
Big Data
|
機能 |
説明 |
対象製品 |
|---|---|---|
| ローカルモードでSpark Universal 3.4.xをサポート | [Local] (ローカル)モードのSpark 3.4.xで、Spark Universalを使ってSpark BatchジョブとSpark Streamingジョブを実行できるようになりました。Sparkジョブの[Spark configuration] (Spark設定)ビューまたは[Hadoop Cluster Connection] (Hadoopクラスター接続)メタデータウィザードのどちらかで設定できます。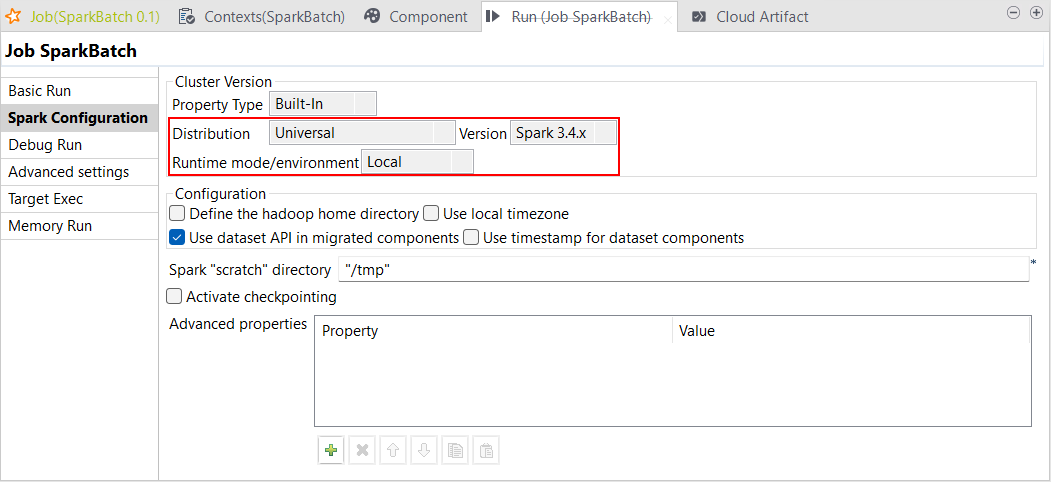
|
サブスクリプションベースであり、Big Dataを伴うTalendの全製品 |
| Spark BatchジョブでSpark Universal 3.2.xと3.3.xを使ったAWS EMR Serverlessでのカスタム設定をサポート | Spark Universal 3.2.xと3.3.xを使ったAWS EMR Serverlessで、Spark Batchジョブの設定をカスタマイズできるようになりました。