
Data Preparation: new features
| Feature | Description |
|---|---|
| Magic Fill | This new function allows you to define a pattern based
on a handful of examples, and via a machine learning algorithm, apply the
transformation on a whole column. The Magic Fill gives you many formatting
possibilities, on any data type.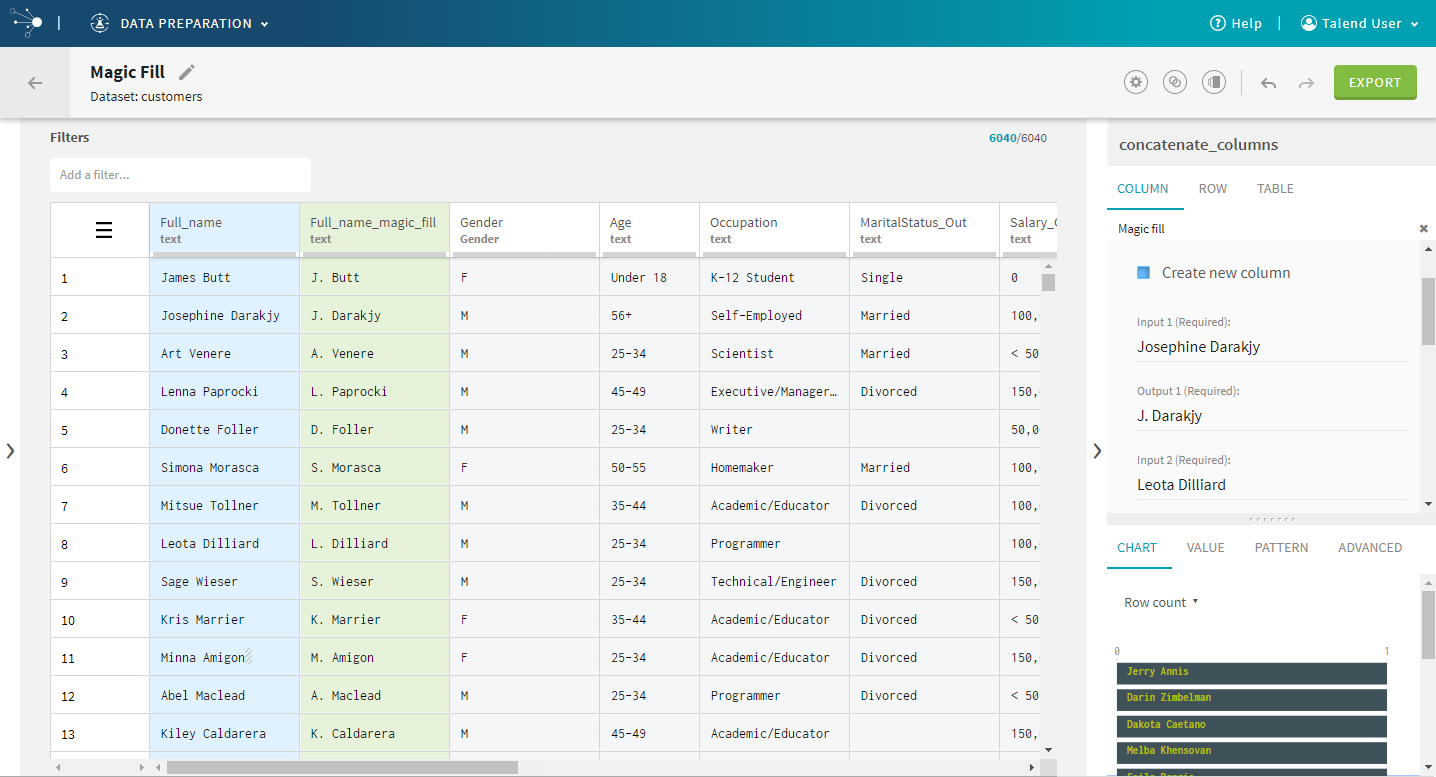
|
| Extract part of a name | It is now possible, by leveraging a machine-learning
model, to split a full name into its respective subparts such as title,
