LOAD 문은 파일, 스크립트에 정의된 데이터, 이전에 로드한 테이블, 웹 페이지, 이후 SELECT 문의 결과에서 필드를 로드하거나 자동으로 데이터를 생성하여 필드를 로드합니다. 분석 연결에서 데이터를 로드할 수도 있습니다.
구문:
LOAD [ distinct ] fieldlist
[( from file [ format-spec ] |
from_field fieldassource [format-spec]|
inline data [ format-spec ] |
resident table-label |
autogenerate size ) |extension pluginname.functionname([script] tabledescription)]
[ where criterion | while criterion ]
[order by orderbyfieldlist ]
인수:
| 인수 | 설명 |
|---|---|
| distinct |
고유한 레코드만 로드하려는 경우 distinct를 조건자로 사용할 수 있습니다. 중복 레코드가 있는 경우 첫 번째 인스턴스가 로드됩니다. 선행 Load를 사용하는 경우 distinct는 대상 테이블에만 영향을 주므로 첫 번째 Load 문에 distinct를 배치해야 합니다. |
| fieldlist |
fieldlist ::= ( * | field {, * | field } )
로드할 필드의 목록입니다. 필드 목록에 *를 사용하면 테이블의 모든 필드를 지정할 수 있습니다. field ::= ( fieldref | expression ) [as aliasname ]필드 정의는 리터럴, 기존 필드에 대한 참조 또는 표현식을 항상 포함해야 합니다. fieldref ::= ( fieldname |@fieldnumber |@startpos:endpos [ I | U | R | B | T] )fieldname은 테이블의 필드 이름과 동일한 텍스트입니다. 필드 이름에 공백 등이 포함된 경우 곧은 큰따옴표 또는 대괄호로 묶어야 합니다. 필드 이름을 명시적으로 사용할 수 없는 경우도 있습니다. 이 경우 다른 표기법이 사용됩니다. @fieldnumber는 구분된 테이블 파일의 필드 번호를 나타냅니다. 이 숫자는 "@"가 앞에 오는 양의 정수여야 합니다. 숫자는 항상 1부터 시작하며 필드 개수까지 지정할 수 있습니다. @startpos:endpos는 고정 길이 레코드를 가진 파일 내 필드의 시작과 끝 위치를 나타냅니다. 위치는 모두 양의 정수여야 합니다. 이 두 숫자는 "@"가 앞에 와야 하며 콜론으로 구분되어야 합니다. 숫자는 항상 1부터 시작하며 위치 개수까지 지정할 수 있습니다. 마지막 필드의 n은 종료 위치로 사용됩니다.
expression은 같은 테이블 내의 하나 또는 여러 다른 필드에 따라 숫자 함수 또는 문자열 함수가 될 수 있습니다. 자세한 내용은 표현식의 구문을 참조하십시오. |
| from |
from은 폴더 또는 웹 파일 데이터 연결을 사용하여 파일에서 데이터를 로드해야 하는 경우에 사용됩니다. file ::= [ path ] filename 'lib://Table Files/' 경로를 생략한 경우 Qlik Sense는 Directory 문으로 지정된 디렉터리에서 파일을 검색합니다. Directory 문이 없으면 Qlik Sense가 작업 디렉터리 C:\Users\{user}\Documents\Qlik\Sense\Apps에서 검색합니다. 정보 메모Qlik Sense 서버 설치에서 작업 디렉터리는 Qlik Sense Repository Service에서 지정되며, 기본적으로 C:\ProgramData\Qlik\Sense\Apps입니다. 자세한 내용은 Qlik Management Console 도움말을 참조하십시오.
filename에는 표준 DOS 와일드카드 문자(* 및 ?)가 포함될 수 있습니다. 이는 지정된 디렉터리 내에서 일치하는 파일이 모두 로드되도록 합니다. format-spec ::= ( fspec-item { , fspec-item } )서식 사양은 괄호 안에 포함된 여러 서식 사양 항목 목록으로 구성됩니다. 팁 메모로드된 다른 데이터를 기반으로 동적 URL을 만들어야 하는 경우처럼 웹 파일 데이터 연결의 URL을 재정의하려면 URL is 서식 사양을 사용하면 됩니다.
