Converting the tokenized text to the CoNLL format
To be able to learn a classification model from a text, you must divide this text
into tokens and convert it to the CoNLL format using
tNormalize.
Procedure
-
Double-click the tNLPPreprocessing component to open its
Basic settings view and define its properties.
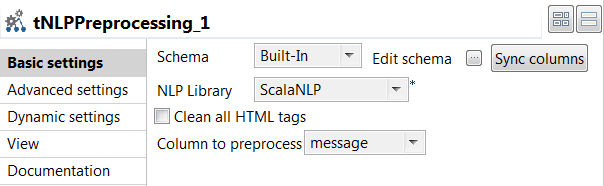
- Click Sync columns to retrieve the schema from the previous component connected in the Job.
- From the NLP Library list, select the library to be used for tokenization. In this example, ScalaNLP is used.
-
Click Edit schema to add the
tokens column in the output schema because this is
the column to be normalized, and click OK to
validate.

-
Double-click the tNormalize component to open its Basic settings
view and define its properties.
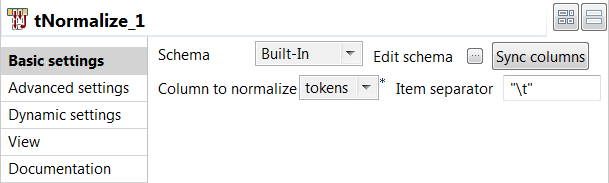
- Click Sync columns to retrieve the schema from the previous component connected in the Job.
- From the Column to normalize list, select tokens.
- In the Item separator field, enter "\t" to separate tokens using a tab in the output file.
-
Double-click the tFileOutputDelimited component to open
its Basic settings view and define its properties.
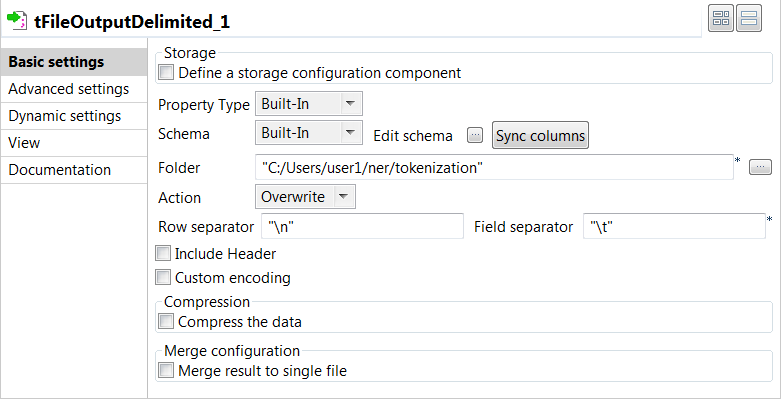
- Click Sync columns to retrieve the schema from the previous component connected in the Job.
- In the Folder field, specify the path to the folder where the CoNLL files will be stored.
- In the Row Separator field, enter "\n".
- In the Field Separator field, enter "\t" to separate fields with a tab.
Results
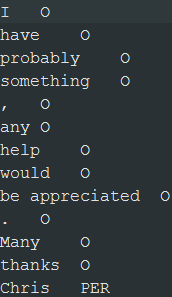
The output files are created in the specified folder. The files contain a single column with one token per row.
You can then manually label person names with PER and the other tokens with O before you can learn a classification model from this text data: