
Atlasを使ってデータ来歴を設定
Apache Atlasに対するサポートがTalend Sparkジョブに追加されました。
ジョブの実行にHortonworks Data Platform V2.4以降を使用しており、HortonworksクラスターにApache Atlasがインストールされている場合は、Atlasを利用して特定のデータフローの来歴をトレースし、このジョブに使用されているコンポーネントおよびコンポーネント間のスキーマの変更を含め、このデータがSparkジョブによってどう生成されたかを確認できます。
Hortonworks Data Platform V2.4をお使いの場合、StudioはAtlas 0.5のみをサポートします。Hortonworks Data Platform.V2.5をお使いの場合、StudioはAtlas 0.7のみをサポートします。
たとえば以下のSpark Batchジョブをデザインし、そこでAtlas内にそれに関する来歴情報を生成するとします。
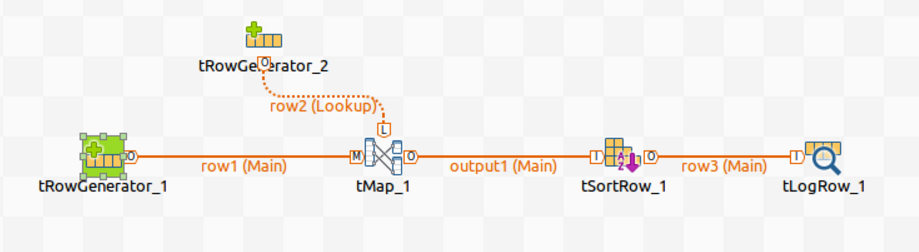
このジョブでは、入力データの生成にtRowGeneratorを使用し、データ処理にtMapとtSortRowを使用し、データを別の形式に出力するのに他のコンポーネントを使用します。
手順
タスクの結果
この時点までに、Atlasへの接続がセットアップ済みとなっています。このジョブを実行する時は、Atlas内に来歴が自動的に生成されています。
ジョブを正しく実行するには、[Spark configuration] (Spark設定)タブでさらにその他のパラメーターを設定する必要があります。詳細は、Studioの入門ガイドでSpark Batchジョブの例をご覧ください。
ジョブの実行が完了したら、このジョブによって書かれた来歴情報をAtlasで検索し、そこで来歴を読みます。