
Big Data
|
Fonctionnalité |
Description |
Disponible dans |
|---|---|---|
| Support du mode Standalone avec Spark Universal 3.4.x | Vous pouvez à présent exécuter vos Jobs Spark et Spark Streaming à l'aide de Spark Universal avec Spark 3.4.x en mode Standalone. Vous pouvez la configurer dans la vue Spark Configuration (Configuration de Spark) de vos Jobs Spark ou dans l'assistant de métadonnées Hadoop Cluster Connection (Connexion au cluster Hadoop). Lorsque vous sélectionnez ce mode, le Studio Talend se connecte à un cluster personnalisé compatible Spark pour exécuter le Job depuis ce cluster. Avec la disponibilité générale de cette fonctionnalité, HBase est à présent supportée. Les Jobs Spark et Hive contenant des composants Avro ne sont pas supportés pour le moment. 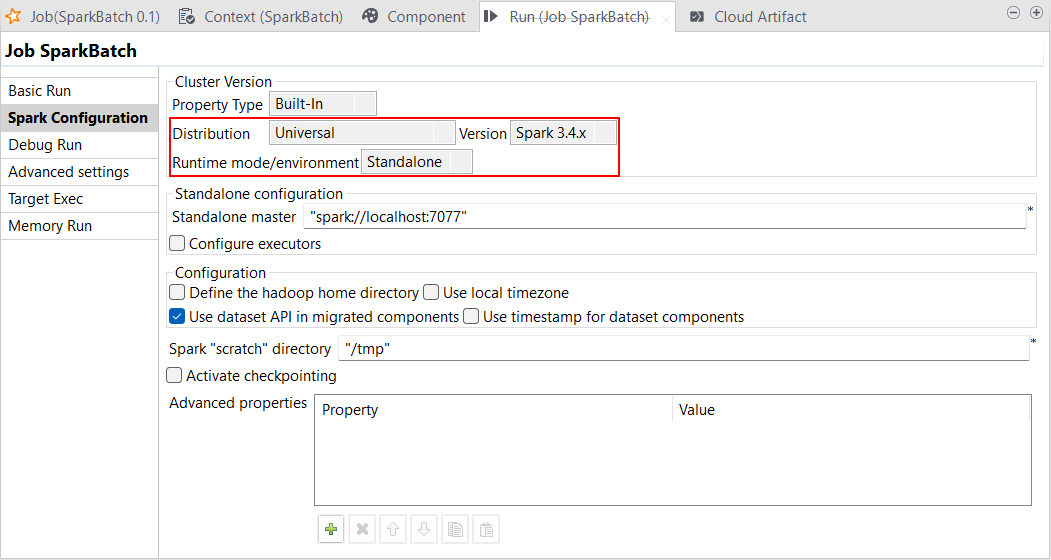 |
Tous les produits Talend avec Big Data nécessitant souscription |
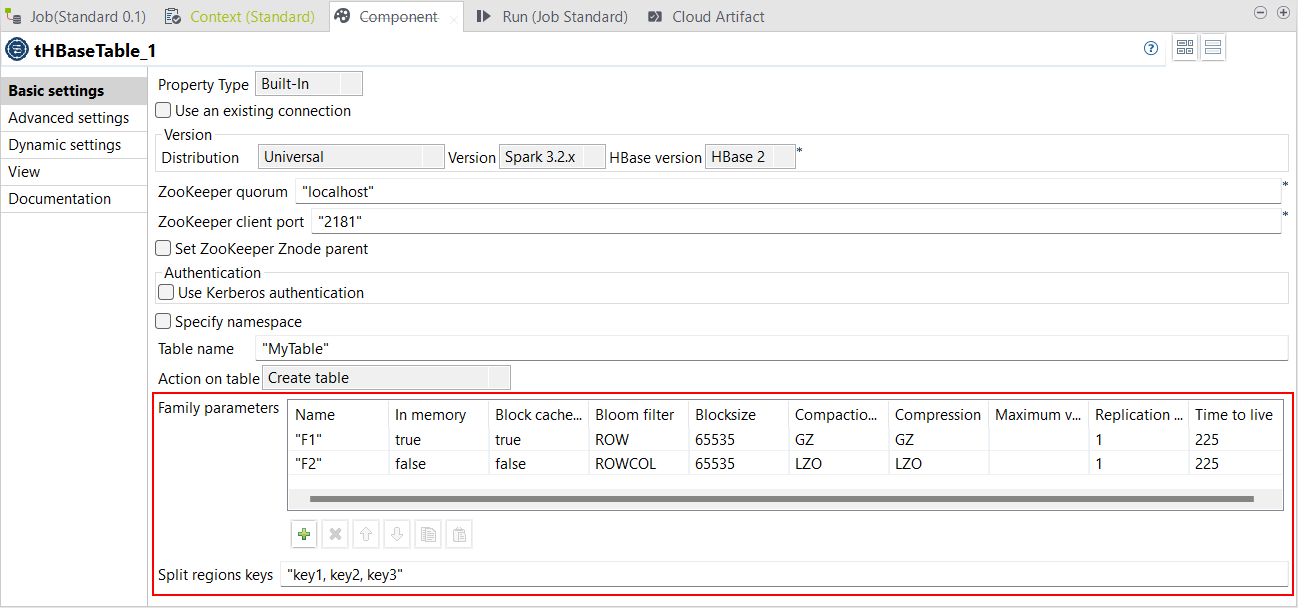