first name, middle name, last name, and suffix, thus increasing efficiency
for dataset cleansing and standardization.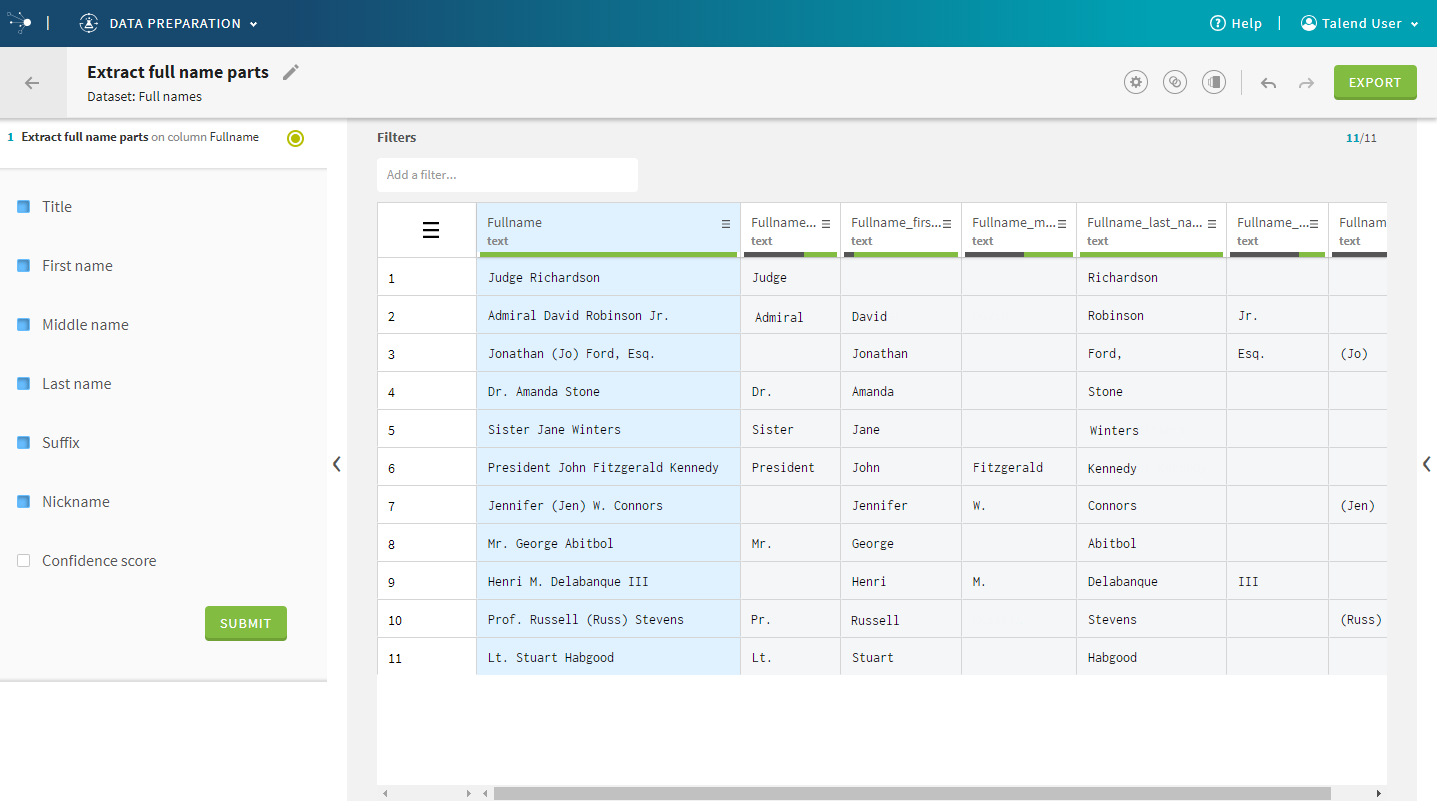
|
| Extract parts of a field based on semantic definitions | It is now possible, leveraging the definition of
semantic types, to extract various types of information contained in a
single cell, into individual columns, thus increasing efficiency for dataset
cleansing and standardization.
