
Processing a list of user devices using queries

Before you begin
-
You have previously created a connection to the system storing your source data.
Here, a Test connection.
-
You have previously added the dataset holding your source data.
Download and extract the file: query_language-devices.zip. It contains a .json hierarchical file with a survey about users devices including the type of devices, their purchase date, IP addresses, etc.
-
You also have created the connection and the related dataset that will hold the processed data.
Here, a file stored on an S3 bucket.
Procedure
-
Click ADD SOURCE to open
the panel allowing you to select your source data, here a survey about user
devices with hierarchical data.
Example

-
Click
 and add a Data Shaping Language processor to the
pipeline. The Configuration panel opens.
and add a Data Shaping Language processor to the
pipeline. The Configuration panel opens.
-
Click Save to save your configuration.
The preview allows you to visualize the new structure: now that the structure is flattened, more records are outputted and only the devices bought after January 1st, 2015 are displayed.

-
Click and add a Filter processor to the pipeline. The
Configuration panel opens.
-
In the Filter area:
-
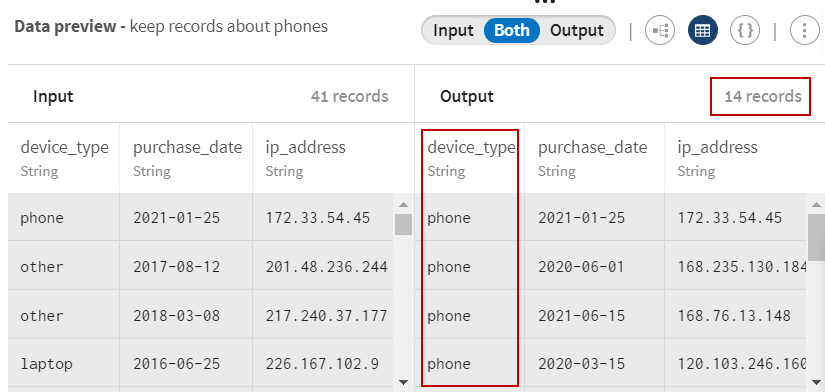
Click Save to save your configuration. The preview
allows you to visualize the records that match the filtering criteria (users
with phones).
-
Click Save to save your configuration. The preview
allows you to visualize the records that match the filtering criteria (users
with phones).
Results
Your pipeline is being executed, the data is processed according to the conditions you have stated using the query language and the output is sent to the target system you have indicated.