Spark Batchジョブの[Spark Configuration] (Spark設定)ビューで[Custom settings] (カスタム設定)チェックボックスを選択すればこの操作を実行できます。 この新しいパラメーターによって、すべての設定(事前初期化済みの要領やネットワーク接続など)を制御できます。 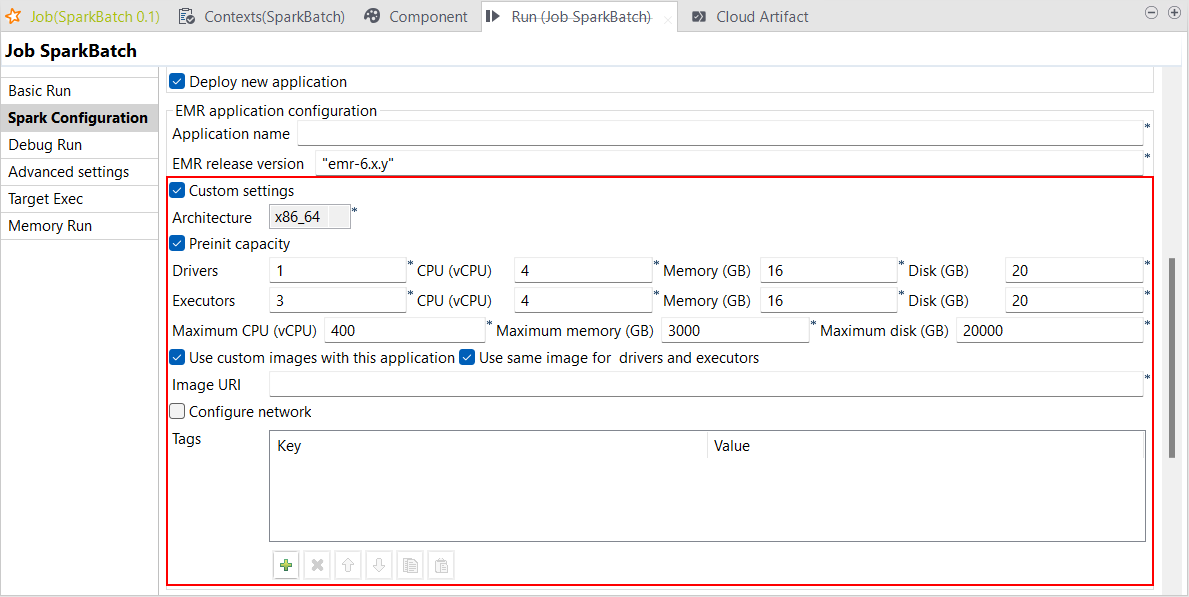
|
サブスクリプションベースであり、Big Dataを伴うTalendの全製品 |
| Spark BatchジョブでのSpark Universal 3.3.xでDataproc 2.1以降をサポート | Spark Universal 3.3.xを使ったDataprocでSpark Batchジョブを実行できるようになりました。これはSpark Batchジョブの[Spark Configuration] (Spark設定)ビューで設定できます。 このモードを選択すると、Talend StudioはDataproc 2.1以降のバージョンと互換性を持つようになります。 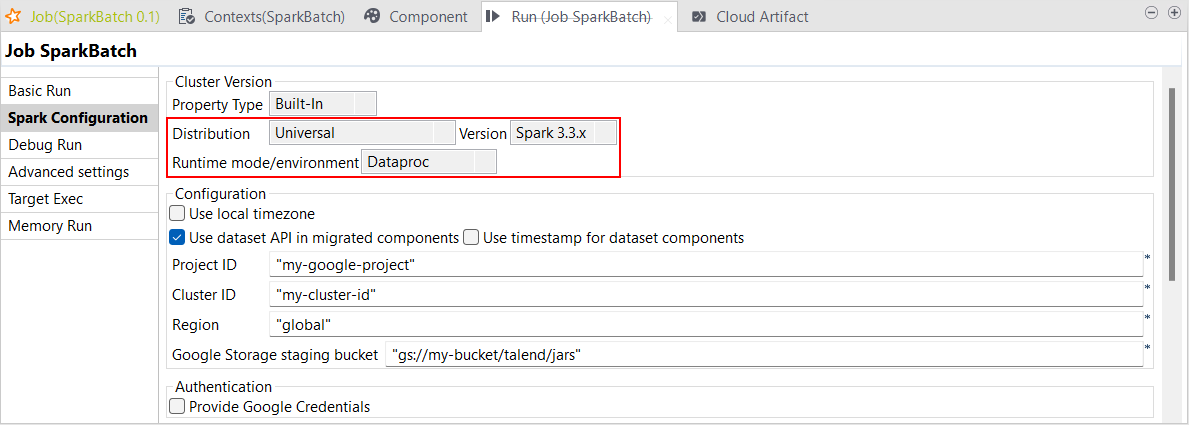
|
サブスクリプションベースであり、Big Dataを伴うTalendの全製品 |