|
| Repeatable masking and compound semantic types masking | Data masking has been improved and can now handle
seeds, to offer repeatable masking. Which means that identical source values
will always be output as the same masked values. In addition, semantic masking can now be performed on compound semantic types, enhancing data privacy. 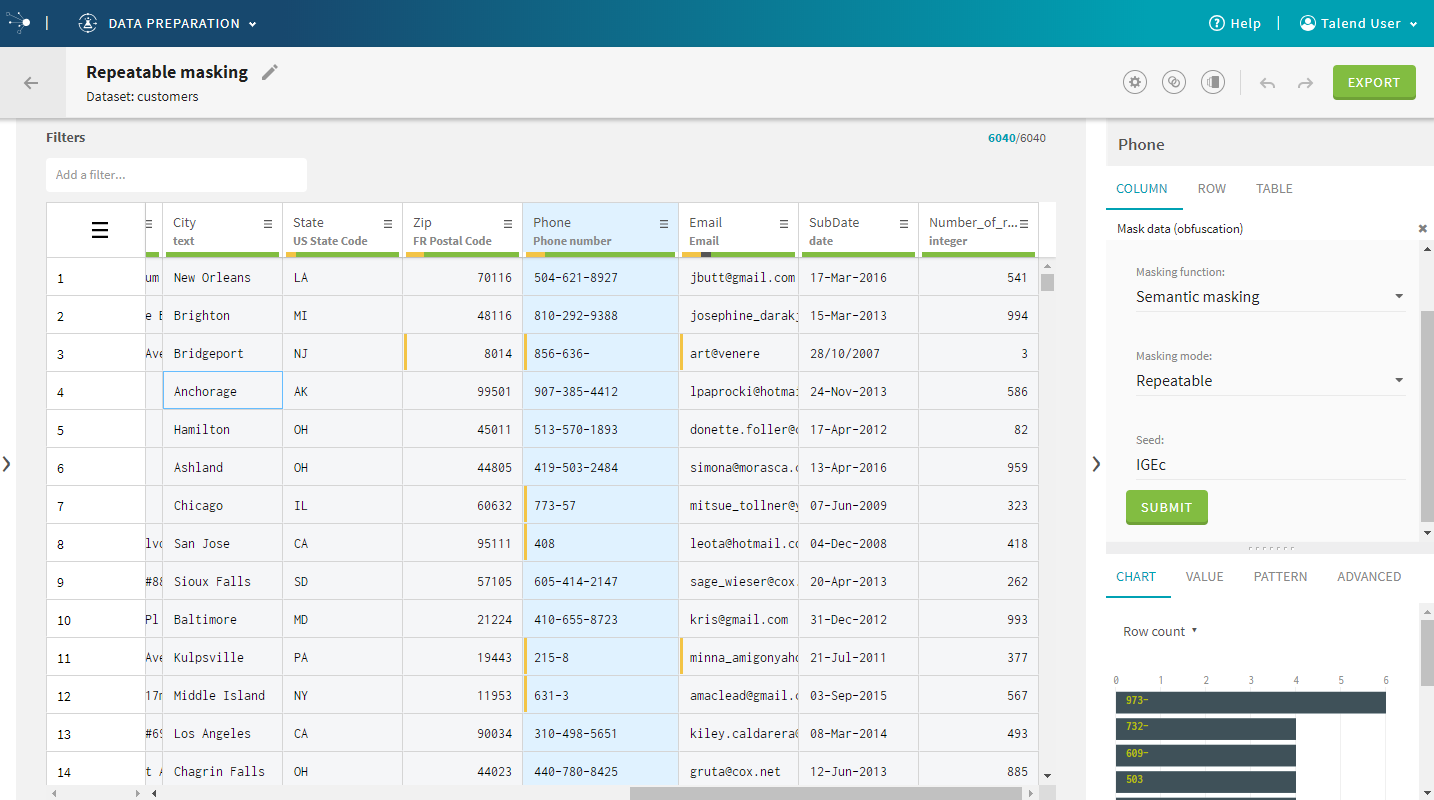