레거시 스크립팅 모드 레거시 스크립팅 모드에서는 다음 경로 형식도 지원됩니다.
|
| from_field | from_field는 이전에 로드한 필드에서 데이터를 로드해야 하는 경우에 사용됩니다. fieldassource::=(tablename, fieldname) 이 필드는 이전에 로드한 tablename 및 fieldname의 이름입니다. format-spec ::= ( fspec-item {, fspec-item } )서식 사양은 괄호 안에 포함된 여러 서식 사양 항목 목록으로 구성됩니다. |
| inline | inline은 데이터를 스크립트 내에 입력해야 하고 파일에서 로드되지 않도록 해야 하는 경우에 사용됩니다. data ::= [ text ] inline 절을 통해 입력된 데이터는 큰따옴표 또는 대괄호로 묶어야 합니다. 그 사이에 입력되는 텍스트는 파일의 내용과 동일한 방식으로 해석됩니다. 그러므로 텍스트 파일에 새 줄을 삽입하는 경우 inline 절의 텍스트에도 스크립트를 입력하면서 Enter 키를 누르는 등의 방법으로 동일하게 새 줄을 삽입해야 합니다. 첫 번째 줄에 열 수를 정의합니다. format-spec ::= ( fspec-item {, fspec-item } )서식 사양은 괄호 안에 포함된 여러 서식 사양 항목 목록으로 구성됩니다. |
| resident | resident는 이전에 로드한 테이블에서 데이터를 로드해야 하는 경우에 사용됩니다. table label은 원래 테이블을 만든 LOAD 또는 SELECT 문 앞에 오는 레이블입니다. 이 레이블은 콜론으로 끝나야 합니다. |
| autogenerate | autogenerate는 Qlik Sense에서 자동으로 데이터를 생성해야 하는 경우에 사용됩니다. size ::= number Number는 생성할 레코드의 수를 나타내는 정수입니다. Peek 함수를 사용하여 이전에 로드한 테이블에서 단일 필드 값을 참조하지 않는 한, 필드 목록에는 외부 데이터 소스 또는 이전에 로드한 테이블로부터 데이터를 요구하는 표현식을 포함하지 않아야 합니다. |
| extension |
분석 연결에서 데이터를 로드할 수 있습니다. SSE(서버 측 확장) 플러그인에 정의된 함수를 호출하거나 스크립트를 평가하려면 extension 절을 사용해야 합니다. 단일 테이블을 SSE 플러그인에 보내면 단일 데이터 테이블이 반환됩니다. 플러그인이 반환되는 필드의 이름을 지정하지 않으면 필드의 이름이 Field1, Field2로 지정되는 식으로 계속됩니다. Extension pluginname.functionname( tabledescription );
테이블 필드 정의에서 데이터 유형 처리 데이터 유형은 분석 연결에서 자동으로 감지됩니다. 데이터에 숫자 값과 적어도 하나의 NULL이 아닌 텍스트 문자열이 있으면 이 필드가 텍스트로 간주됩니다. 다른 경우에는 숫자로 간주됩니다. String() 또는 Mixed()로 필드 이름을 래핑하여 데이터 유형을 강제로 설정할 수 있습니다.
