
Setting up data lineage with Atlas
The support for Apache Atlas has been added to Talend Spark Jobs.
If you are using Hortonworks Data Platform V2.4 onwards to run your Jobs and Apache Atlas has been installed in your Hortonworks cluster, you can make use of Atlas to trace the lineage of given data flow to discover how this data was generated by a Spark Job, including the components used in this Job and the schema changes between the components. If you are using CDP Private Cloud Base or CDP Public Cloud to run your Jobs and Apache Atlas has been installed in your cluster, you can also make use of Atlas.
If you are using CDP dynamic distribution, the Use Atlas check box replaces the Use Cloudera Navigator check box when you have installed the 8.0.1-R2023-06 Talend Studio Monthly release or a later one delivered by Talend.
- Hortonworks Data Platform V2.4, the Talend Studio supports Atlas 0.5 only.
- Hortonworks Data Platform V2.5, the Talend Studio supports Atlas 0.7 only.
- Hortonworks Data Platform V3.14, the Talend Studio support Atlas 1.1 only.
For example, assume that you have designed the following Spark Batch Job and you want to generate lineage information about it in Atlas:
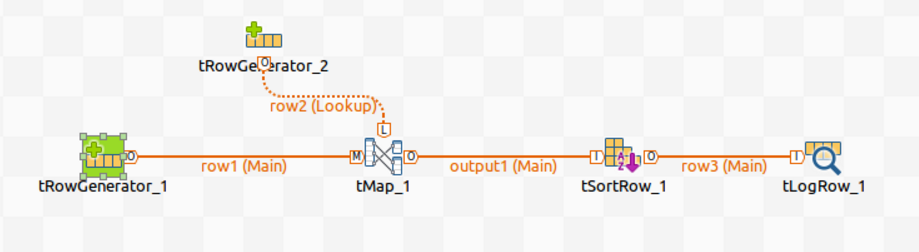
In this Job, tRowGenerator is used to generate the input data, tMap and tSortRow to process the data and the other components to output data into different formats.
Procedure
Results
Till now, the connection to Atlas has been set up. The time when you run this Job, the lineage will be automatically generated in Atlas.
Note that you still need to configure the other parameters in the Spark configuration tab in order to successfully run the Job. For further information, see Creating Spark Batch Jobs.
When the execution of the Job is done, perform a search in Atlas for the lineage information written by this Job and read the lineage there.