
将输出写入 Azure ADLS Gen1
两个输出组件配置为将期望的影片数据和拒绝的影片数据写入 Azure ADLS Gen1 文件夹中的不同目录。
开始之前
- 确保已在 Databricks 中正确创建并运行 Spark 集群。有关更多信息,请参阅 Databricks 文档中的创建 Databricks 工作区 (仅提供英文版本)。
-
确保已经为用于访问 Azure Data Lake Storage Gen1 系统的用户名和密码添加 Spark 属性,每行添加一项。
spark.hadoop.dfs.adls.oauth2.access.token.provider.type ClientCredential spark.hadoop.dfs.adls.oauth2.client.id <your_app_id> spark.hadoop.dfs.adls.oauth2.credential <your_authentication_key> spark.hadoop.dfs.adls.oauth2.refresh.url https://login.microsoftonline.com/<your_app_TENANT-ID>/oauth2/token - 您有一个 Azure 帐户。
- 已正确创建要使用的 Azure Data Lake Storage 服务,并且您的 Azure Active Directory 具有访问它的适当权限。您可以询问您的 Azure 系统管理员以确认这一点,或遵循 Moving data from ADLS Gen1 to ADLS Gen2 using Azure Databricks(英文版)中名为“授予将要使用的应用程序对 ADLS Gen1 文件夹的访问权限”部分中描述的步骤。
步骤
-
双击 tAzureFSConfiguration 以打开其 Component (组件) 视图。
示例
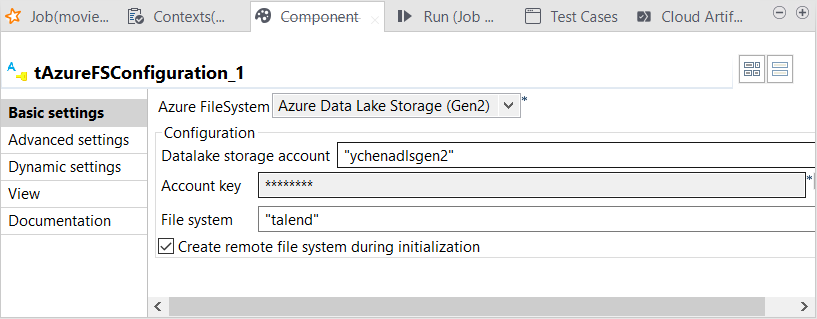
-
双击接收 out1 连接的 tFileOutputParquet 组件。
其 Basic settings (基本设置) 视图在 Studio 的下半部分打开。

-
在 Run (运行) 视图中,单击 Spark Configuration (Spark 配置) 选项卡以打开其视图。
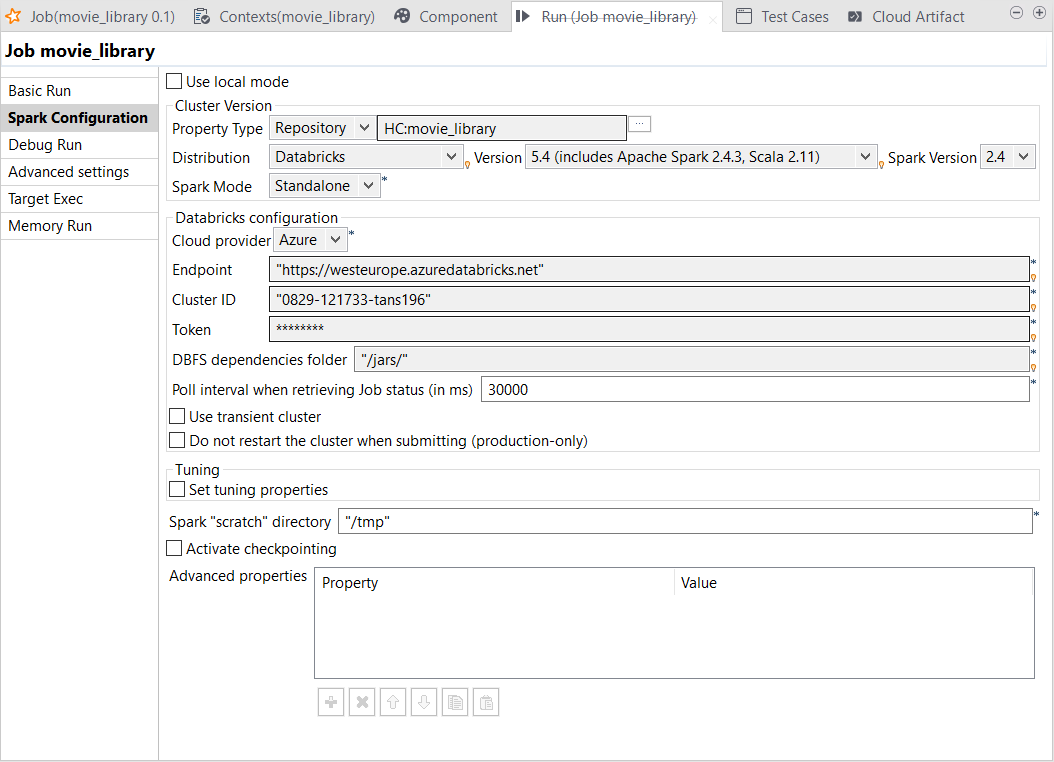
结果
Run (运行) 视图将在 Studio 的下半部分自动打开。
完成后,您可以在 Microsoft Azure Storage Explorer 等工具中检查输出是否已写入 ADLS Gen1 文件夹。