String() 또는 Mixed()는 extension 테이블 필드 정의 외부에서 사용할 수 없으며 테이블 필드 정의에서 다른 Qlik Sense 함수를 사용할 수 없습니다. 분석 연결 추가 정보 분석 연결을 사용하려면 먼저 구성해야 합니다. Qlik Sense Enterprise: 분석 연결 만들기 (영어로만 제공) Qlik Sense Desktop: 에서 분석 연결 구성Qlik Sense Desktop 분석 연결에 대한 자세한 내용은 GitHub 리포지토리에서 볼 수 있습니다. qlik-oss/server-side-extension |
| where | where는 레코드를 선택에 포함할지를 나타내는 데 사용하는 절입니다. criterion이 True인 경우 선택 내용이 포함됩니다. criterion은 논리 표현식입니다. |
| while |
while은 레코드를 반복적으로 읽어야 할지 여부를 지정하는 데 사용되는 절입니다. criterion이 True이면 동일한 레코드를 읽습니다. while 절을 유용하게 사용하려면 일반적으로 IterNo( ) 함수를 포함해야 합니다. criterion은 논리 표현식입니다. |
| group by |
group by는 데이터를 집계(그룹화)해야 하는 필드를 정의하는 데 사용되는 절입니다. 집계 필드는 로드한 표현식에 어떤 방식으로든 포함되어야 합니다. 집계 필드 외의 필드는 로드한 표현식의 집계 함수 외부에서 사용할 수 없습니다. groupbyfieldlist ::= (fieldname { ,fieldname } ) |
| order by | order by는 상주 테이블의 레코드가 load 문에 의해 처리되기 전에 정렬하는 데 사용되는 절입니다. 상주 테이블은 하나 이상의 필드를 기준으로 오름차순 또는 내림차순으로 정렬할 수 있습니다. 기본적으로 숫자 값을 기준으로 정렬되며, 2차적으로 국가별 정렬 순서에 따라 정렬됩니다. 이 절은 데이터 소스가 상주 테이블인 경우에만 사용할 수 있습니다. 정렬 필드는 상주 테이블의 정렬 기준 필드를 지정합니다. 이 필드는 상주 테이블 내의 이름 또는 번호(첫 번째 필드는 1번)로 지정할 수 있습니다. orderbyfieldlist ::= fieldname [ sortorder ] { , fieldname [ sortorder ] } sortorder는 asc(오름차순) 또는 desc(내림차순)입니다. sortorder를 지정하지 않으면 asc가 사용됩니다. fieldname, path, filename 및 aliasname은 각 이름의 의미를 나타내는 텍스트 문자열입니다. 소스 테이블의 모든 필드를 fieldname으로 사용할 수 있습니다. 그러나 as 절(aliasname)을 통해 만든 필드는 해당되지 않으며 같은 load 문에서 사용할 수 없습니다. |
from, inline, resident, from_field, extension 또는 autogenerate 절을 통해 지정된 데이터 소스가 없는 경우 데이터는 바로 다음에 나오는 SELECT 또는 LOAD 문의 결과에서 로드됩니다. 다음에 나오는 문에는 접두사가 없어야 합니다.
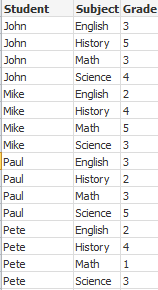
이 예에서는 한 필드에 요약된 각 학생의 성적이 포함된 입력 파일 Grades.csv를 사용합니다.
Student,Grades
Mike,5234
John,3345
Pete,1234
Paul,3352
1~5 눈금의 성적은 과목 Math, English, Science 및 History를 나타냅니다. IterNo( ) 함수를 카운터로 사용하여 while 절로 여러 번 레코드를 읽으면 개별 값으로 성적을 구분할 수 있습니다. 읽은 각 성적은 Mid 함수로 추출되어 Grade에 저장됩니다. 과목은 pick 함수를 사용하여 선택되어 Subject에 저장됩니다. 마지막 while 절에는 다음 학생 레코드를 읽어야 함을 의미하는, 모든 성적을 읽었는지(이 경우는 학생당 4개) 확인하는 테스트 기능이 포함되어 있습니다.
MyTab:
LOAD Student,
mid(Grades,IterNo( ),1) as Grade,
pick(IterNo( ), 'Math', 'English', 'Science', 'History') as Subject from Grades.csv
while IsNum(mid(Grades,IterNo(),1));
결과는 이 데이터가 포함된 테이블입니다.