
L'algorithme T-Swoosh
-
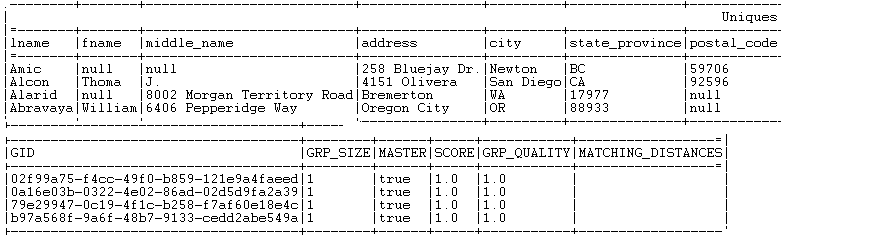
Uniques : liste les enregistrements dont la taille du groupe (distance minimale calculée dans l'enregistrement) est égale à 1.
-
Matches : liste les enregistrements dont la qualité du groupe est supérieure ou égale au seuil défini dans le champ Confident match threshold.
-
Suspects : liste les enregistrements dont la qualité du groupe est inférieure au seuil défini dans le champ Confident match threshold.
Ce scénario s'applique uniquement à Talend Data Management Platform, Talend Big Data Platform, Talend Real-Time Big Data Platform, Talend Data Services Platform et à Talend Data Fabric.
Configurer votre Job
Procédure
-
Reliez le tMatchGroup aux trois tLogRow à l'aide de liens Uniques, Matches et Suspects.
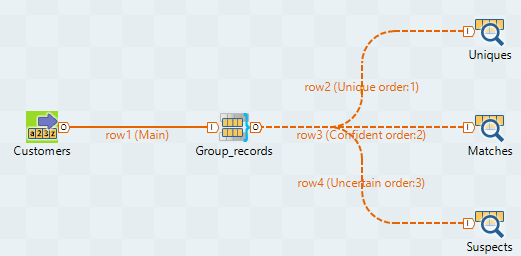
Configurer le composant d'entrée
Pourquoi et quand exécuter cette tâche
Les données d'entrée contiennent sept colonnes : lname, fname, middle_name, address, city, state_province et postal_code. Les données dans ce fichier d'entrée contiennent des problèmes, comme des doublons, des noms écrits de manières différentes ou mal orthographiés, des informations différentes pour un même client.
Procédure
- Double-cliquez sur le composant tFixedFlowInput pour afficher sa vue Basic settings.
- Sélectionnez Built-in et cliquez sur le bouton […] à côté de Edit Schema.
- Définissez les sept colonnes et cliquez sur OK.
- Sélectionnez Use Inline Content(delimited file).
- Renseignez les champs Row Separator et Field Separator.
- Saisissez les données d'entrée dans le champ Content.
Configurer le composant tMatchGroup
Procédure
-
Cliquez sur le bouton Chart afin d'exécuter le Job dans la configuration définie. Les résultats de la correspondance s'affichent directement dans l'assistant.