|
| Auto-completion | Editing a cell from a column which semantic type is
based on a dictionary is now easier than before, with the addition of
auto-completion. Choose from a list of suggested values to guarantee that
your data follows the standard of your semantic types.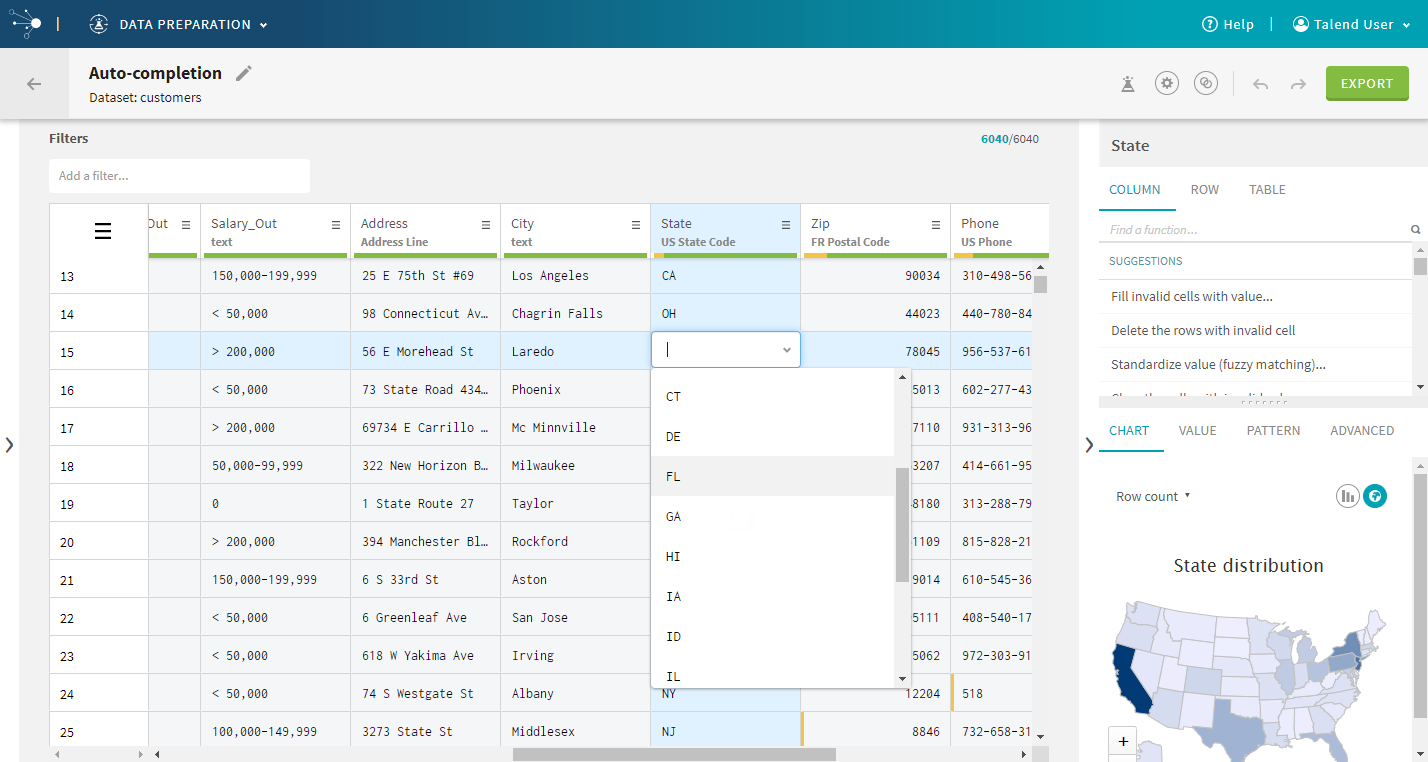
|
