
Nouvelles fonctionnalités
Fonctionnalités partagées
| Fonctionnalité | Description |
|---|---|
|
Support des paramètres dynamiques pour les composants TCK |
Toutes les cases et les listes déroulantes des composants TCK peuvent à présent être personnalisées dans l'onglet Dynamic settings (Paramètres dynamiques) avec les limitations suivantes :
|
|
Support de migration de masse des types de base de données dans les composants de bases de données pour les Jobs d'intégration de données |
Vous pouvez migrer votre connexion à la base de données centralisée dans le dossier Metadata (Métadonnées) et réutilisée dans les Jobs d'intégration de données vers un autre type de base de données. Pour plus d'informations, consultez Migrer la connexion à la base de données. Note InformationsRemarque : La base de données Snowflake sera supportée à partir de la version 8.0 R2024-10.
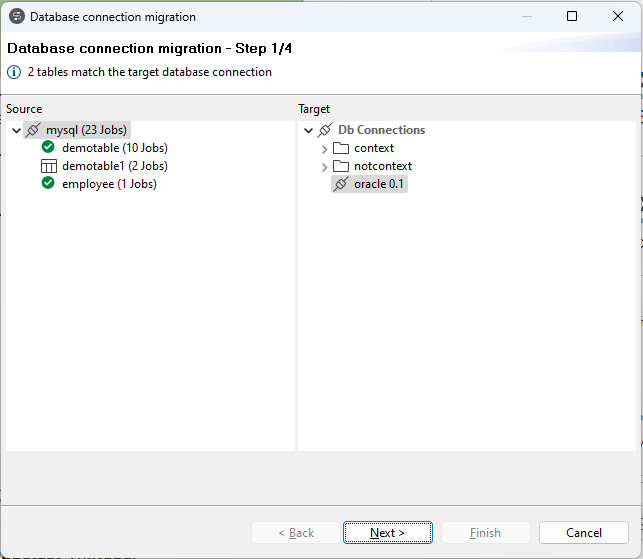 |
Big Data
| Fonctionnalité | Description |
|---|---|
| Amélioration de l'interface de Spark Universal | L'interface de Spark Universal a été améliorée. Vous devez d'abord sélectionner le mode/l'environnement du Runtime (Runtime/mode environment) puis la Version. |
| Support de Kubernetes avec les versions 3.1.x à 3.5.x de Spark | Vous pouvez exécuter vos Jobs Spark en mode Kubernetes avec Spark 3.1.x à 3.5.x, avec la nouvelle option Spark 3.x dans la liste déroulante Version. Vous pouvez la configurer dans la vue Spark Configuration (Configuration de Spark) de vos Jobs Spark ou dans l'assistant de métadonnées Hadoop Cluster Connection (Connexion au cluster Hadoop).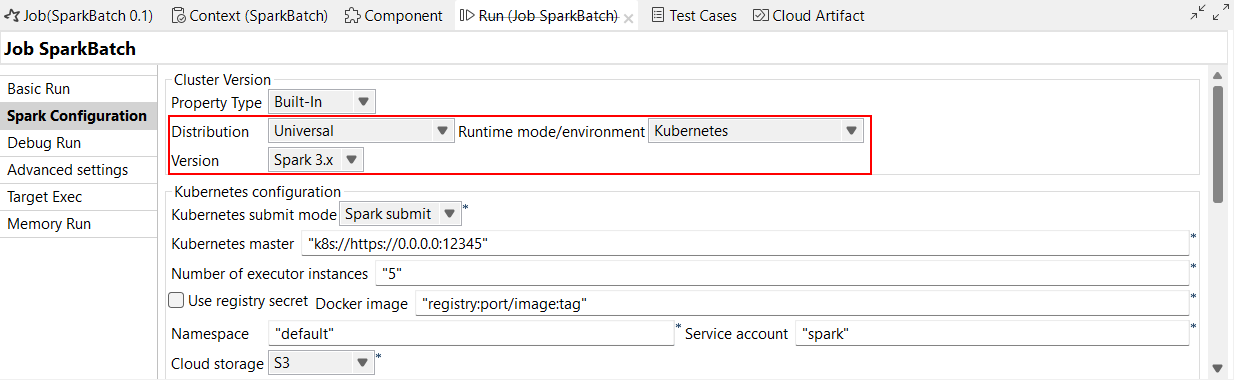 |
| Support d'Amazon EMR 7.x avec Spark Universal 3.5.x | Vous pouvez à présent exécuter vos Jobs Spark sur un cluster Amazon EMR, à l'aide de Spark Universal avec Spark 3.5.x en mode Yarn cluster (Cluster YARN). Vous pouvez la configurer dans la vue Spark Configuration (Configuration de Spark) de vos Jobs Spark ou dans l'assistant de métadonnées Hadoop Cluster Connection (Connexion au cluster Hadoop). Lorsque vous sélectionnez ce mode, le Studio Talend est compatible avec Amazon EMR 7.x. |
