Data quality for connection-based datasets
To benefit from semantic types discovery and data quality readings on your connection-based datasets, you need to set up an important prerequisite with your data connections in the context of data products.
-
Data quality is supported in both pullup and pushdown modes for Snowflake datasets
-
Data quality is supported in pullup mode for the datasets based on following databases:
-
Amazon Athena
-
Amazon Redshift
-
Apache Hive
-
Apache Phoenix
-
Apache Spark
-
Azure SQL Database
-
Azure Synapse Analytics
-
Cassandra
-
Cloudera Impala
-
Couchbase
-
Databricks
-
DynamoDB
-
Google BigQuery
-
Marketo
-
Microsoft SQL Server
-
MySQL Entreprise Edition
-
Oracle
-
PostgreSQL
-
Presto
-
SAP Hana
-
Snowflake
-
Teradata
-
Connection settings
In order for you to create datasets from a connection, and later have access to their schema and quality in the dataset overview and data product overview, you need to set up the same connection in both Qlik Talend Data Integration, and in Qlik Cloud 분석.
Let's say you want to bring data stored in a database, add it to your Catalog as datasets, and group them in a data product that you will use for an analytics app.
-
In Qlik Talend Data Integration > Connections, click Create connection.
-
Configure your access to the database using the credentials of a user that has sufficient permissions and access to the tables you want to import.
-
In Qlik Cloud 분석 click Create, and then Data connection.
-
Configure your access to the same Snowflake database as previously, using the credentials of the same user ideally, or one that has at least the READ permissions on the tables.
-
(for Snowflake only) In the Role field, you must enter a role that corresponds to an existing role created in the Snowflake database, and that has the following privileges on these objects.
-
USAGE on WAREHOUSE
-
USAGE on DATABASE
-
USAGE on SCHEMA
-
CREATE TABLE on SCHEMA
-
CREATE FUNCTION on SCHEMA
-
CREATE VIEW on SCHEMA
-
SELECT on TABLE
-
-
Back on the Qlik Talend Data Integration homepage, click Projects and then Create data project.
-
Use your connection from step 2 as source for your project and start building your pipeline. See 데이터 파이프라인 만들기 for more information.
-
At any point in your pipeline, select a data task, go to Settings, and then the Catalog tab where you can select the Publish to Catalog checkbox.
It means that this version of the dataset will be published to the Catalog when the data project is prepared and run. It's also possible to check this option at the project level.
-
Run your data project.
After running your data project, the new dataset is added to the Catalog and you will be able to access quality indicators and more details about their content. This configuration also makes it possible to use the datasets as a source for analytics apps.
You can add as many datasets as necessary before building your data product. Since the Catalog can be accessed from both the Qlik Talend Data Integration hub, and Qlik Analytics Services hub, you can open your datasets in your preferred location, and the right connection will be used depending on the context.
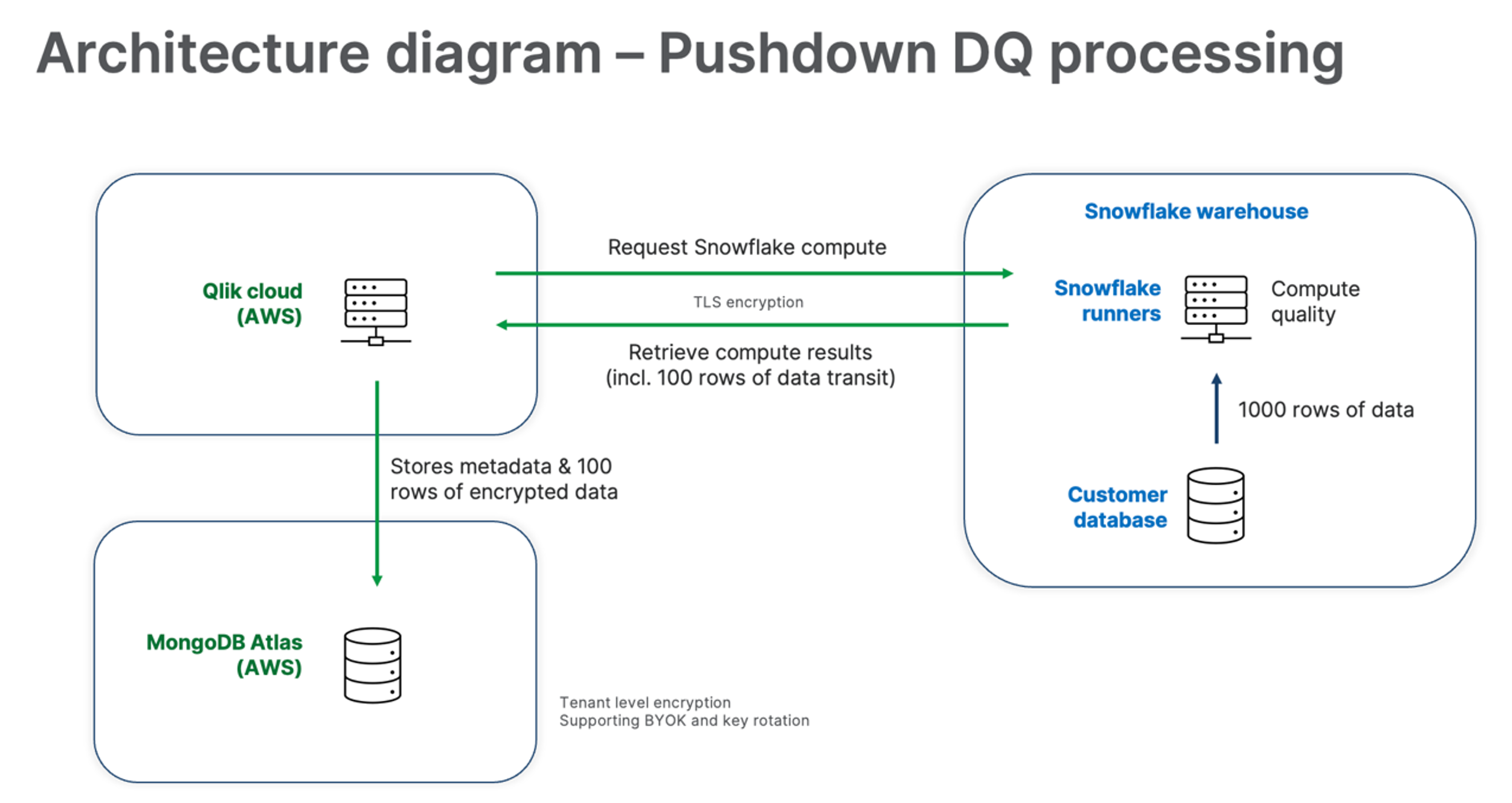
Quality compute in pullup/pushdown
Using the Compute or Refresh button on the Overview of your dataset triggers a quality calculation on a sample of 1,000 rows of the database.
This operation happens in pullup mode by default. For Snowflake datasets, this operation can happen both in pullup mode (default), or in pushdown mode, on the Snowflake side.
A sample of 100 rows is then sent back to Qlik Cloud, where you can display it as a preview with up to date semantic types and validity and completeness statistics. This sample is then stored on MongoDB.
The following diagram summarizes the data quality processing operation in pushdown mode.