| Deduplication | In addition to the existing deduplication function that
can be applied on the whole table, you can now apply a deduplication
operation based on the values of one or more columns, giving you more
control on which rows you want to delete.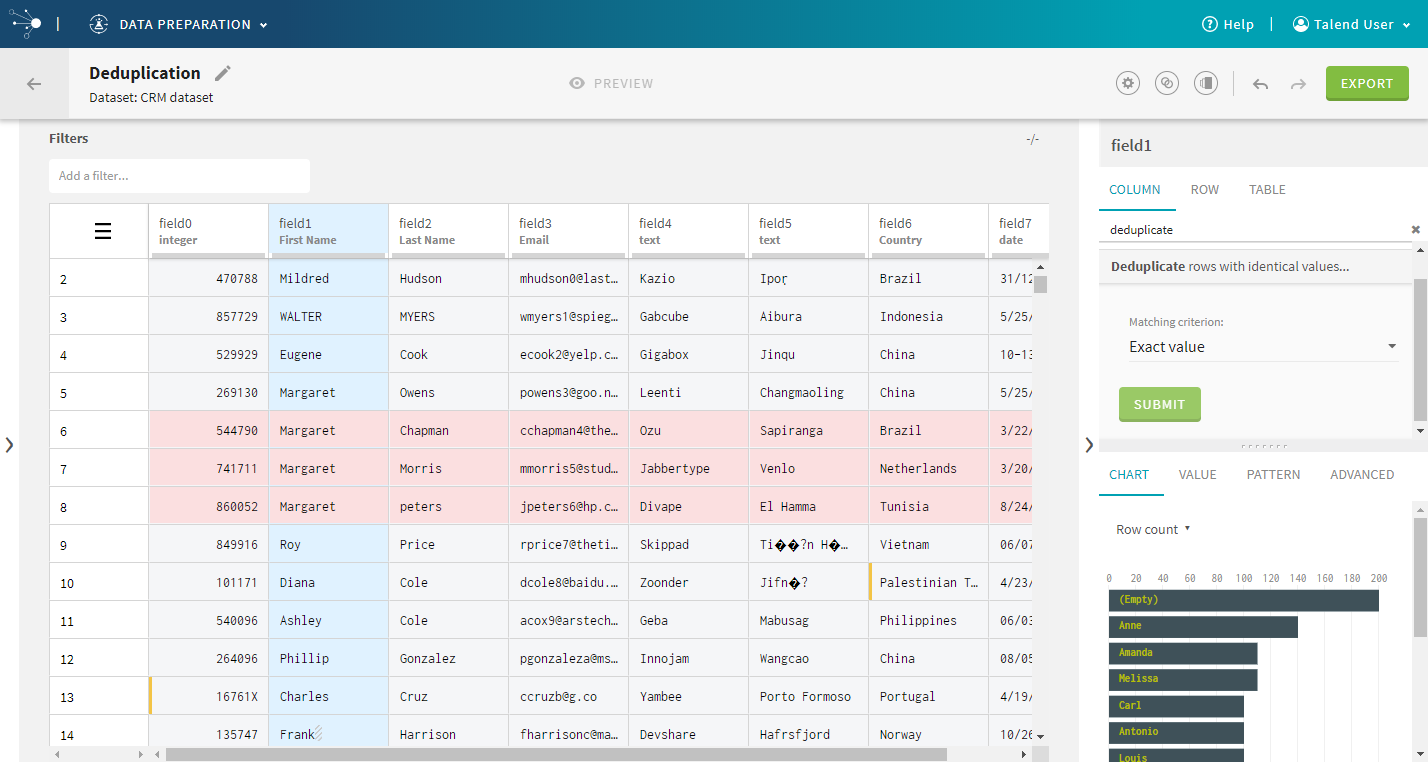
|
| Coalesce columns | This function can be used to easily retrieve the first
