
What's new?
The following section describes the enhancements and new features introduced in Qlik Compose May 2022.
What's new in Data Warehouse projects?
The following section describes the enhancements and new features introduced in Qlik Compose Data Warehouse projects.
Keeping changes in the Change Tables
This version introduces a new Keep in Change Tables option in the landing zone connection settings:

When you select the Keep in Change Tables option, the changes are kept in the Change Tables after they are applied (instead of being deleted or archived). This is useful as it allows you to:
- Use the changes in multiple Compose projects that share the same landing
- Leverage Change Table data across multiple mappings and/or tasks in the same project
-
Preserve the Replicate data for auditing purposes or reprocessing in case of error
-
Reduce cloud data warehouse costs by eliminating the need to delete changes after every ETL execution
Referenced dimensions
This version introduces support for referencing dimensions. To facilitate this new functionality, a new Reference selected dimensions option has been added to the Import Dimensions dialog which, together with the toolbar button, has been renamed to Import and Reference Dimensions.
The ability to reference dimensions improves data mart design efficiency and execution flexibility by facilitating the reuse of data sets. Reuse of dimension tables across data marts allows you to break up fact tables into smaller units of work for both design and data loading, while ensuring consistency of data for analytics.
Data mart enhancements
Data mart adjust
This version introduces the following enhancements:
- The automatic data mart adjust feature has been extended to include DROP COLUMN and ADD COLUMN support.
-
In previous versions, adding a dimension which did not relate to any fact would require the data mart to b e dropped and recreated. From this version, such dimensions can be adding using auto-adjust, including Date and Time dimensions.
- The generate_project CLI now supports automatic data mart adjust for specific objects. In previous versions, Compose would adjust the data marts by dropping and recreating the tables, regardless of the required change. This would sometimes take a lot of time to complete. From this version, only the changes will be adjusted. For example, if a new column was added to a dimension, only that specific column will be added to the data mart tables. To support this new functionality the --stopIfDatamartsNeedRecreation parameter must be included in the command. I this parameter is omitted and the data mart needs to be adjusted, Compose will drop and recreate the data mart tables like it did in previous versions.
Data mart reloading
This version introduces the ability to reload the data mart or parts of the data mart without dropping and recreating it, thereby eliminating costly and lengthy reloading of the data mart while maximizing data availability. Such operations should usually be performed after a column with history has been added by the automatic adjust operation.
To facilitate this, a new mark_reload_datamart_on_next_run CLI has been developed. The new CLI allows users to mark dimensions and facts to be reloaded on the next data mart run. These can either be specific dimensions and facts or multiple dimensions and facts (either from the same data mart or different data marts) using a CSV file.
Microsoft Azure Synapse Analytics Enhancements
A number of changes related to statistics have been implemented. In addition, several statements are now tagged with an identifier label for troubleshooting 'problem queries' and identifying possible ways to optimize database settings. Moreover, the addition of labels to ELT queries enables fine-grained workload management and workload isolation via Synapse WORKLOAD GROUPS and CLASSIFIERS.
The identifier labels are as follows:
| Table type | Tag |
|---|---|
| Hubs |
CMPS_HubIns |
| Satellites | CMPS_SatIns |
| Type1 dimensions | CMPS_<data mart name>_DimT1_Init/CMPS_<data mart name>_DimT1_Incr |
| Type2 dimensions | CMPS_<data mart name>_DimT2_Init/CMPS_<data mart name>_DimT2_Incr |
| Transactional facts | CMPS_<data mart name>_FctTra_Init/CMPS_<data mart name>_FctTra_Incr |
| State-oriented facts | CMPS_<data mart name>_FctStO_Init |
| Aggregated facts: | CMPS_<data mart name>_FctAgg_Init |
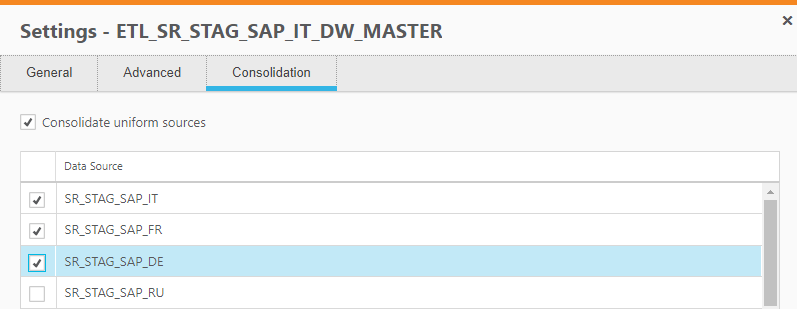
Uniform source consolidation
Uniform source consolidation as its name suggests allows you to ingest data from multiple sources into a single, consolidated, entity.
To enable uniform source consolidation configuration, a new Consolidation tab has been added to the data warehouse task settings.
When the Consolidate uniform sources option is enabled, Compose will read from the selected data sources and write the data to one consolidated entity. This is especially useful if your source data is managed across several databases with the same structure, as instead of having to define multiple data warehouse tasks (one for each source), you only need to define a single task that consolidates the data from the selected data sources.
Environment variables
Environment variables allow developers to build more portable expressions, custom ETLs, and Compose configurations, which is especially useful when working with several environments such as DTAP (Development, Testing, Acceptance and Production). Different environments (for example, development and production) often have environment-specific settings such as database names, schema names, and Replicate task names. Variables allow you to easily move projects between different environments without needing to manually configure the settings for each environment. This is especially useful if many settings are different between environments. For each project, you can use the predefined environment variables or create your own environment variables.