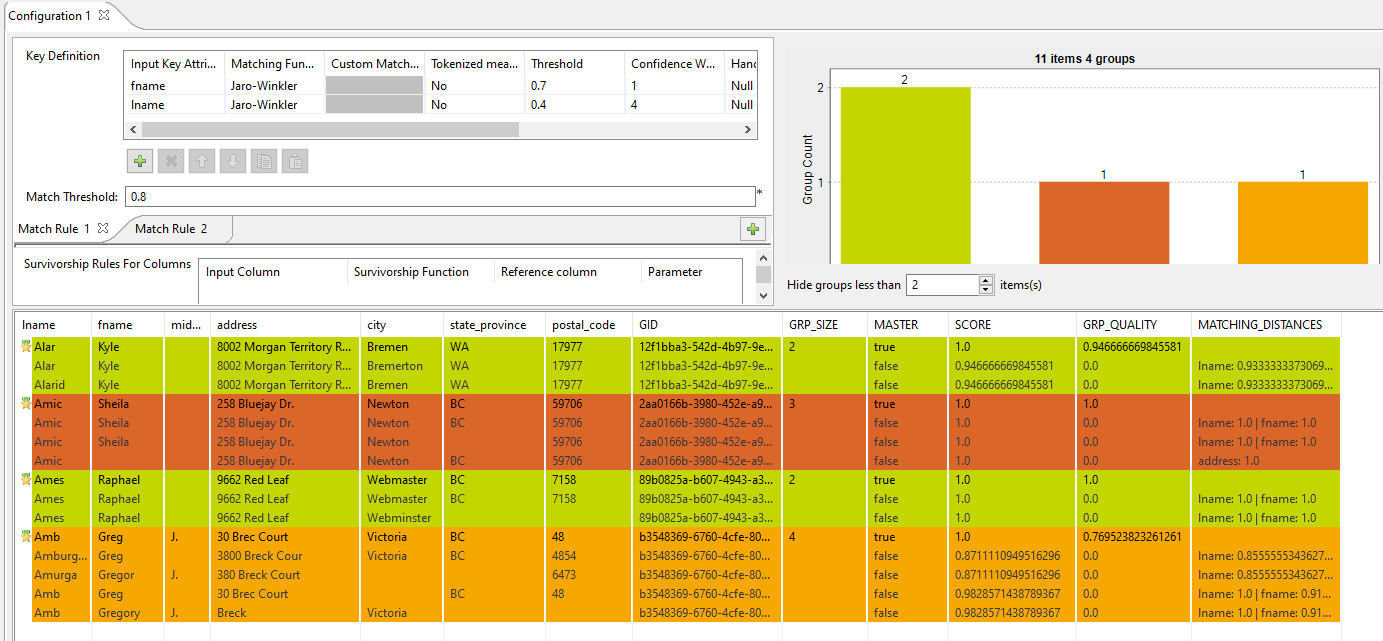 Le diagramme de rapprochement donne une vue globale des doublons dans les données analysées. La table des correspondances donne les détails des éléments de chaque groupe et les colore selon leur couleur dans le graphique des correspondances.Le Job effectue une opération de mise en correspondance de type OR. Il évalue les enregistrements par rapport à la règle. La colonne MATCHING_DISTANCES vous permet de voir la règle qui a été utilisée sur chaque enregistrement.
Le diagramme de rapprochement donne une vue globale des doublons dans les données analysées. La table des correspondances donne les détails des éléments de chaque groupe et les colore selon leur couleur dans le graphique des correspondances.Le Job effectue une opération de mise en correspondance de type OR. Il évalue les enregistrements par rapport à la règle. La colonne MATCHING_DISTANCES vous permet de voir la règle qui a été utilisée sur chaque enregistrement.Par exemple, dans le second groupe de données (brique rouge), le dernier enregistrement Amic est mis en correspondance par rapport à la seconde règle, en utilisant address1 comme attribut de clé. Les autres enregistrements du groupe, en revanche, ont mis en correspondance par rapport à la première règle utilisant lname et fname comme attributs de clés.
Comme vous pouvez le constater, la valeur de la colonne GRP_QUALITY peut être inférieure à la valeur du paramètre Match Threshold. Cela est possible car un groupe est créé à partir de paires d'enregistrements avec un score de rapprochement supérieur ou égal à la valeur de Match Threshold, mais les enregistrements ne sont pas tous comparés les uns aux autres, tandis que GRP_QUALITY prend en compte toutes les paires d'enregsitrements dans le groupe.
Finaliser et exécuter le Job
Procédure
- Double-cliquez sur chaque tLogRow pour afficher la vue Basic settings.
- Sélectionnez l'option Table (print values in cells of a table).
- Sauvegardez votre Job et appuyez sur F6 pour l'exécuter.
Résultats
Vous pouvez constater que les enregistrements sont regroupés dans trois groupes différents. Chaque enregistrement est listé dans un des trois groupes, selon la valeur du score de groupe, représentant la distance minimale calculée dans le groupe.
