
转换作业
将现有的 Spark Batch 作业转换为 Spark Streaming 作业。
开始之前
-
您已启动 Talend Studio 并打开 集成 透视图。
-
您已创建了 使用 Apache Spark Batch 作业连接影片和导演信息中所述的 aggregate_movie_director_spark Spark Batch 作业并成功运行。
步骤
-
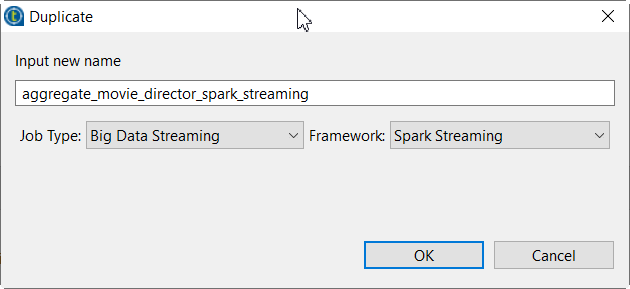
右键单击 aggregate_movie_director_spark 作业,然后从上下文菜单中选择 Duplicate (复制)。
复制 (Duplicate) 窗口即会打开。
结果
这个新的 Spark Streaming 作业现在即可进行进一步编辑。