
Nouvelles fonctionnalités
Fonctionnalités partagées
| Fonctionnalité | Description |
|---|---|
| Possibilité d'importer des dépendances transitives en tant que bibliothèques pour les routines globales, les Bean globaux, les JAR de routines personnalisées et les JAR de Beans personnalisés | Une nouvelle case Add transitive dependencies (Ajouter les dépendances transitives) est fournie dans la boîte de dialogue Module lorsque vous modifiez des bibliothèques pour une routine globale, un bean global, un JAR de routine personnalisée ou un JAR de bean personnalisé, ce qui vous permet d'importer les dépendances transitives d'un fichier bibliothèque ou d'un fichier POM.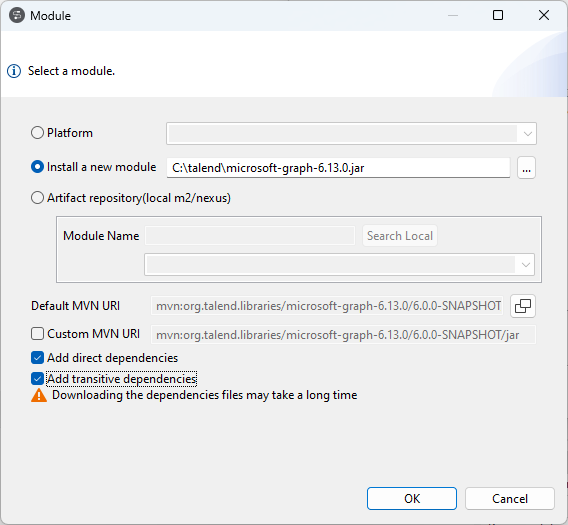 Pour plus d'informations, consultez Modifier les bibliothèques des routines personnalisées et Modifier les bibliothèques des beans. |
Intégration d'application
| Fonctionnalité | Description |
|---|---|
| Nouveau composant cJSLT dans les Routes | Le nouveau composant cJSLT vous permet de transformer des messages JSON à l'aide de modèles JSLT.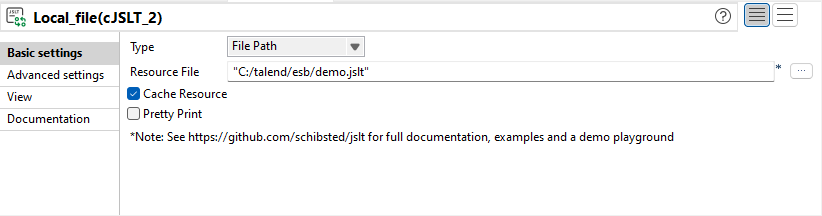 |
Big Data
| Fonctionnalité | Description |
|---|---|
| Support de Hive 3 dans les Jobs Standards | Vous pouvez à présent exécuter vos Jobs Standards avec Hive 3. Cette configuration s'effectue dans la vue Basic settings des composants Hive. Avec cette fonctionnalité, le nom de la propriété passe de Hive server à Hive version. 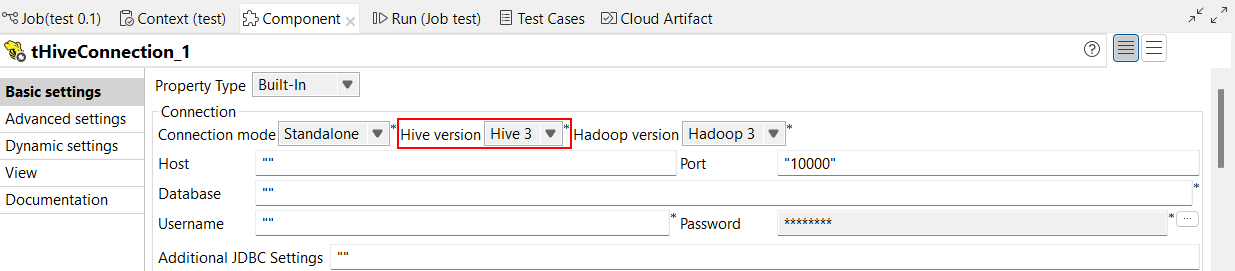 |
| Support de CDP Public Cloud Data Hub 7.2.18 avec Spark Universal 3.3.x | Vous pouvez à présent exécuter vos Jobs Spark Batch et Spark Streaming sur CDP Public Cloud Data Hub avec AWS, Azure et GCP utilisant Spark Universal avec Spark 3.3.x. Vous pouvez la configurer dans la vue Spark Configuration (Configuration de Spark) de vos Jobs Spark ou dans l'assistant de métadonnées Hadoop Cluster Connection (Connexion au cluster Hadoop). Lorsque vous sélectionnez ce mode, le Studio Talend est compatible avec CDP Public Cloud Data Hub version 7.2.18. Avec cette fonctionnalité, l'authentification par Knox est supportée, mais l'authentification par HBase n'est pas supportée. Pour plus d'informations concernant Spark Universal, consultez Support de Spark Universal pour les distributions Hadoop dans le Studio Talend. |
Intégration continue
| Fonctionnalité | Description |
|---|---|
| Le Builder Talend d'intégration continue a été mis à niveau en version 8.0.18 | Le Builder Talend d'intégration continue a été mis à niveau, passant de la version 8.0.17 à la version 8.0.18. Utilisez le Builder Talend d'intégration continue 8.0.18 et une version 3.6.3 ou supérieure de Maven dans vos commandes d'intégration continue ou dans vos scripts de pipelines, à partir de cette version mensuelle et jusqu'à la sortie d'une nouvelle version du Builder Talend d'intégration continue. |
Intégration de données
| Fonctionnalité | Description |
|---|---|
|
Support de la méthode d'authentification par compte dans le tFTPConnection, dans les Jobs Standards |
Le type d'authentification 'Password and account (Mot de passe et compte)' a été ajouté au composant tFTPConnection et vous permet d'accéder à un serveur FTP à l'aide du nom de compte associé à un·e utilisateur·trice spécifique. |
|
Support d'Azure Key Vault pour le chiffrement et le déchiffrement des colonnes dans les composants MS SQL, dans les Jobs Standards |
L'option 'Enable always encrypted (Activer le chiffrement permanent )' a été ajoutée à la famille de composants MS SQL et vous permet de chiffrer et protéger vos données à l'aide d'Azure Key Vault pour stocker vos secrets. |
|
Support de la normalisation des payloads JSON dans le tHTTPClient, dans les Jobs Standards |
L'option 'Normalize the JSON HTTP response (Normaliser la réponse HTTP JSON)' a été ajoutée au composant tHTTPClient et au connecteur Cloud HTTP Client. Elle vous permet de normaliser les incohérences dans les payloads JSON pour que les composants parsent correctement ces documents. |
Qualité de données
| Fonctionnalité | Description |
|---|---|
| tMatchGroup pour Spark Batch | Vous pouvez à présent utiliser le composant tMatchGroup dans le framework de Jobs Spark Batch. Ce composant crée des groupes d'enregistrements de données similaires dans toute source de données, même les gros volumes, à l'aide d'une ou plusieurs règles de mise en correspondance. Pour plus d'informations, consultez tMatchGroup. |