
Simple VSRアルゴリズム
-
[Uniques] (一意): グループサイズ(レコードで計算された最小距離)が1に等しいレコードをリスト表示します。
-
[Matches] (マッチング): グループスコア(レコードで計算された最小距離)が[Confident match threshold] (信頼できるマッチングしきい値)フィールドで定義したしきい値と同等かそれ以上のレコードをリスト表示します。
-
[Suspects] (サスペクト): グループスコア(レコードで計算された最小距離)が[Confident threshold] (信頼しきい値)フィールドで定義したしきい値よりも低いレコードをリスト表示します。
このシナリオは、Talend Data Management Platform、Talend Big Data Platform、Talend Real-Time Big Data Platform、Talend Data Services Platform、Talend Data Fabricにのみ適用されます。
ジョブを設定
手順
-
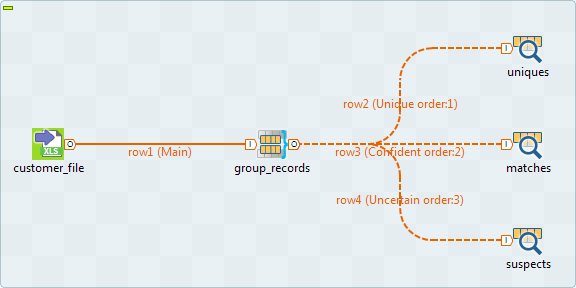
[Uniques] (ユニーク)、[Matches] (マッチング)、および[Suspects] (サスペクト)リンクを使って、tMatchGroupを3つのtLogRowコンポーネントに接続します。
入力コンポーネントを設定
このタスクについて
メイン入力ファイルには、次の8つのカラムが含まれています: account_num、lname、fname、mi、address1、city、state_province、postal_code。この入力ファイル内のデータには、重複、名前のスペルの相違や間違い、同一顧客に異なる情報など、問題があります。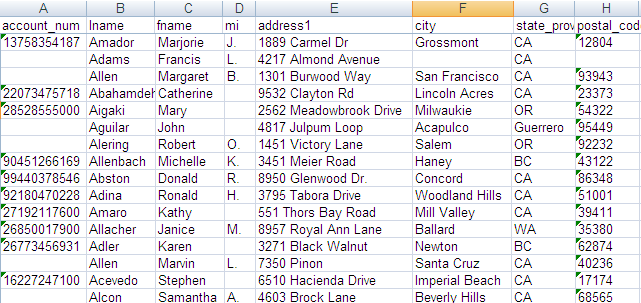
Data Qualityデモプロジェクト、TDQEEDEMOJAVAに含まれているc0ジョブとc1ジョブを実行すれば、このシナリオに使用されている入力ファイルを作成できます。このデモプロジェクトは、Talend Studioのログインウィンドウからインポートできます。詳細は、デモプロジェクトを別のプロジェクトとしてインポートをご覧ください。
手順
-
