You can generate a ready-to-use Job to deduplicate data in a specific file in the
Talend Studio metadata. Using the
component settings of this automatically-generated Job, you can choose to output the
duplicates and the unique values in two separate files or databases.
The sequence of deduplicating data in a specific file involves the following steps:
Selecting the file you want to deduplicate.
Choosing the columns on which to run the deduplicating Job.
If required, defining a blocking key to partition the data to be processed. A
blocking key is usually needed when there is a lot of data in the file.
Choosing where to write the unique and duplicated records.
Running the generated Job.
Procedure
On the menu bar, select Window > Show View.
The Show View dialog box is
displayed.
Expand the Help folder and then
select Cheat Sheets.
Click OK to close the dialog
box.
The Cheat Sheet panel is
displayed in Talend Studio.
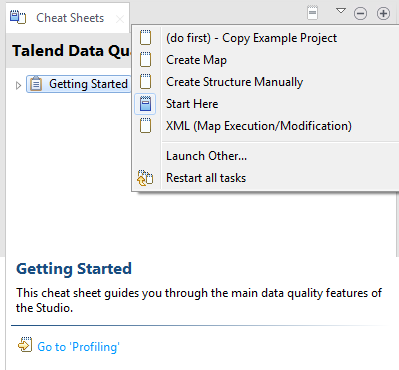
On the cheat sheet icon bar, click the drop-down
arrow, and from the menu select Launch
Other....
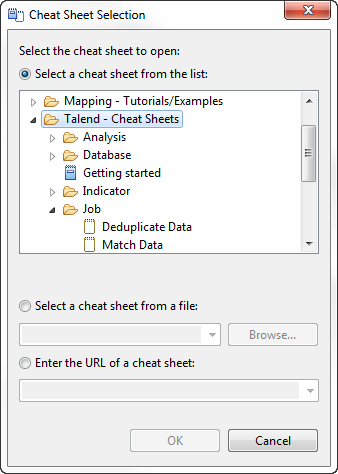
The Cheat Sheet
Selection dialog box is displayed.
Expand Talend - Cheat Sheets > Job, select Deduplicate Data and click
OK to close the dialog box.
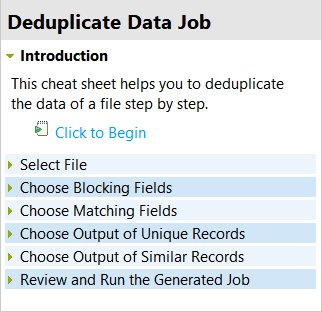
The corresponding page is displayed in the
Cheat Sheet panel. This page guides you through the steps
on how to create a ready-to-use Job on certain columns in a specific
file.
Read the introduction and then click Click to
Begin.
This expands the first step in the procedure: Select
File.
Read the instructions and then click Click to
perform.
The Input Type Select Dialog wizard opens to guide you
through the steps of creating the Job.
From the Type list field, select the file type on which
you want to run the Job and click OK.
A dialog box opens showing the database and file connections defined in
Talend Studio.
Select the file to cleanse from the metadata connection and click
OK.
The next step in the cheat sheet is expanded.
Read the instructions on how to choose the matching fields and then click
Click to perform to open the next view in the
wizard.
Follow the instructions and switch between the wizard and the steps in the cheat
sheet page till the last step: Review and Run the Generated
Job.
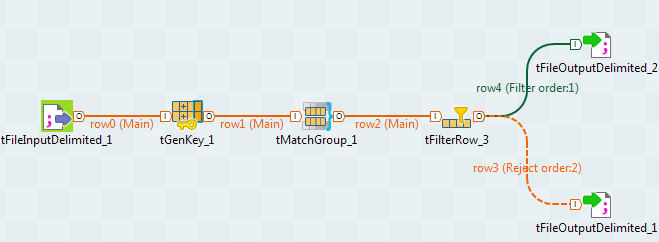
The wizard configures all the components and the metadata in the repository
according to the settings you defined in the wizard different views and
generates the Job. Talend Studio switches to the Integration perspective to display the generated Job that should look
something like the following:
Save the Job and press F6 to execute
it.
Results
The unique and duplicate values in the file are identified and stored in the defined
output files or databases. The generated Job is stored under the Job
Designs node in the Repository tree view.
Did this page help you?
If you find any issues with this page or its content – a typo, a missing step, or a technical error – please let us know!