
ビッグデータジョブの来歴を有効化
Cloudera Navigatorを使ってデータ来歴を設定
Cloudera Navigatorのサポートが Sparkジョブで利用可能になりました。
ジョブの実行にCloudera V5.5+を使用している場合は、Cloudera Navigatorを利用して特定のデータフローの来歴をトレースし、このジョブに使用されているコンポーネントおよびコンポーネント間のスキーマの変更を含め、このデータがSparkジョブによってどう生成されたかを確認できます。
CDP Private Cloud BaseやCDP Public Cloudを使ってジョブを実行する場合はApache Atlasのご使用をお勧めします。CDPダイナミックディストリビューションを使用している場合は、Cloudera NavigatorではなくApache Atlasが使われます。詳細は、Atlasを使ったデータ来歴の設定をご覧ください。
たとえば、以下のジョブをデザインし、それに関する来歴情報を生成するとします。
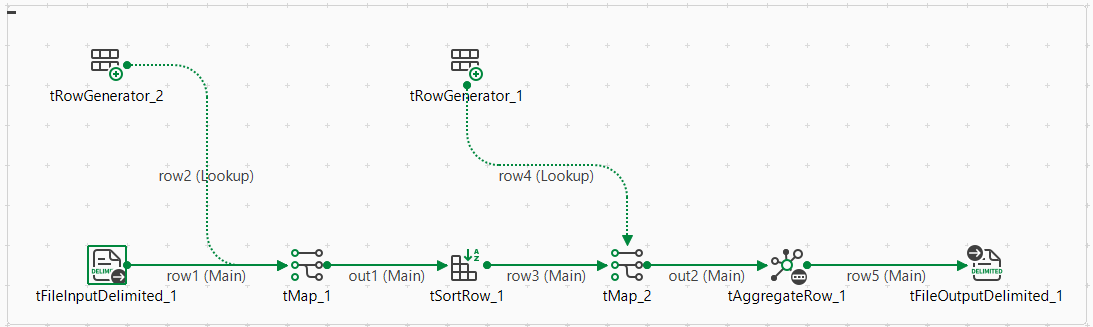
- [Run] (実行)をクリックしてビューを開き、[Hadoop configuration] (Hadoopの設定)タブをクリックします。Sparkジョブの場合、使用するタブは[Spark configuration] (Spark設定)です。
- [Distribution] (ディストリビューション)リストからClouderaを選択し、[Version] (バージョン)リストからCloudera 5.5を選択します。[Use Cloudera Navigator] (Cloudera Navigatorの使用)チェックボックスが表示されます。
- [Kill the job if Cloudera Navigator fails] (Cloudera Navigatorにエラーが発生したらジョブを強制終了): このチェックボックスをオンにすると、Cloudera Navigatorへの接続が失敗した時にジョブの実行が停止されます。それ以外の場合は、解除してジョブが実行を継続できるようにしてください。
この時点までに、Cloudera Navigatorへの接続がセットアップ済みとなっています。このジョブを実行する時は、Cloudera Navigator内に来歴が自動的に生成されています。ジョブを正しく実行するためには、[Spark configuration] (Spark設定)タブでさらにその他のパラメーターを設定する必要があります。
ジョブの実行が完了したら、このジョブによって書かれたデータをCloudera Navigatorで検索し、Cloudera Navigatorでこのデータの来歴を確認します。この来歴グラフを内のジョブと比較すると、すべてのコンポーネントがこのグラフに表示されていることが確認できます。また、各コンポーネントのアイコンを展開し、使用されているスキーマを読むことができます。

でサポートされているCloudera Navigatorバージョンの詳細は、Talendジョブの対応Cloudera Navigatorバージョンをご覧ください。
Atlasを使ってデータ来歴を設定
Apache Atlasのサポートが Sparkジョブで利用可能になりました。
ジョブの実行にHortonworks Data Platform V2.4以降を使用しており、HortonworksクラスターにApache Atlasがインストールされている場合は、Atlasを利用して特定のデータフローの来歴をトレースし、このジョブに使用されているコンポーネントおよびコンポーネント間のスキーマの変更を含め、このデータがSparkジョブによってどう生成されたかを確認できます。
CDP Private Cloud BaseまたはCDP Public Cloudを使ってジョブを実行しており、Apache Atlasがクラスターにインストールされている場合は、[Spark Configuration] (Spark設定)でSpark Universal 3.3.x (推奨)またはCloudera CDP 7.x (組み込み)を使ってAtlasを利用することもできます。
たとえば以下のSpark Batchジョブをデザインし、そこでAtlas内にそれに関する来歴情報を生成するとします。
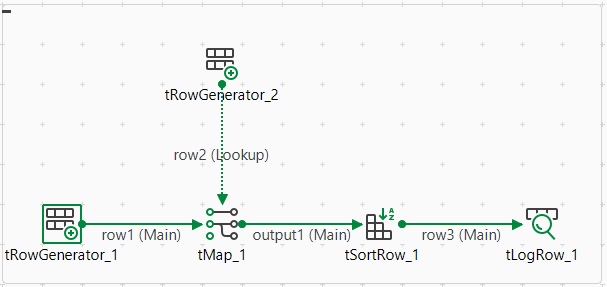
このジョブでは、入力データの生成にtRowGeneratorを使用し、データ処理にtMapとtSortRowを使用し、データを別の形式に出力するのに他のコンポーネントを使用します。
- [Run] (実行)をクリックしてビューを開き、[Spark configuration] (Spark設定)タブをクリックします。
- [Distribution] (ディストリビューション)リストと[Version] (バージョン)リストからHortonworksディストリビューションを選択します。[Use Atlas] (Atlasを使用)チェックボックスが表示されます。
- [Die on error] (エラー発生時に強制終了): Atlasへの接続の問題など、Atlas関連の問題が発生した場合にジョブの実行を停止する場合は、このチェックボックスをオンにします。それ以外の場合は、解除してジョブが実行を継続できるようにしてください。
この時点までに、Atlasへの接続がセットアップ済みとなっています。このジョブを実行する時は、Atlas内に来歴が自動的に生成されています。ジョブを正しく実行するためには、[Spark configuration] (Spark設定)タブでさらにその他のパラメーターを設定する必要があります。詳細は、Spark Batchジョブを作成をご覧ください。
ジョブの実行が完了したら、このジョブによって書かれた来歴情報をAtlasで検索し、そこで来歴を読みます。
Atlas来歴を読み取り
-
-
ジョブ自体。
-
tRowGeneratorまたはtSortRowなど、データスキーマを使用するジョブ内のコンポーネント。tHDFSConfigurationなどの接続または設定コンポーネントはスキーマを使用しないため、これらは考慮されません。
-
-
Talend: ジョブによって生成されたすべてのエンティティに。
-
TalendComponent: すべてのコンポーネントエンティティに。
-
TalendJob: すべてのジョブエンティティに。
Atlasでこれらのタグの1つを直接クリックすれば、対応するエンティティが表示されます。