Excluding environment variables from export operations
An option has been added to replace environment-specific settings with the defaults when exporting projects (CLI) or creating deployment packages.
To facilitate this functionality, the --without_environment_specifics parameter was added to the export_project_repository CLI and a Exclude environment variable values option was added to the Create Deployment Package dialog.
Support for data profiling and data quality rules when using Google Cloud BigQuery
You can now configure data profiling and data quality rules when using Google Cloud BigQuery as a data warehouse.
Attributes case sensitivity support
In previous versions, attempting to create several Attributes with the same name but a different case would result in a duplication error. Now, such attributes will now be created with an integer suffix that increases incrementally for each attribute added with the same name. For example: Sales, SALES_01, and Sales_02.
Associating a Replicate task that writes to a Hadoop target
You can now associate a Replicate task that writes to a Hadoop target with the Compose landing.
Performance improvements
This version provides the following performance improvements:
-
Validating a model with self-referencing entities is now significantly faster than in previous versions. For instance, it now takes less than a minute (instead of up to two hours) to validate a model with 5500 entities.
-
The time it takes to "Adjust" the data warehouse has been significantly reduced. For instance, it now takes less than three minutes (instead of up to two hours) to adjust a data warehouse with 5500 entities.
-
Optimized queries, resulting in significantly improved data warehouse loading and CDC performance.
-
Significantly improved the loading speed of data mart Type 2 dimensions with more than two entities. In order to benefit from this improvement, customers upgrading with existing data marts needs to regenerate their data mart ETLs.
-
Improved performance of data warehouse loading, by reducing statements executed when there is no data to process. This change impacts cloud data warehouses such as Snowflake, Amazon Redshift, Google BigQuery, and so on.
Information noteRelevant from Compose May 2022 SR1 only.
Support for Redshift Spectrum external tables
Customers who want to leverage this support need to create Redshift Spectrum external tables and discover them. Additionally, when running a CDC task, the new Keep in Change Tables option described above needs to be turned on.
Data mart UX improvement
The Data Mart Dimensions tree and the Star Schema Fact tab were redesigned to provide a better user experience.
Support for updating custom ETLs using the CLI
This version introduces support for updating custom ETLs using the Compose CLI. This functionality can be incorporated into a script to easily update Custom ETLs.
Support for defining a custom data mart schema in Microsoft Azure Synapse Analytics
Customers working with Microsoft Azure Synapse Analytics can now utilize the Create tables in schema option (in the data mart settings) to define a custom schema for the data mart tables.
What's new in Data Lake projects?
The following section describes the enhancements and new features introduced in Qlik Compose Data Lake projects.
Support for excluding deleted records from ODS views
A Deleted records in ODS views section has been added to the General tab of the project settings, with the following options:
- Exclude the corresponding record from the ODS views - This is the default option as records marked as deleted should not usually be included in ODS views.
-
Include the corresponding record in the ODS views - Although not common, in some cases, you might want include records marked as deleted in the ODS views in order to analyze the number of deleted records and investigate the reason for their deletion. Also, regulatory compliance might require you to be able to retrieve the past record status (which requires change history as well).
Information noteAs this was the default behavior in previous versions, you might need to select this option to maintain backward compatibility.
Improved Historical Data Store resolution
In previous versions, HDS resolution was one second. This was problematic at times as multiple changes to a Primary Key within a second resulted in only the last change appearing in the HDS. To view all the history, customers were forced to review the landing.
From this version, all changes (history) will shown in the HDS, facilitating better support for auditing.
Associating a Replicate task that writes to a Hortonworks Data Platform target
You can now associate a Replicate task that writes to a Hortwonworks Data Platform target with the Compose landing connection (in a Cloudera Data Platform (CDP) Compose project).
Databricks projects
New Databricks versions
- Databricks 9.1 LTS is now supported on all cloud providers (AWS, Azure, and Google Cloud Platform).
-
Databricks 10.4 LTS is now supported on all cloud providers (AWS, Azure, and Google Cloud Platform).
Information noteDatabricks 10.4 LTS is supported from Compose May 2022 SR1 only.
SQL Warehouse compute and Parquet support
Compose May 2022 SR1 introduces support for SQL Warehouse compute. To benefit from this support, customers need to use the new Replicate Databricks (Cloud Storage) target endpoint, which is available from Replicate November 2022. SQL Warehouse compute offers a lower cost alternative to clusters while also allowing Parquet file format to be used in the Landing Zone.
Support for Unity Catalog
This version introduces support for Databricks Unity Catalog. Customers working with Unity Catalog can now specify a catalog name both in the Landing connection settings and in the Storage connection settings.
New features common to both Data Warehouse projects and Data Lake projects
New Project title setting
A new Project title setting had been added to the Environment tab of the project settings. The project title will be shown in the console banner. If both an Environment Title and a Project Title are defined, the project title will be displayed to the right of the environment title. Unlike the Environment title and Environment type, which are unique for each environment, the project title is environment independent. This means that the project title will always be retained, even when deploying to a different environment.
The following image shows the banner with both an Environment title and a Project title:

Support for Microsoft Edge Browser
This version introduces support for accessing the Compose console using Microsoft Edge.
Windows Server 2022 (64-bit) support
Windows Server 2022 support is available from Compose May 2022 SR1.Security Hardening
For security reasons, command tasks are now blocked by default. To be able to run command tasks, a Compose administrator needs to turn on this capability using the Compose CLI. For more information, see the Compose online help.
Managing user and group roles using the Compose CLI
You can set and update user and group roles using the Compose CLI. You can also remove users and groups from a role in one of the available scopes (for example, Admin in All Projects). This is especially useful if you need to automate project deployment.