
Big Data
|
機能 |
説明 |
対象製品 |
|---|---|---|
| Spark Universal 3.4.xでスタンドアロンモードをサポート | [Standalone] (スタンドアロン)モードのSpark 3.4.xで、Spark Universalを使ってSpark BatchジョブとSpark Streamingジョブを実行できるようになりました。Sparkジョブの[Spark configuration] (Spark設定)ビューまたは[Hadoop Cluster Connection] (Hadoopクラスター接続)メタデータウィザードのどちらかで設定できます。 このモードを選択すると、Talend StudioはSpark対応のカスタマイズ済みクラスターに接続してそのクラスターからジョブを実行します。 この機能の一般公開によって、HBaseがサポートされるようになりました。現在のところ、Hive、およびAvroコンポーネントが含まれるSparkジョブはサポートされていません。 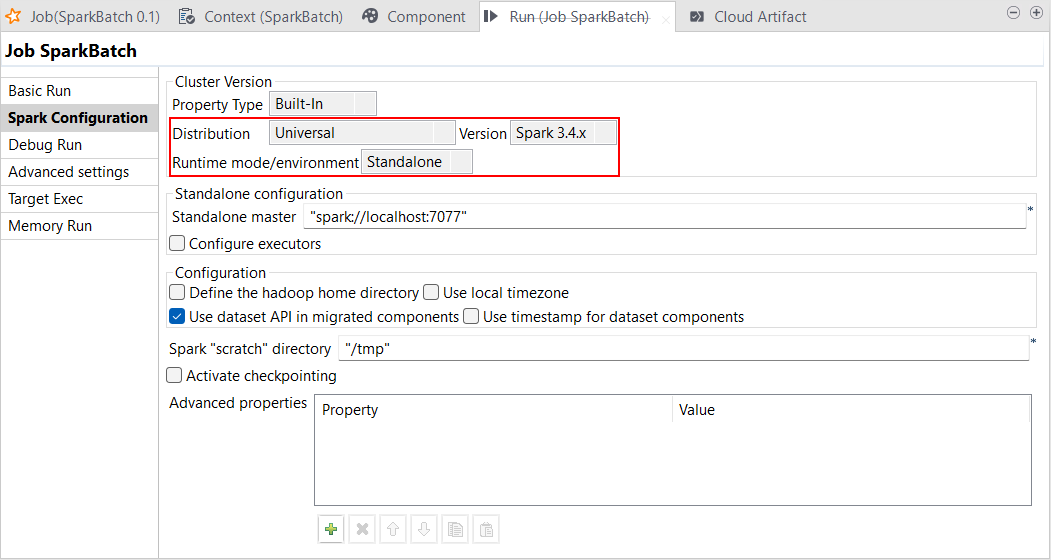 |
サブスクリプションベースであり、Big Dataを伴うTalendの全製品 |
| tHBaseTableで利用できる新しいオプション | tHBaseTableの[Basic settings] (基本設定)ビューで、次のパラメーターが新しく利用できるようになりました:
![tHBaseTableの基本設定ビューが開き、[ファミリーパラメーター]オプションと[リージョンキーを分割]オプションが強調表示されている状態。](/talend/ja-JP/release-notes/8.0/Content/Resources/images/thbasetable-r202312.png) |
サブスクリプションベースであり、Big Dataを伴うTalendの全製品 |
| Spark Universal 3.4.xでDatabricksランタイム13.xをサポート | Google Cloud Platform (GCP)、AWS、Azureで、Spark 3.4.xと共にSpark Universalを使い、Databricksのジョブクラスターと汎用クラスターでSpark BacthジョブやStreamingジョブを実行できるようになりました。Sparkジョブの[Spark configuration] (Spark設定)ビューまたは[Hadoop Cluster Connection] (Hadoopクラスター接続)メタデータウィザードのどちらかで設定できます。 このモードを選択すると、Talend StudioはDatabricks 13.xのバージョンと互換性を持つようになります。 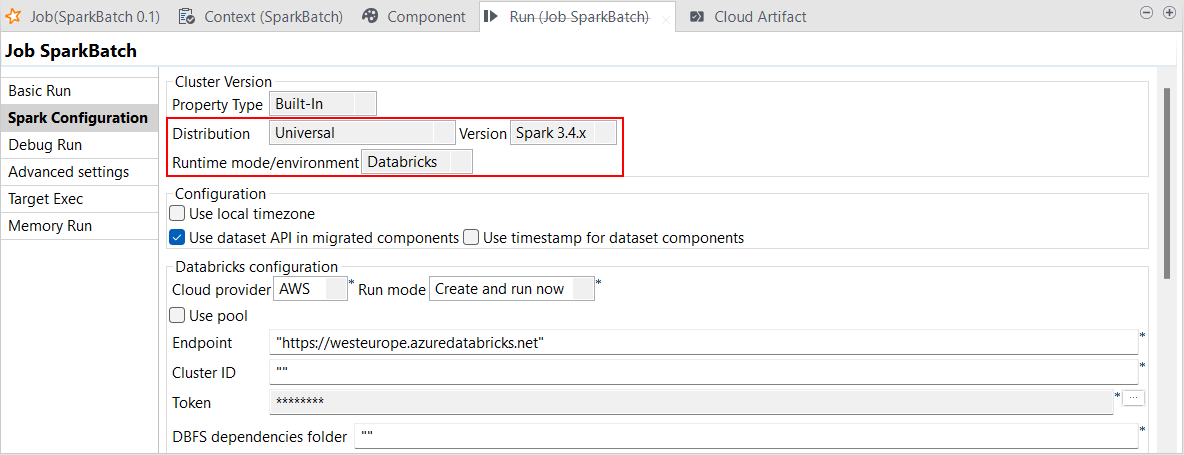 |
サブスクリプションベースであり、Big Dataを伴うTalendの全製品 |