
Big Data
|
機能 |
説明 |
対象製品 |
|---|---|---|
| 標準ジョブのtHiveCreateTableでIcebergテーブル形式をサポート | ClouderaまたはAmazon EMRのディストリビューションを使い、標準ジョブでtHiveCreateTableによってIcebergテーブルを作成できるようになりました。 Icebergテーブルを使えば、ClouderaディストリビューションではParquet、ORC、Avroなど、Amazon EMRディストリビューションではParquetのみなど、さまざまなファイル形式で作業できます。 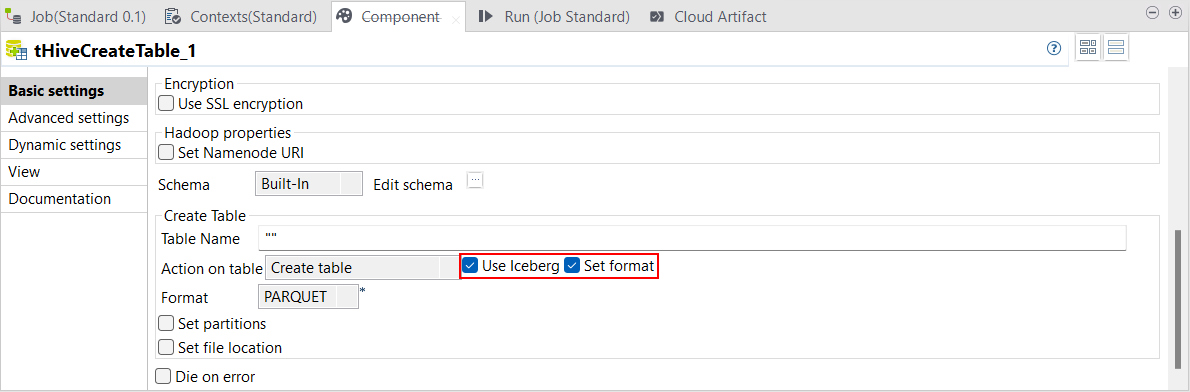
|
サブスクリプションベースであり、Big Dataを伴うTalendの全製品 |
| 標準ジョブにHBaseテーブルのネームスペースを作成する新しいtHBaseNamespaceコンポーネント | 標準ジョブのTalend Studioで、tHBaseNamespaceという新しいコンポーネントが利用可能になりました。このコンポーネントを使えば、HBaseテーブル用のネームスペースを作成できます。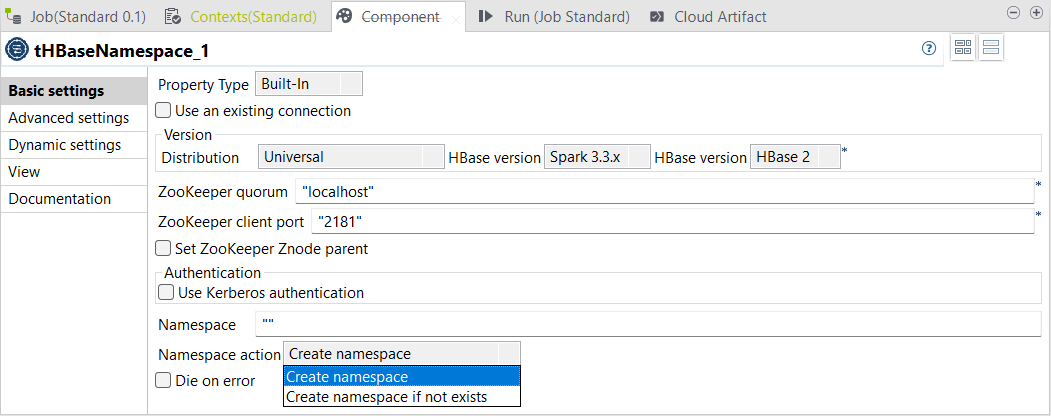
|
サブスクリプションベースであり、Big Dataを伴うTalendの全製品 |
| Spark Universal 3.1.xでHDInsight 5.0をサポート | Spark Universal 3.1.xを使い、HDInsightでSpark BatchジョブとSpark Streamingジョブを実行できるようになりました。この設定は、Sparkジョブの[Spark configuration] (Spark設定)ビューまたは[Hadoop Cluster Connection] (Hadoopクラスター接続)メタデータウィザードでADLS Gen2ストレージまたはAzureストレージを使って実行できます。 このモードを選択すると、Talend StudioはHDInsight 5.0バージョンと互換性を持つようになります。 HDInsightでSparkジョブを実行するためには、コンポーネントにあるLog4jを無効にする必要があります。そのためには、と移動し、[Activate log4j in components] (コンポーネントでlog4jを有効化)チェックボックスをオフにします。 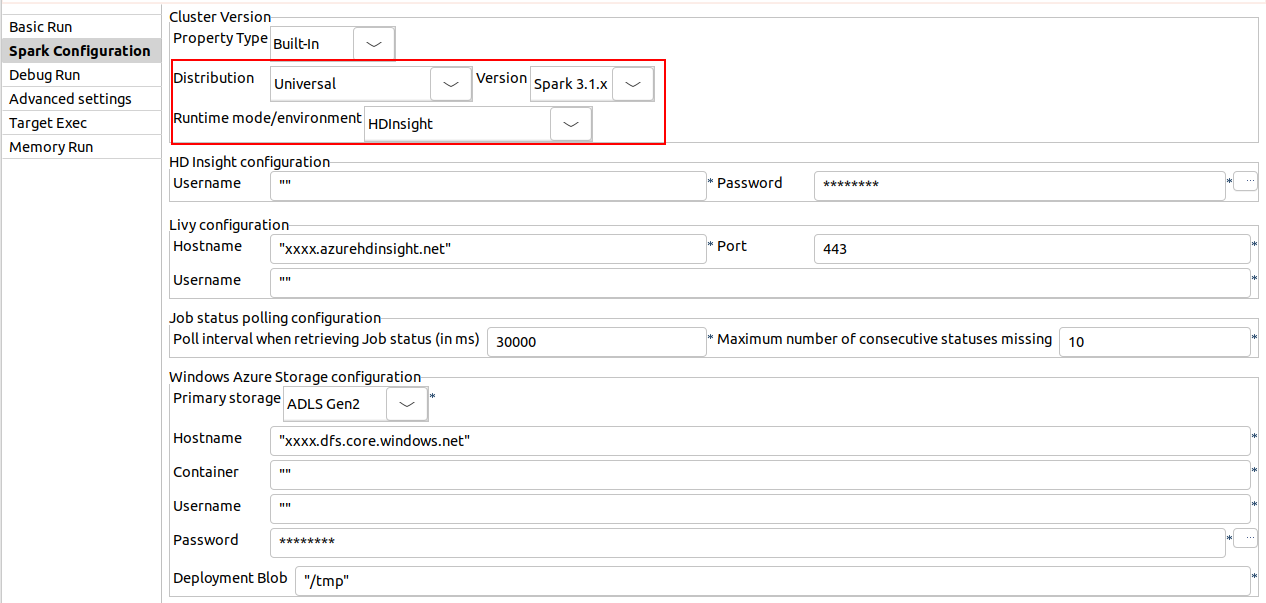
|
サブスクリプションベースであり、Big Dataを伴うTalendの全製品 |
| Spark Universal 3.2.xと3.3.xでAWS EMR Serverless 6.6.0をサポート | Spark Universal 3.2.xと3.3.xを使ったAWS EMR Serverlessで、Spark Batchジョブを実行できるようになりました。これはSpark Batchジョブの[Spark Configuration] (Spark設定)ビューで設定できます。 このモードを選択すると、Talend StudioはAWS EMR Serverless 6.6.0バージョンと互換性を持つようになります。 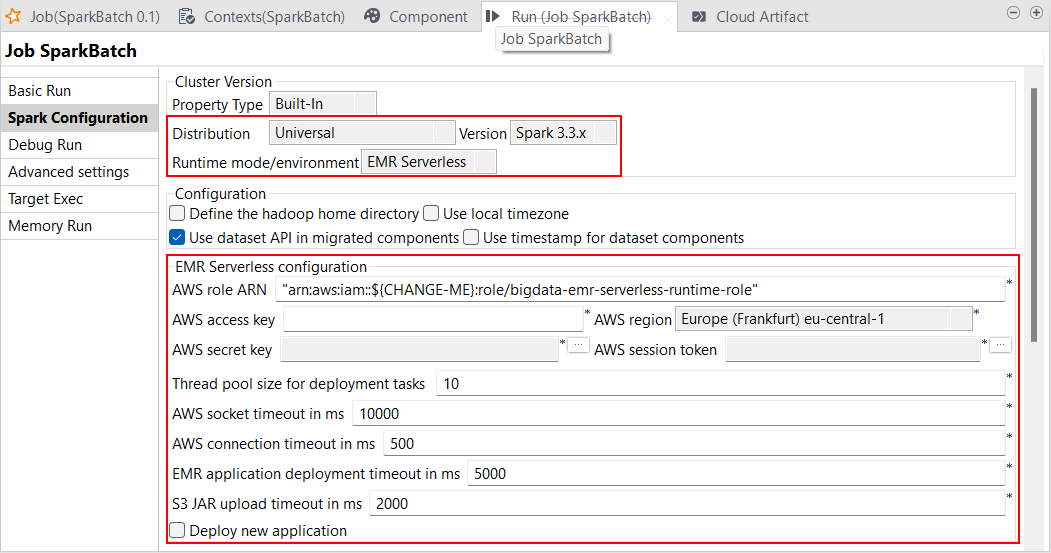
|
サブスクリプションベースであり、Big Dataを伴うTalendの全製品 |