
Rank — функция диаграммы
Rank() оценивает строки диаграммы в выражении и для каждой строки отображает относительное положение значения измерения, оцененного в выражении. При оценке выражения эта функция сравнивает результат с результатом других строк, содержащих текущий сегмент столбца, и возвращает ранжирование текущей строки в сегменте.
Сегменты столбцов
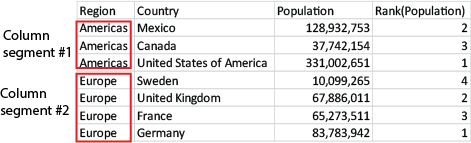
Для диаграмм, за исключением таблиц, сегмент текущего столбца определяется так, как он отображается в эквиваленте прямой таблицы диаграммы.
Синтаксис:
Rank([TOTAL] expr[, mode[, fmt]])
Возвращаемые типы данных: двойное значение
Аргументы:
| Аргумент | Описание |
|---|---|
| expr | Выражение или поле, содержащее данные для измерения. |
| mode | Указывает числовое представление результата функции. |
| fmt | Указывает текстовое представление результата функции. |
| TOTAL |
Если диаграмма имеет одно измерение, или если выражению предшествует квалификатор TOTAL, функция выполняет оценку по всему столбцу. Если таблица или эквивалент таблицы имеют несколько вертикальных измерений, текущий сегмент столбца будет включать только строки с теми же значениями, что и текущая строка во всех столбцах измерений, кроме столбца с последним измерением в межполевом порядке сортировки. |
Ранжирование возвращается в виде двойного значения, которое, в случае если каждая строка имеет уникальное ранжирование, будет представлять собой целое число от 1 до количества строк в текущем сегменте столбца.
В случае, если несколько строк имеют одно и то же ранжирование, текстовое и числовое представления могут управляться параметрами mode и fmt.
mode
Второй аргумент, mode, может принимать следующие значения:
| Значение | Описание |
|---|---|
| 0 (по умолчанию) |
Если все ряды в совместно используемой группе выпадают на нижнюю часть среднего значения всего ранжирования, все строки получают низший ряд в совместно используемой группе. Если все ряды в совместно используемой группе выпадают на верхнюю часть среднего значения всего ранжирования, все строки получают высший ряд в совместно используемой группе. Если ряды в совместно используемой группе охватывают среднее значение всего ранжирования, все строки получают значение, соответствующее среднему значению верхнего и нижнего ранжирования во всем сегменте столбца. |
| 1 | Нижний ряд на всех строках. |
| 2 | Средний ряд на всех строках. |
| 3 | Высший ряд на всех строках. |
| 4 | Самый нижний ряд на первой строке, увеличенный на один для каждой строки. |
fmt
Третий аргумент, fmt, может принимать следующие значения:
| Значение | Описание |
|---|---|
| 0 (по умолчанию) | Низкое значение - высокое значение во всех строках (например, 3–4). |
| 1 | Нижнее значение на всех строках. |
| 2 | Нижнее значение на первой строке, пустое на следующих строках. |
Порядок строк mode 4 и fmt 2 определяется порядком сортировки измерений диаграммы.
Примеры и результаты:
Создайте две визуализации. Одну с измерениями Product и Sales, а вторую с измерениями Product и UnitSales. Добавьте меры, как показано на следующей таблице.
| Примеры | Результаты |
|---|---|
|
Пример 1. Создайте таблицу с измерениями Customer и Sales и мерой Rank(Sales) |
Результат зависит от порядка сортировки измерений. Если таблица сортируется по элементу Customer, в таблице перечисляются все значения элемента Sales для элемента Astrida, затем для элемента Betacab и т. д. В результатах для элемента Rank(Sales) будет отображено значение 10 для значения Sales, равного 12, 9 для значения Sales, равного 13 и т. д. со значением ранжирования 1, возвращенного для значения Sales, равного 78. Следующий сегмент столбца начинается с элемента Betacab, для которого первое значение элемента Sales в сегменте равно 12. Значение ранжирования элемента Rank(Sales) дано для этого как 11. Если таблица сортируется по элементу Sales, сегменты столбца состоят из значений элемента Sales и соответствующего элемента Customer. Поскольку существует два значения элемента Sales, равных 12, (для Astrida и Betacab), значение элемента Rank(Sales) для этого сегмента столбца составляет 1–2 для каждого значения элемента Customer. Это потому, что существуют два значения элемента Customer, где элемент Sales равен 12. Если бы было 4 значения, результат был бы 1–4 для всех строк. На этом примере видно, как выглядит результат для значения по умолчанию (0) аргумента fmt. |
| Пример 2. Замените измерение Customer измерением Product и добавьте меру Rank(Sales,1,2) | Будет возвращено значение 1 в первой строке в сегменте каждого столбца, а все остальные строки останутся пустыми, поскольку для аргументов mode и fmt установлены значения 1 и 2 соответственно. |
Результаты для примера 1 — таблица отсортирована по значению Customer:
| Customer | Sales | Rank(Sales) |
|---|---|---|
| Astrida | 12 | 10 |
| Astrida | 13 | 9 |
| Astrida | 20 | 8 |
| Astrida | 22 | 7 |
| Astrida | 45 | 6 |
| Astrida | 46 | 5 |
| Astrida | 60 | 4 |
| Astrida | 65 | 3 |
| Astrida | 70 | 2 |
| Astrida | 78 | 1 |
| Betcab | 12 | 11 |
Результаты для примера 1 — таблица отсортирована по значению Sales:
| Customer | Sales | Rank(Sales) |
|---|---|---|
| Astrida | 12 | 1-2 |
| Betacab | 12 | 1-2 |
| Astrida | 13 | 1 |
| Betacab | 15 | 1 |
| Astrida | 20 | 1 |
| Astrida | 22 | 1-2 |
| Betacab | 22 | 1-2 |
| Betacab | 24 | 1-2 |
| Canutility | 24 | 1-2 |
Данные, используемые в примерах:
ProductData:
Load * inline [
Customer|Product|UnitSales|UnitPrice
Astrida|AA|4|16
Astrida|AA|10|15
Astrida|BB|9|9
Betacab|BB|5|10
Betacab|CC|2|20
Betacab|DD|0|25
Canutility|AA|8|15
Canutility|CC|0|19
] (delimiter is '|');
Sales2013:
crosstable (Month, Sales) LOAD * inline [
Customer|Jan|Feb|Mar|Apr|May|Jun|Jul|Aug|Sep|Oct|Nov|Dec
Astrida|46|60|70|13|78|20|45|65|78|12|78|22
Betacab|65|56|22|79|12|56|45|24|32|78|55|15
Canutility|77|68|34|91|24|68|57|36|44|90|67|27
Divadip|57|36|44|90|67|27|57|68|47|90|80|94
] (delimiter is '|');