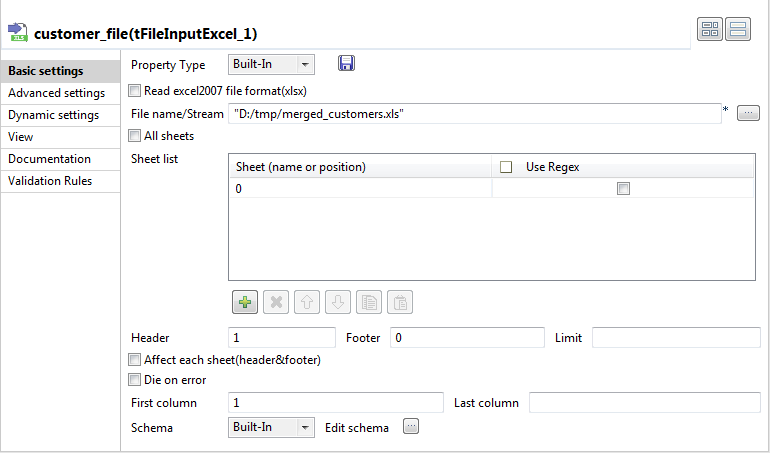
tFileInputExcelの[Basic settings] (基本設定)ビューで、入力ファイルに移動して[File Name] (ファイル名)フィールドに入力し、[Repository] (リポジトリー)に保存されていない場合は、その他のプロパティを設定するために使われます。
-
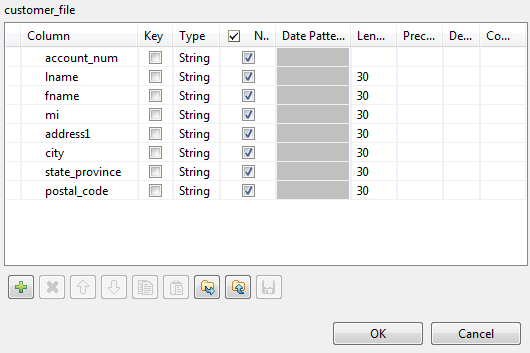
スキーマが[Repository] (リポジトリー)にまだ保存されていない場合は、[Edit Schema] (スキーマを編集)ボタンを使用してスキーマを作成します。[Type] (タイプ)カラムでデータ型を必ず設定してください。
tMatchGroupコンポーネントを設定する
手順
-
[Edit schema] (スキーマを編集)ボタンをクリックして入力および出力スキーマを表示し、必要に応じて出力スキーマに変更を施します。
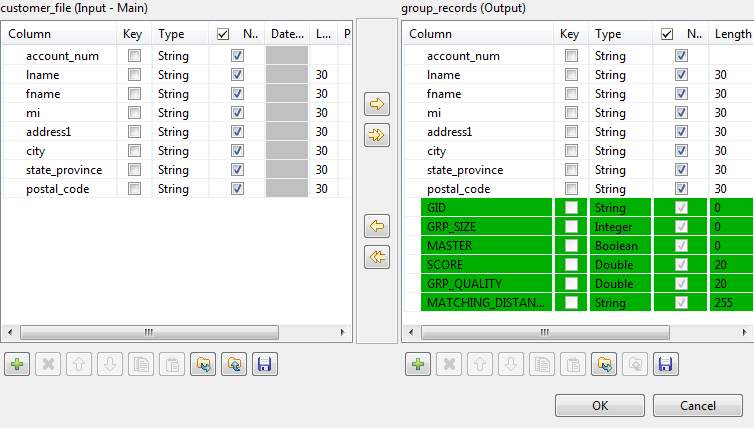 このコンポーネントの出力スキーマには、読み取り専用の出力標準カラムが少数含まれています。詳細は、tMatchGroupの標準プロパティをご覧ください。
このコンポーネントの出力スキーマには、読み取り専用の出力標準カラムが少数含まれています。詳細は、tMatchGroupの標準プロパティをご覧ください。 -
[Configure match rules] (マッチングルールの設定)の横にある[...]ボタンをクリックして設定ウィザードを開き、コンポーネントの設定とマッチングルールを定義します。
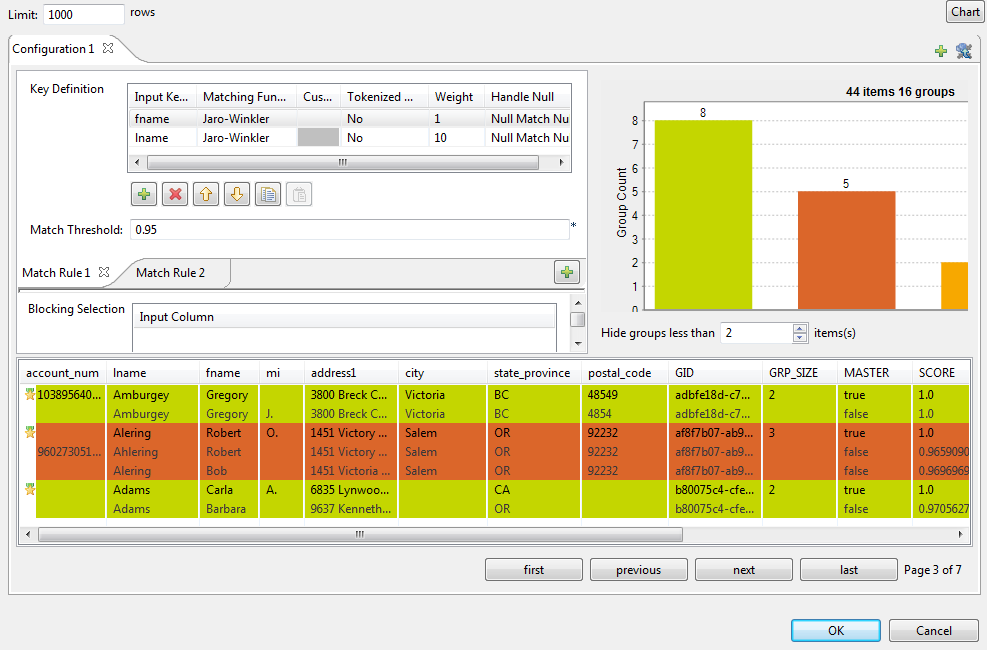 設定ウィザードを使用して、Talend Studioで作成およびテストし、リポジトリーに保存したマッチングルールをインポートし、マッチングジョブで使用できます。詳細は、リポジトリーからマッチングルールをインポートをご覧ください。コンポーネントの基本設定で選択されているのと同じタイプのルールをインポートまたは定義することが重要です。そうでない場合、ジョブは2つのアルゴリズム間で互換性のないパラメーターのデフォルト値で実行されます。