non null value across different columns to consolidate their data into a new
column.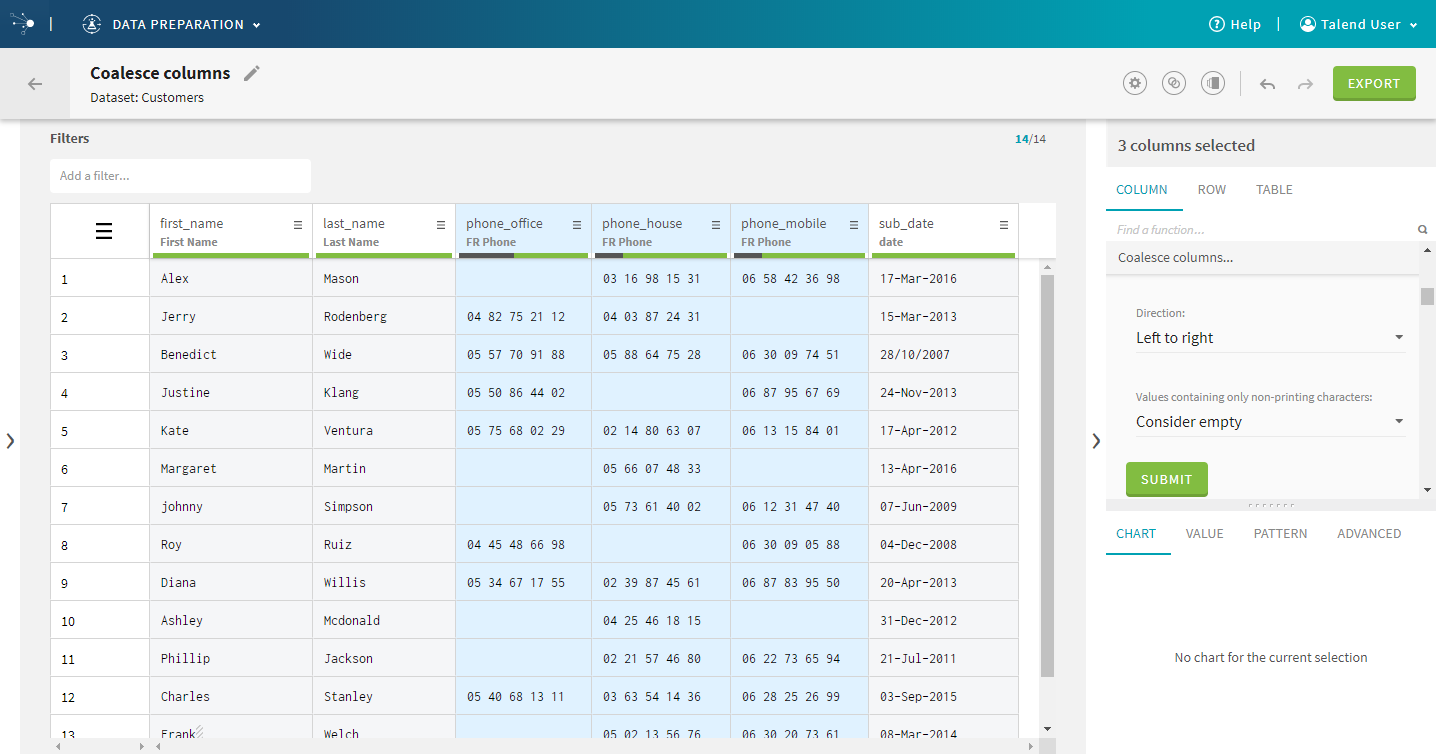
|
| Cross-column functions | The introduction of functions applicable to multiple
columns at once (such as concatenation and maths operations) brings improved
