
Setting a data model in the Merging campaign
Data models decide the structure of the data to be managed. They are used for the syntactic and semantic validation of data.
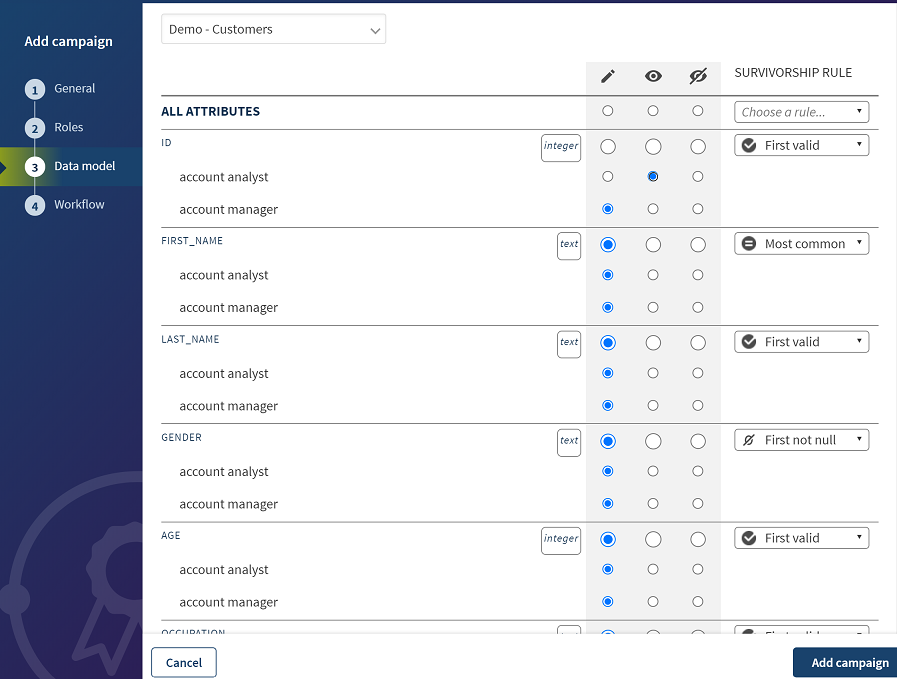
You can define the access permission per role to each of the attributes listed in a data model.
Procedure
-
On the Add campaign page, click Data
model and select from the model list the data structure you want to
use in the CRM data deduplication campaign.
The Data Model list gives access to all the data models that have been defined.
-
Select the buttons next to
each of the attributes in the data structure to set permission per attribute and
per data steward and define who can view/edit which attributes.
Option Description 
Provides a read/write access to the attribute in the data model. 
Provides only a read access to the attribute in the data model. This type of access is useful if the data steward needs to access the information to make a relevant decision but must not change the value, for instance unique identifiers of other elements linked to the entity the steward is viewing, or data that you know is reliable and must not be changed.
Provides no access to the attribute. Hiding an attribute is useful if the information is sensitive and should not be visible by the data steward, financial information for instance. Another example of attributes to be hidden is if the information is just noise for the steward, technical identifier for instance, but need to be propagated as part of the task.
Example
In the CRM Data Deduplication campaign, you grant a read-only access to the identifier attribute for the data stewards who are assigned the Account analyst role.