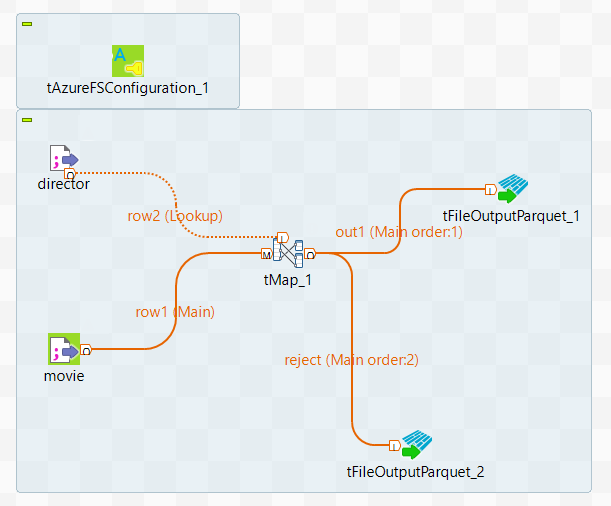
您在作业工作区中编排 Spark Batch 组件,以设计在 Apache Spark Batch 框架中运行的数据转换流程。
步骤
-
在作业中,输入要使用的组件的名称,然后从显示的列表中选择此组件。在本场景中为两个 tFileInputDelimited 组件、一个 tMap 组件、两个 tFileOutputParquet 组件和一个 tAzureFSConfiguration 组件。
-
双击两个 tFileInputDelimited 组件中的其中一个,以使此标签可编辑,然后输入 movie (影片) 以更改此组件的标签。
-
执行相同的操作,将另一个 tFileInputDelimited 标记为 director (导演)。
-
右键单击标记为 movie (影片) 的 tFileInputDelimited 组件,然后从上下文菜单中选择 Row > Main (行 > 主) 并单击 tMap 将其连接到 tMap。这是将影片数据发送到 tMap 的数据流连接,它作为 tMap 的 Main Link(主连接)。
-
执行相同的操作,使用 Row > Main (行 > 主) 连接将 director (导演) tFileInputDelimited 组件连接到 tMap。这是导演数据作为查找数据发送到 tMap 的 Lookup (查找) 连接。
-
使用 Row > Main (行 > 主) 连接将 tMap 组件连接到 tFileOutputParquet,然后在弹出向导中将此连接命名为 out1,并单击 OK (确定) 以确认更改。
-
重复这些操作,使用 Row > Main (行 > 主) 连接将 tMap 组件连接到另一个 tFileOutputParquet 组件,并将其命名为 reject (拒绝)。
结果
在工作区中,整个作业如下所示: