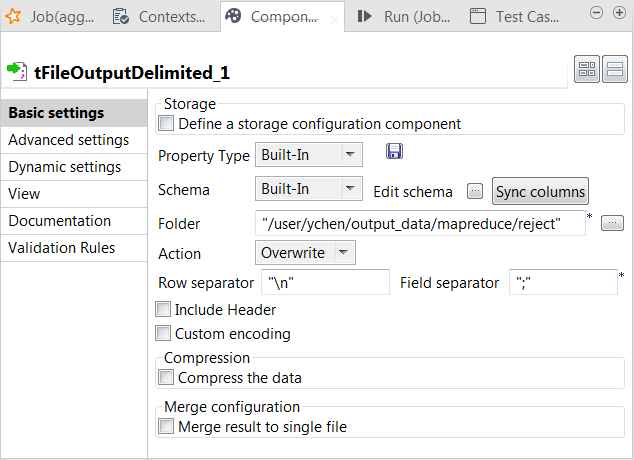
双击另一个从 tMap 接收 reject (拒绝) 连接的 tFileOutputDelimited 组件,打开其 Component (组件) 视图。
-
在 Run (运行) 视图中,单击 Spark configuration (Spark 配置) 选项卡以验证是否已从原始作业正确继承 Hadoop/Spark 连接元数据。
您始终需要使用此 Spark Configuration (Spark 配置) 选项卡为整个 Spark Batch 作业定义与给定 Hadoop/Spark 发行版的连接,此连接在作业范围内生效。
结果
Run (运行) 视图将在 Studio 的下半部分自动打开,并显示此作业的执行进度。
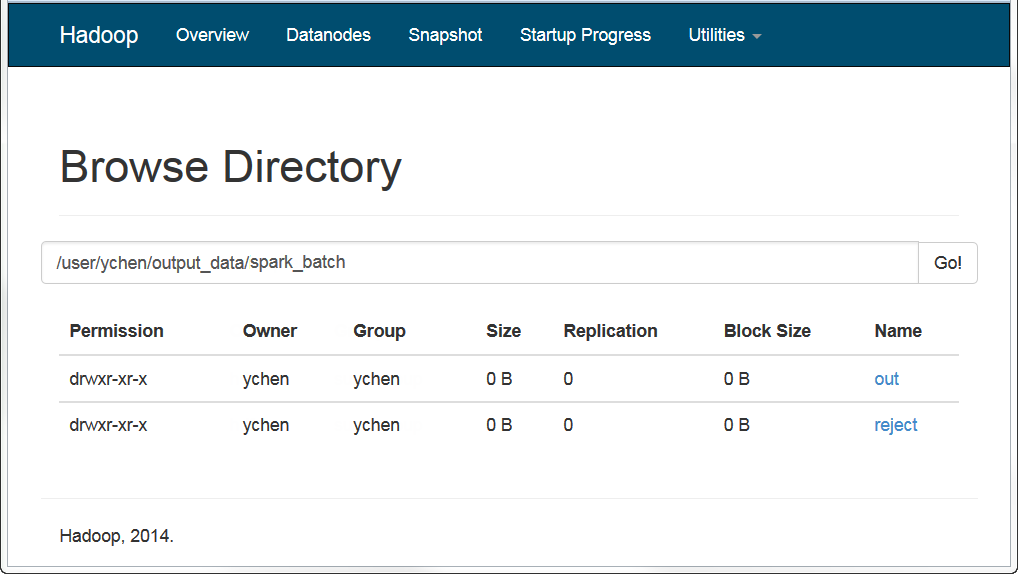
完成后,您可以检查 (例如在 HDFS 系统的 Web 控制台中) 输出是否已被写入了 HDFS 中。