efficiency for dataset cleansing and standardization.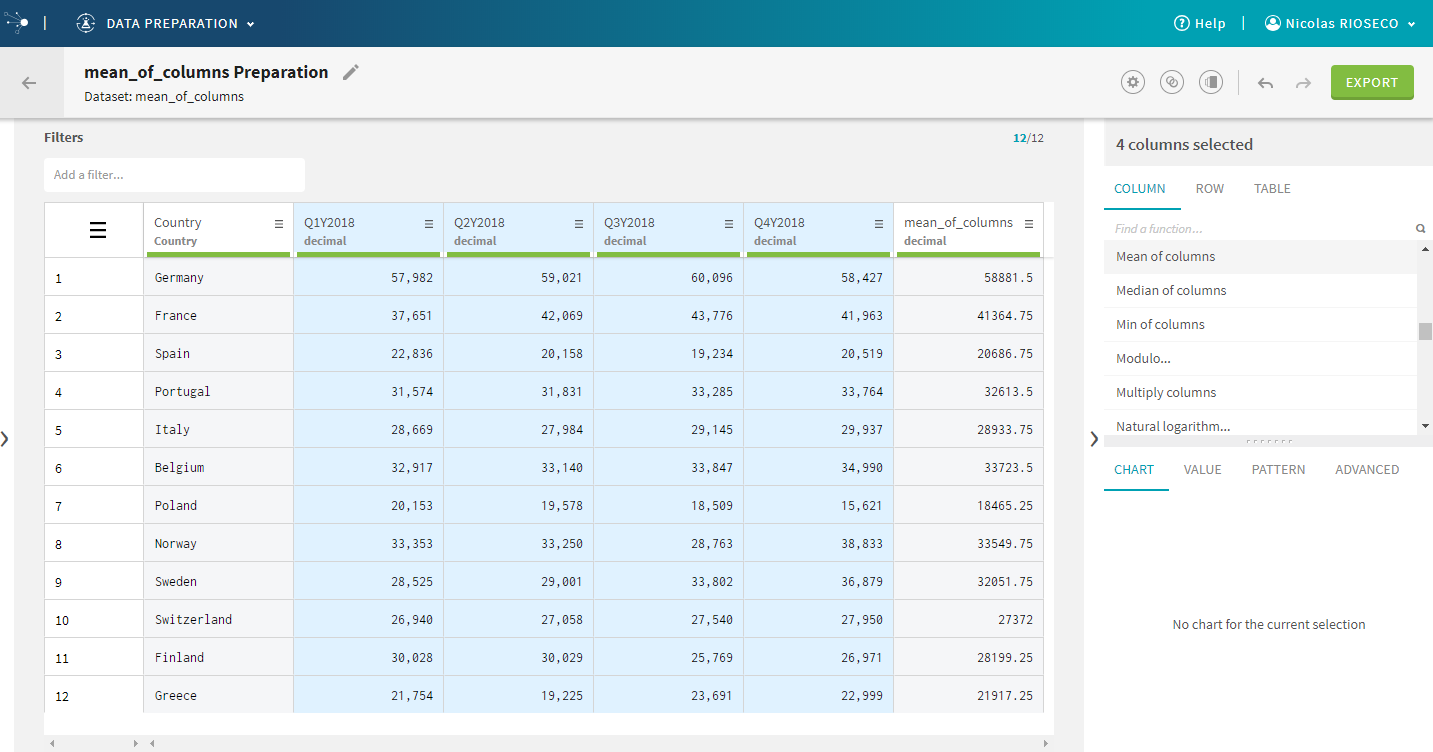
|
| Table functions | Some functions that were previously only available to
apply on columns, can now be used on the whole table in a single action,
making formatting operations even more efficient:
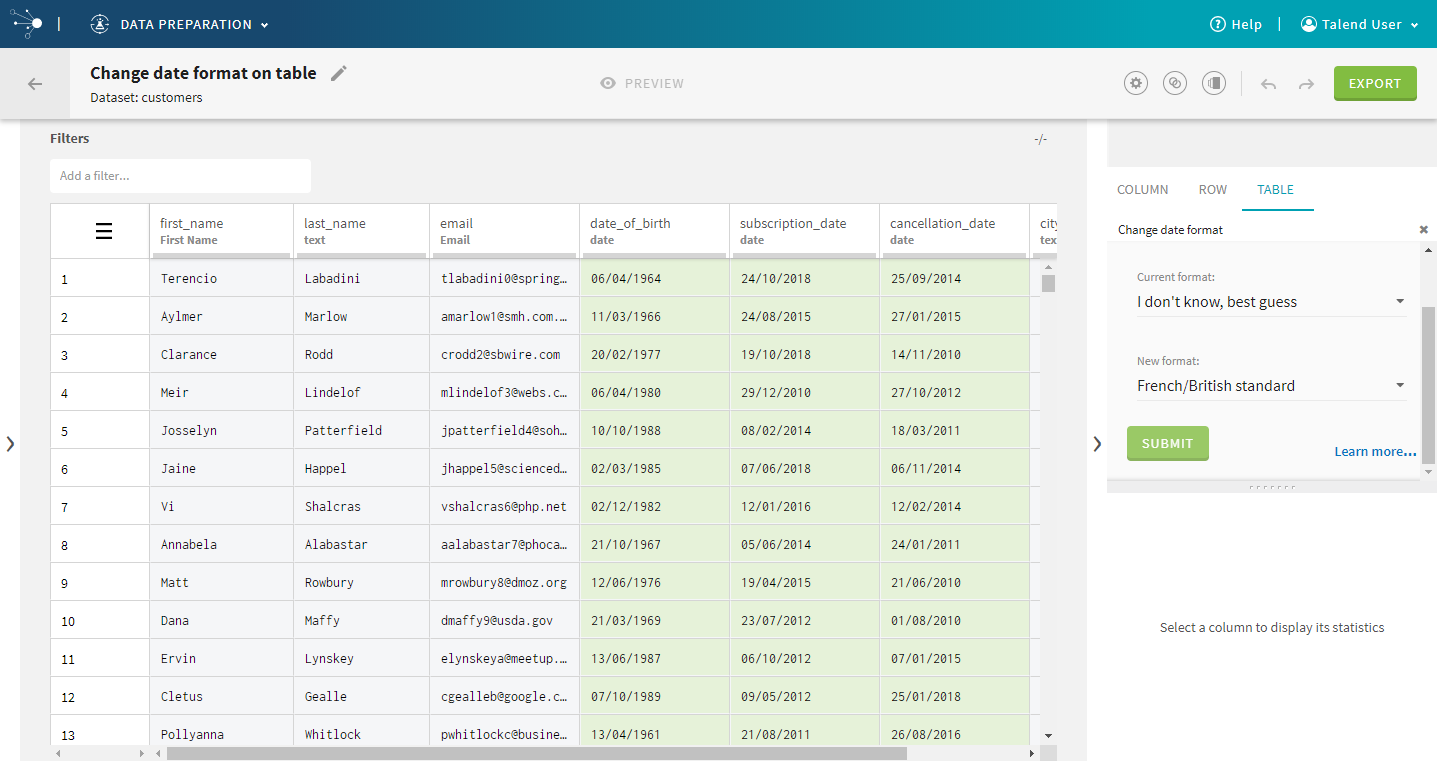
|
| Convert character width | You can now use this function to convert the character