Intégration de données
| Fonctionnalité | Description |
|---|---|
Nouveau composant tOpenAIClient dans les Jobs Standards (GA, généralement disponible) |
Le composant tOpenAIClient est généralement disponible à partir de la version 8.0 R2023-09. Pour plus d'informations, consultez la documentation du tOpenAIClient. |
|
Nouveaux composants Solr dans les Jobs Standards |
Nouveaux composants Solr disponibles pour lire et écrire des données dans un service Web Apache Solr :
Pour plus d'informations, consultez la documentation des composants Solr. |
Nouveau composant tPineconeClient dans les Jobs Standards |
Le nouveau composant tPineconeClient vous permet d'effectuer des upserts, des requêtes, des mises à jour ou des suppressions sur des enregistrements dans des espaces de noms d'index Pinecone. Pour plus d'informations, consultez la documentation du tPineconeClient. |
Data Mapper
| Fonctionnalité | Description |
|---|---|
| Support de l'export des maps en tant que fichiers CSV ou Excel | Vous pouvez à présent exporter une map Standard en tant que fichier CSV, avec la nouvelle option Maps as CSV (Maps en tant que CSV). Le fichier exporté est également compatible avec Excel. Pour plus d'informations, consultez Exporter une map. 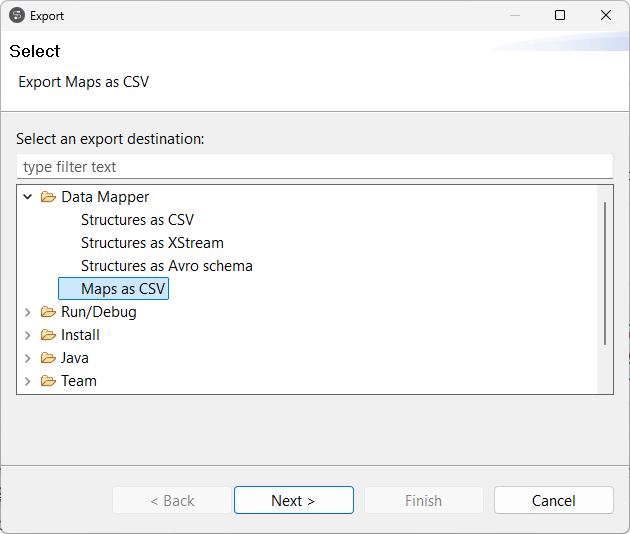 |
| Amélioration de la génération des noms de sortie avec map d'aplatissement | Lorsque vous créez une map d'aplatissement avec plusieurs sorties, le nommage de la sortie est amélioré. La sortie générée est nommée d'après l'élément source d'entrée. Pour plus d'informations concernant les conventions de nommage, consultez Nommage des structures mises à plat. |