
Big Data: new features
Spark Job designer enhancements
|
Feature |
Description |
|---|---|
| Delta Lake | The tDeltaLakeInput and
tDeltaLakeOutput have been created to leverage this open-source storage
layer that brings ACID transactions to Big Data workloads on Apache
Spark.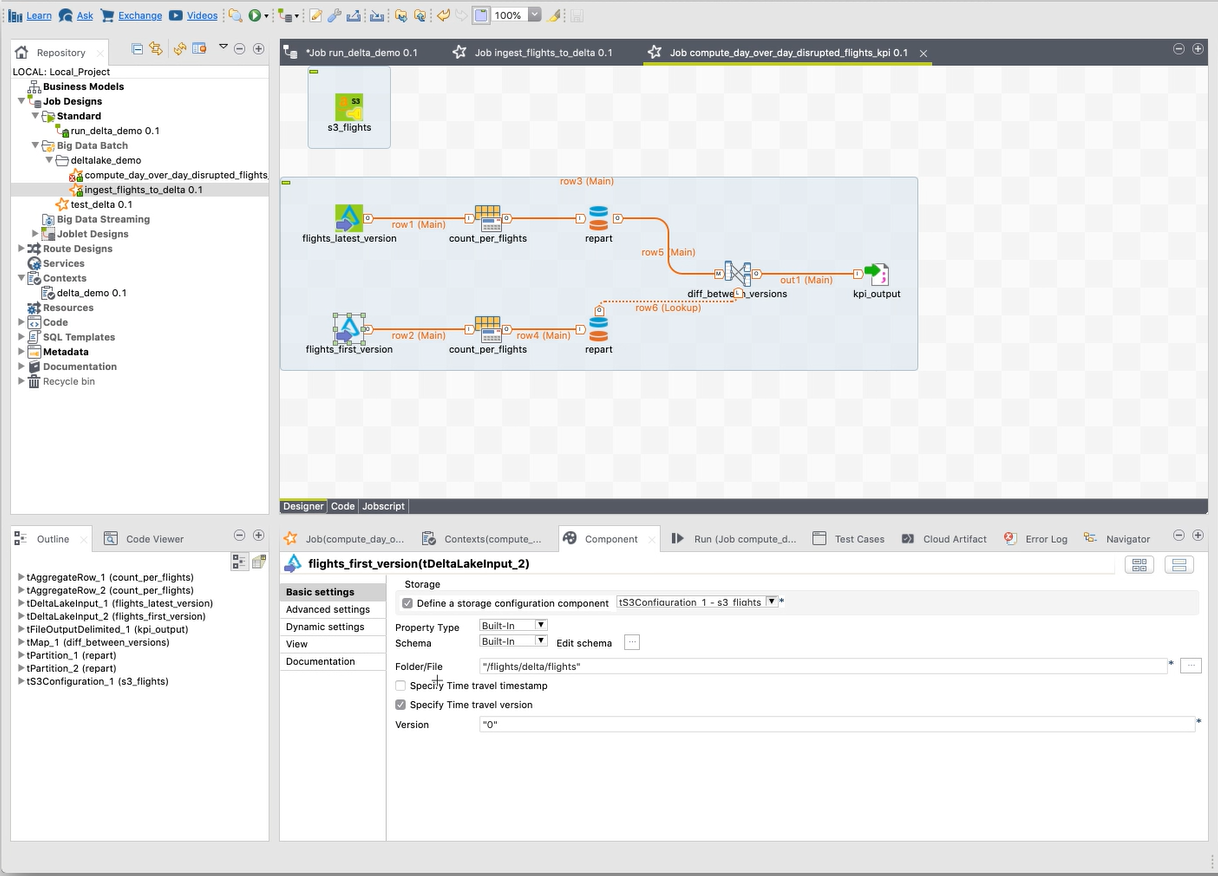
Information noteWarning: This feature is in technical preview
status.
|
| Apache Spark V2.4 | The new Aparch Spark version is supported in the Local mode and in the Spark Batch and Spark Streaming Jobs with Cloudera CDH V6.1. |
| Databricks |
|
| Snowflake | The Snowflake components for Spark Batch have been created. Information noteWarning: This feature is in technical preview
status.
|
| Elasticsearch | Elasticsearch V5.6.x and V6.4.x are supported. |
| Cloud security |
|
| tFileInputDelimited | Users can select a check box to enable the Spark cluster to use multiple executors to read large CSV files in parallel. |
Support for Big Data platforms
|
Feature |
Description |
|---|---|
| Cloudera |
|
| MapR | The support for MapR has been updated to MapR V6.1 with MEP (MapR Ecosystem Pack) V6.1 |
Other components
|
Feature |
Description |
|---|---|
| Google BigQuery |
|
| Couchbase API |
|
Continuous Integration and Deployment
|
Feature |
Description |
|---|---|
| Continuous Integration and Deployment: light CommandLine, light installation |
The installation of Talend CommandLine is no longer required as the repository that contains the application as well as Talend Maven plugins can now be hosted on your local server and automatically installed during the build process. To increase your performances and resource utilization, the size of Talend CommandLine has been reduced by half. |