width to half or full width, and even normalize strings in your
datasets.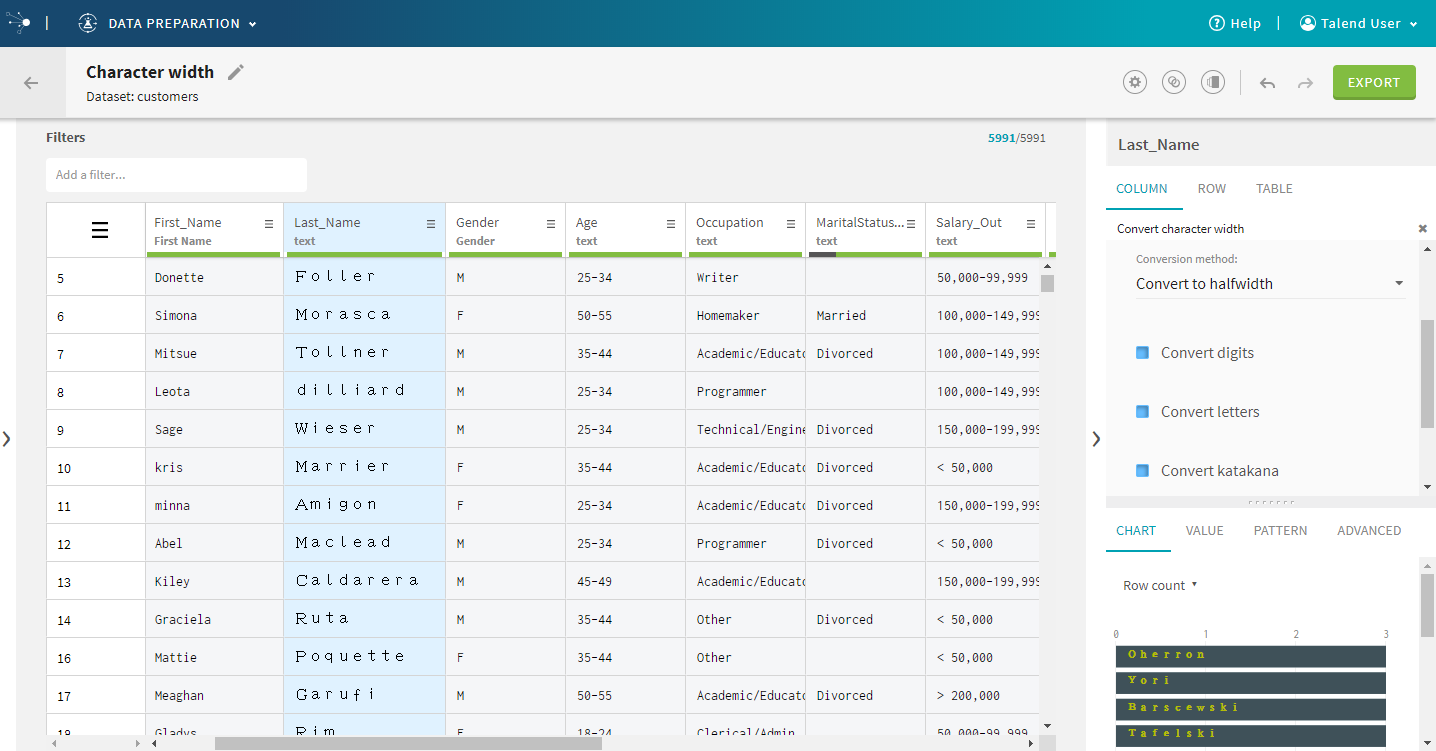
|
| New Japanese calendar | Date functions now take into account the latest
Japanese era, meaning that you can correctly convert dates to and from the
Japanese calendar.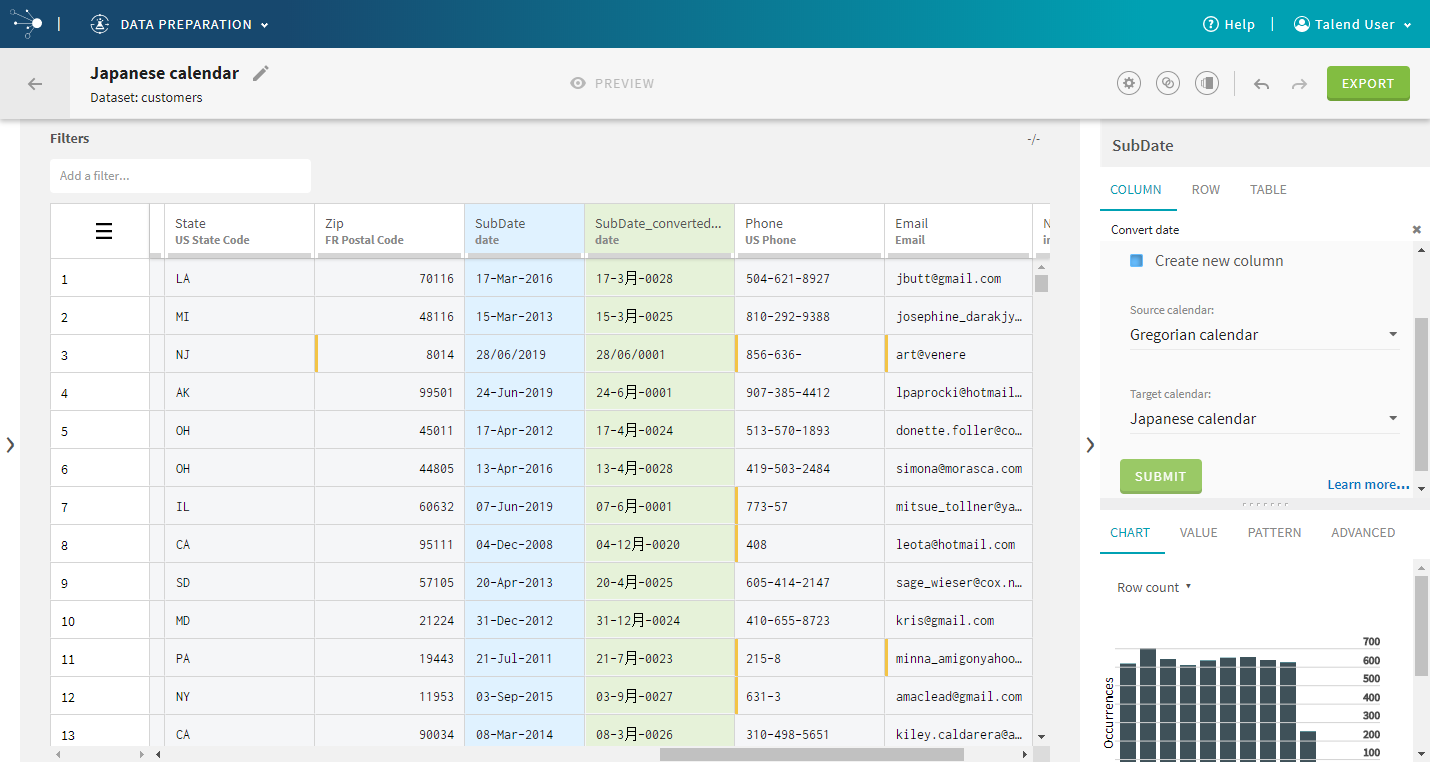
|