| Nouvelles options disponibles dans le tHBaseTable | De nouveaux paramètres sont disponibles dans la vue Basic settings (Paramètres simples) du composant tHBaseTable :
 |
Tous les produits Talend avec Big Data nécessitant souscription |
| Support du Runtime Databricks 13.x avec Spark Universal 3.4.x | Vous pouvez à présent exécuter vos Jobs Spark Batch et Streaming sur des clusters de jobs et des clusters universels Databricks sur Google Cloud Platform (GCP), AWS et Azure, à l'aide de Spark Universal avec Spark 3.4.x. Vous pouvez la configurer dans la vue Spark Configuration (Configuration de Spark) de vos Jobs Spark ou dans l'assistant de métadonnées Hadoop Cluster Connection (Connexion au cluster Hadoop). Lorsque vous sélectionnez ce mode, le Studio Talend est compatible avec la version 13.x de Databricks. 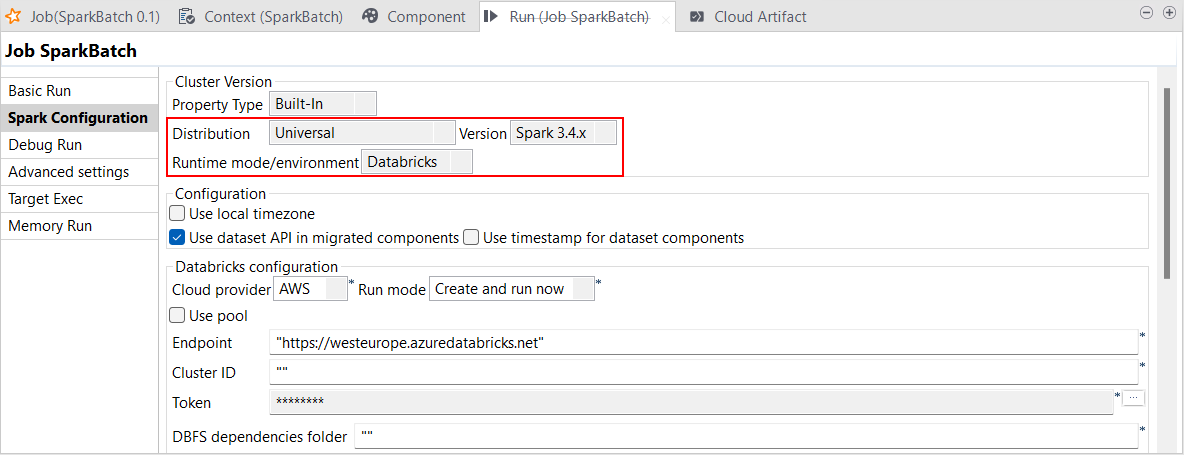 |
Tous les produits Talend avec Big Data nécessitant souscription |