| 標準ジョブでSpark Universal 3.3.xでDataproc 2.1以降をサポート | Hiveコンポーネントを伴う標準ジョブが、Spark Universal 3.3.xでDataproc 2.1以降をサポートするようになりました。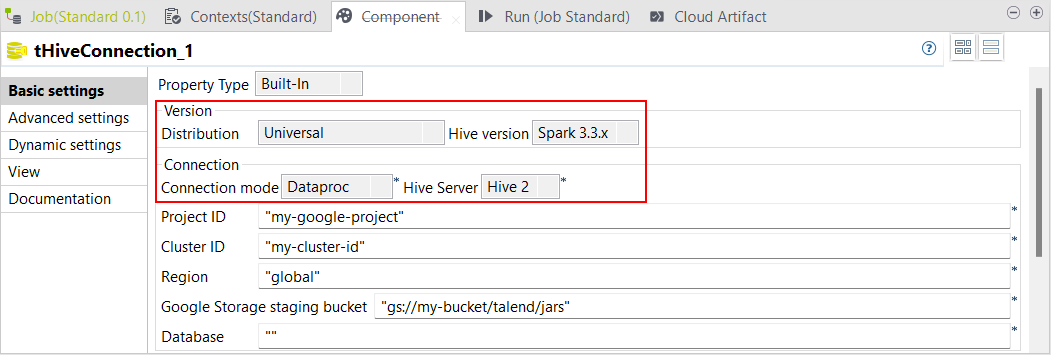
|
サブスクリプションベースであり、Big Dataを伴うTalendの全製品 |
| Spark BatchジョブでのSpark Universal 3.3.xでSpark-submitスクリプトをサポート | Spark-submitスクリプトモードでは、HPE Ezmeral Data Fabric v9.1.xクラスターを活用してSparkバッチジョブを実行できます。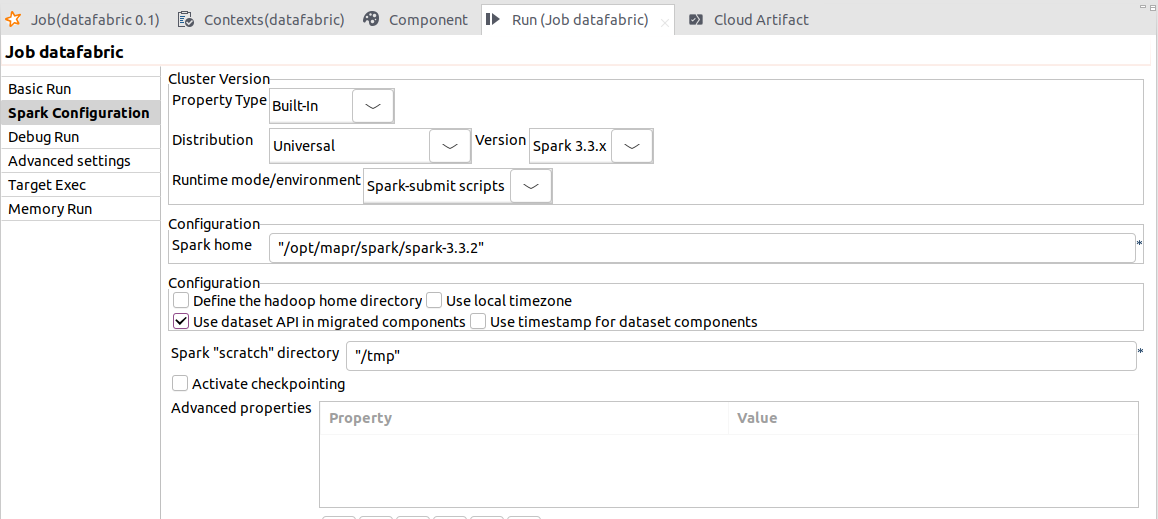 このモードはHPE Data Fabric以外のクラスターでも使用できます。Sparkのドキュメンテーションのcluster managersで説明されているとおり、これはSparkがサポートしているどのクラスタマネージャーで動作するようSpark-submitスクリプトがデザインされているためです。 |
サブスクリプションベースであり、Big Dataを伴うTalendの全製品 |