
Data Lake project guidelines
The following topic provides guidelines for setting up your Hive cluster and determining the scheduling frequency of Change Processing storage tasks.
Working with views
Compose creates the Storage Zone with both storage tables and storage views. The storage tables are created in the database that you defined in your storage settings while two separate database are created for the views: The exposed views database and the internal views database. The exposed views database is the primary views database and contains all view types. The internal views database is used to store updates to ODS Live Views and HDS Live Views. The exposed views database and the internal views database share the same name as the Storage Zone database, but are appended with a unique suffix (by default, _v and _v_internal respectively), which is set in the project settings’ Naming tab. Consuming applications should be set up to read from the exposed views database, which provide several benefits over tables including better security (requiring read-only access only), data concurrency, and minimizing duplicate records in projects defined with non-ACID storage.
Optimizing your Hive cluster setup
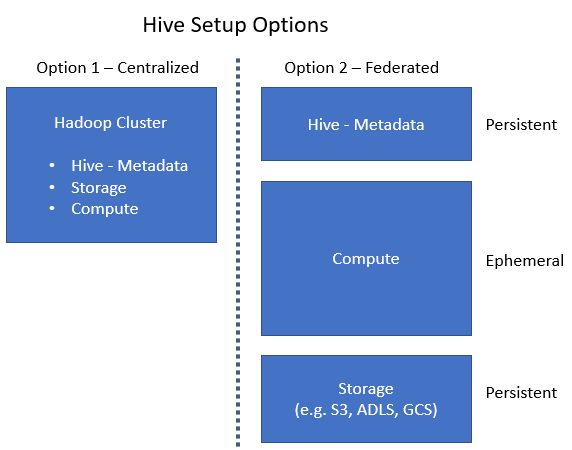
While the convenience of having the metadata, storage system, and compute platform on a single machine may have certain benefits (Option 1 below), it may also increase costs. Having the metadata and the storage on separate clusters to the compute platform (Option 2 below) will allow you to power down the compute machine when it's not in use, thereby saving costs.
Compose can work with either Option 1 or Option 2 without requiring any special configuration. Simply specify the Hive server and database name in the storage connection settings.
Note that certain platforms such as Databricks automatically power the compute platform on and off as needed. With these platforms, Option 2 may not offer any benefits over Option 1.
As the “Federated” architecture may be better suited to certain environments, it’s recommended to compare the performance of both options in a test environment before deciding which one to go with.
Determining scheduling frequency
To prevent data inconsistency issues, you should schedule the Change Processing storage task frequency to be greater than or equal to the Partition every interval defined for the Replicate task (in the Task Settings’ Store Changes Settings tab).
As a general rule, the shorter the Change Processing task interval, the greater the impact on performance and the higher the computing costs. Therefore, it is recommended to limit the frequency of Change Processing tasks only to what is absolutely necessary.
The scheduling frequency should be determined by the rate at which data updates are required by downstream consuming applications.