L'identifiant de chaque groupe, de type String, s'affiche dans la colonnes GID à côté de l'enregistrement correspondant. L'identifiant est du type de données Long pour les Jobs migrés depuis d'anciennes versions. Si vous souhaitez avoir un identifiant de groupe de type String, remplacez le composant tMatchGroup dans le Job importé par un tMatchGroup de la Palette du Studio Talend.
Le nombre d'enregistrements dans chacun des trois blocs de sortie est listé dans la colonne GRP_SIZE et calculé uniquement sur l'enregistrement maître. La colonne MASTER indique par true ou false si l'enregistrement correspondant est un enregistrement maître ou non. La colonne SCORE liste la distance calculée entre l'enregistrement d'entrée et l'enregistrement maître, selon les algorithmes de correspondance Jaro-Winkler et Jaro.
Le Job évalue les enregistrements par rapport à la première règle et les enregistrements qui correspondent à celle-ci ne sont pas évalués par rapport à la seconde règle.
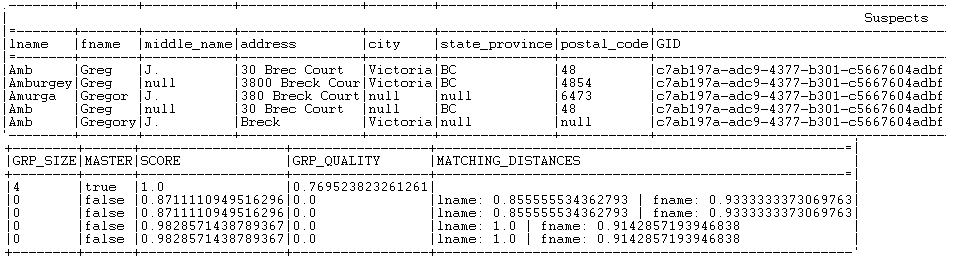
Tous les enregistrements dont le score de groupe est compris dans l'intervalle de correspondance, 0.95 ou 0.85 selon la règle appliquée et le seuil de confiance défini dans les paramètres avancés du tMatchGroup sont listés dans le flux de sortie Suspects.
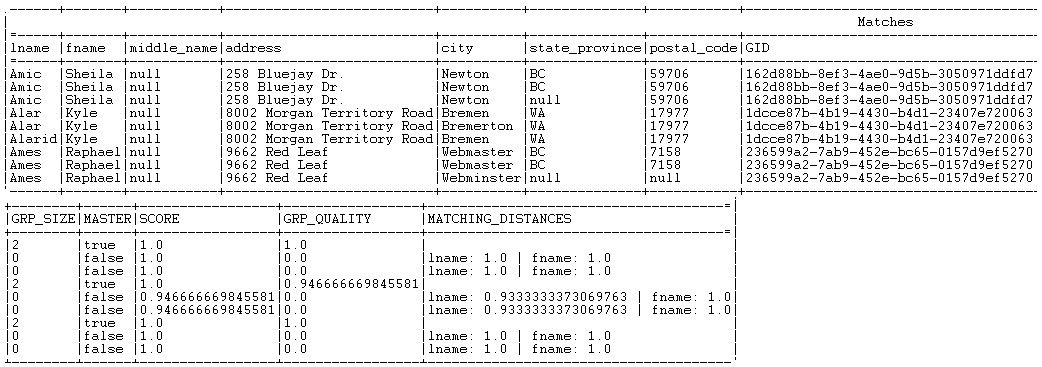
Tous les enregistrements dont le score de groupe est supérieur ou égal à l'une des probabilités de correspondance sont listés dans le flux de sortie Matches.
Tous les enregistrements dont la taille du groupe est égale à 1 sont listés dans le flux de sortie Uniques.
Pour un autre scénario regroupant les enregistrements de sortie en un seul flux de sortie, consultez Comparer les colonnes et regrouper dans le flux de sortie les enregistrements en doublon ayant la même clé fonctionnelle dans la section Identification.