設定ウィザードを使用して、Talend Studioで作成およびテストし、リポジトリーに保存したマッチングルールをインポートし、マッチングジョブで使用できます。詳細は、リポジトリーからマッチングルールをインポートをご覧ください。コンポーネントの基本設定で選択されているのと同じタイプのルールをインポートまたは定義することが重要です。そうでない場合、ジョブは2つのアルゴリズム間で互換性のないパラメーターのデフォルト値で実行されます。 -
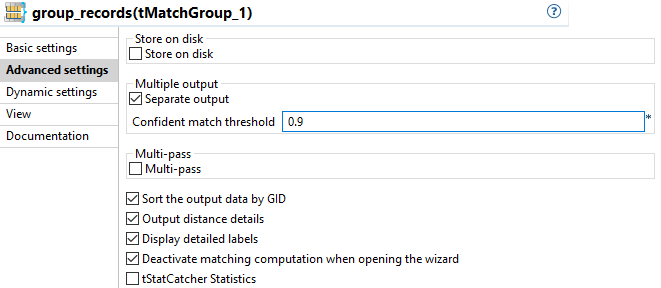
[Advanced settings] (詳細設定)タブをクリックし、tMatchGroupコンポーネントに詳細パラメーターを次のように設定します。
-
[Separate output] (別の出力)チェックボックスをオンにします。
コンポーネントに次の3つの別々の出力フローが含まれます: [Unique rows] (ユニークな行)、[Confident groups] (信頼できるグループ)、および[Uncertain groups] (不確実なグループ)。
このチェックボックスをオンにしていないと、tMatchGroupコンポーネントに含まれる出力フローは1つだけとなり、そこにすべての出力データがまとめられます。シナリオサンプルは、Identificationのセクションで同じ機能キーを持つ出力フロー重複レコード内でカラムを比較し、グルーピングするをご覧ください。
-
[Sort the output data by GID] (出力データをGIDでソート)チェックボックスをオンにして、出力データをそのグループ識別子でソートします。
-
[Output distance details] (距離の詳細)チェックボックスと[Display detailed labels] (詳細ラベルの表示)チェックボックスをオンにします。
コンポーネントは、MATCHING_DISTANCESカラムを出力します。このカラムは、入力カラムとマスターカラムの距離を示します。また、レコードのマッチングを行う基となるカラムの名前も示します。
-
ウィザードを次回開いた時にマッチングルールを実行しない場合は、[Deactivate matching computation when opening the wizard] (ウィザードオープン時にマッチング計算を無効化)チェックボックスをオンにします。
-
-
ウィザードの[Chart] (チャート)ボタンをクリックして、定義済みの設定でジョブを実行し、マッチング結果をウィザードに直接表示します。
