
Verarbeiten von Streamingdaten zu Flugzeugen

Vorbereitungen
-
Sie haben zuvor eine Verbindung zu dem System erstellt, in dem die Quelldaten gespeichert sind.
-
Sie haben zuvor den Datensatz hinzugefügt, der die Quelldaten enthält.
In diesem Beispiel Streamingdaten zu Flugzeugen, d. h. Flugzeug-ID, Position und Zeitstempel.
Um dieses Szenario besser zu verstehen, finden Sie nachstehend das AVRO-Schema der im Szenario verwendeten Streamingdaten:{ "type": "record", "name": "aircrafts", "fields": [ {"name": "Id", "type": "int"}, {"name": "PosTime", "type": "long"}, {"name": "Lat", "type": "double"}, {"name": "Long", "type": "double"}, {"name": "Op", "type": "string"} ] }Hierbei gilt: Id entspricht der Flugzeug-ID, PosTime dem Zeitstempel der Position, Lat/Long dem Breiten-/Ländengrad des Flugzeugs und Op den Fluggesellschaften.
-
Sie haben außerdem die Verbindung und den zugehörigen Datensatz erstellt, der die verarbeiteten Daten aufnehmen soll.
In diesem Beispiel eine MySQL-Tabelle.
Prozedur
-
Klicken Sie auf ADD SOURCE (QUELLE HINZUFÜGEN), um ein Fenster zu öffnen, in dem Sie Ihre Quelldaten auswählen können, in diesem Beispiel das Flugzeug-Topic in Kafka.
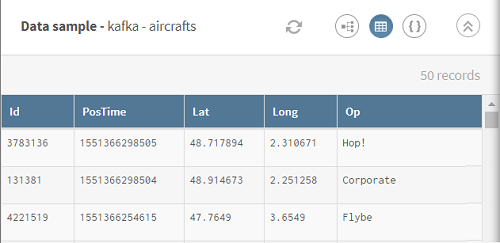
-
Klicken Sie auf
 und fügen Sie einen Prozessor vom Typ Window (Fenster) zur Pipeline hinzu. Daraufhin wird das Konfigurationsfenster geöffnet.
und fügen Sie einen Prozessor vom Typ Window (Fenster) zur Pipeline hinzu. Daraufhin wird das Konfigurationsfenster geöffnet.
-
Klicken Sie auf und fügen Sie einen Prozessor vom Typ Aggregate (Aggregieren) zur Pipeline hinzu. Daraufhin wird das Konfigurationsfenster geöffnet.
-
Klicken Sie auf und fügen Sie einen Prozessor vom Typ Field Selector (Feldauswahl) zur Pipeline hinzu. Daraufhin wird das Konfigurationsfenster geöffnet.
-
Klicken Sie auf und fügen Sie einen Prozessor vom Typ Python 3 zur Pipeline hinzu. Daraufhin wird das Konfigurationsfenster geöffnet.
-
(Optional) Sehen Sie sich die Vorschau des Prozessors vom Typ Python 3 an, um Ihre Daten zu prüfen.
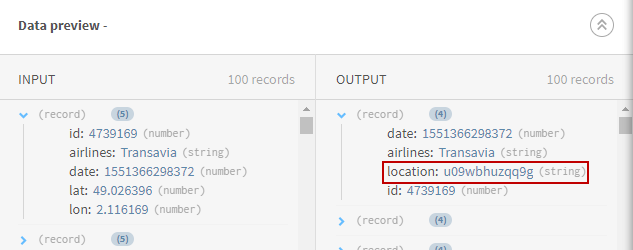
Ergebnisse
Ihre Streaming-Pipeline wird ausgeführt und bleibt aktiv, bis Sie sie explizit beenden. Die Flugzeugdaten werden geändert und die berechneten Geohash-Daten an das von Ihnen angegebene Zielsystem gesendet.