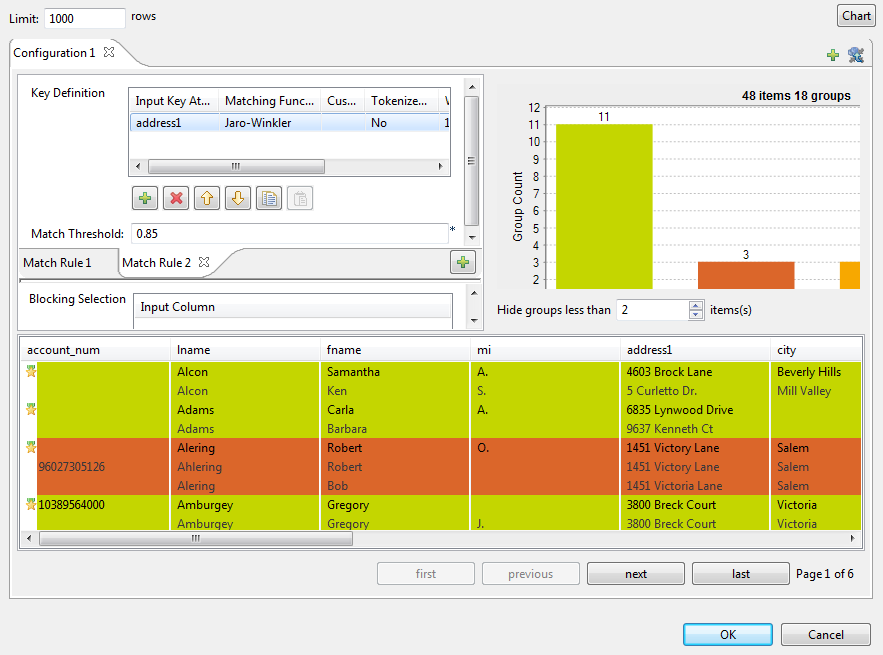 マッチングチャートは、分析されたデータの重複の全体図が表示されます。また、マッチングテーブルには各グループの項目マッチングに関する詳細が示され、マッチングチャートの色に基づいてグループが色分けされます。ジョブはレコードにORマッチングオペレーションを実行します。ジョブは最初のルールを基にレコードを評価し、そこでマッチングしたレコードは2番目のルールでは評価しません。MATCHING_DISTANCESカラムを見ると、どのルールがどのレコードに使用されたかを理解できます。一部のレコードはaddress1をキー属性として使用する2番目のルールに従ってマッチングされます。他方、グループ内のその他のレコードは、lnameとfnameをキー属性として使用する最初のルールに従ってマッチングされます。[Hide groups of less than] (未満でグループを非表示)パラメーターを設定し、マッチングチャートとテーブルに表示するグループを決定します。
マッチングチャートは、分析されたデータの重複の全体図が表示されます。また、マッチングテーブルには各グループの項目マッチングに関する詳細が示され、マッチングチャートの色に基づいてグループが色分けされます。ジョブはレコードにORマッチングオペレーションを実行します。ジョブは最初のルールを基にレコードを評価し、そこでマッチングしたレコードは2番目のルールでは評価しません。MATCHING_DISTANCESカラムを見ると、どのルールがどのレコードに使用されたかを理解できます。一部のレコードはaddress1をキー属性として使用する2番目のルールに従ってマッチングされます。他方、グループ内のその他のレコードは、lnameとfnameをキー属性として使用する最初のルールに従ってマッチングされます。[Hide groups of less than] (未満でグループを非表示)パラメーターを設定し、マッチングチャートとテーブルに表示するグループを決定します。
ジョブの確定と実行
手順
- tLogRowコンポーネントをダブルクリックして、その[Basic settings] (基本設定)ビューを表示し、コンポーネントのプロパティを定義します。
- ジョブを保存し、[F6]を押して実行します。
タスクの結果
レコードが3つの異なるグループにまとめられていることが確認できます。各レコードが、グループ内で計算された最小距離であるグループスコアの値に従って、3つのグループのどれかにリスト表示されます。
各グループの識別子(Stringデータ型のもの)が、対応するレコードの横にあるGIDカラム内にリスト表示されます。この識別子は、古いリリースから移行したジョブの場合はLongというデータ型になります。グループ識別子をStringにするには、インポートしたジョブ内のtMatchGroupコンポーネントを、Talend Studioの[Palette] (パレット)からのtMatchGroupに置き換える必要があります。
3つの出力ブロックのそれぞれのレコード数がGRP_SIZEカラム内にリスト表示され、マスターレコードでのみ計算されます。MASTERカラムは、対応するレコードがマスターレコードかそうでないかをTrueまたはFalseで示します。SCOREカラムには、Jaro-WinklerとJaroマッチングアルゴリズムに従い、入力レコードとマスターレコードの間の計算距離がリスト表示されます。
ジョブは最初のルールを基にレコードを評価し、そこでマッチングしたレコードは2番目のルールでは評価しません。
グループスコアがマッチング間隔(適用するルールに応じて0.95または0.85)の間にあるすべてのレコード、およびtMatchGroupの詳細設定で定義されている信頼しきい値が、[Suspects] (サスペクト)出力フロー内にリスト表示されます。
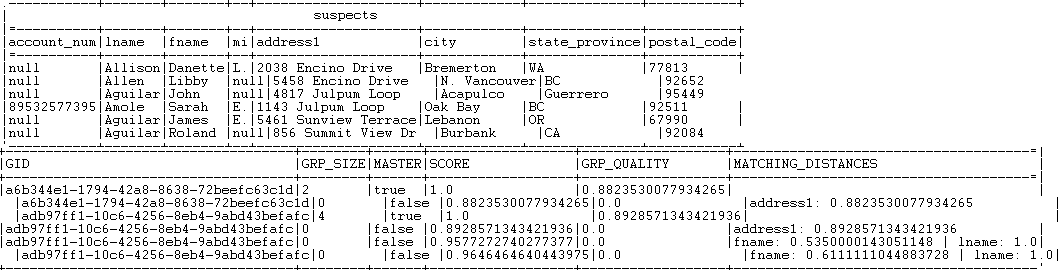
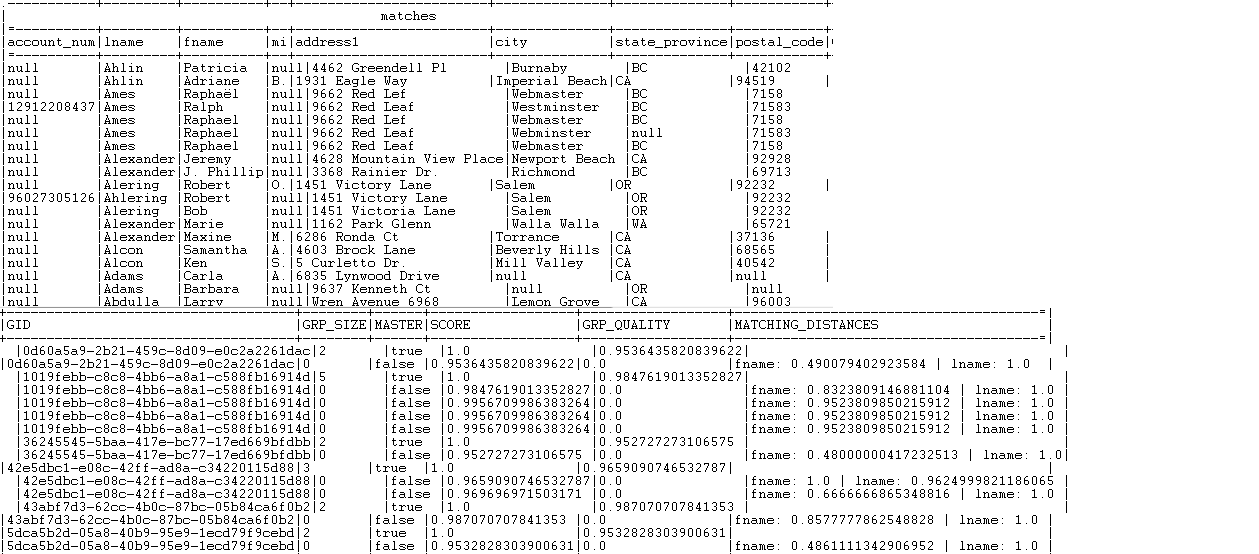
グループスコアがマッチング可能性のどれか以上であるレコードのすべてが、[Matches] (マッチング)出力フロー内にリスト表示されます。
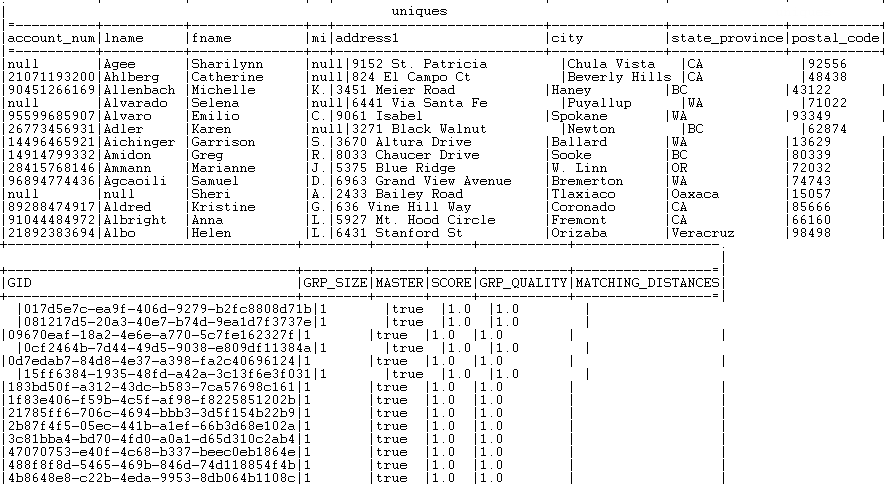
グループサイズが1に等しいレコードのすべてが、[Uniques] (一意)出力フロー内にリスト表示されます。
出力レコードを単一の出力フローにグルーピングする別のシナリオは、Identificationのセクションで同じ機能キーを持つ出力フロー重複レコード内でカラムを比較し、グルーピングするをご覧ください。