
Introduction
Qlik Compose provides an all-in-one purpose built automation solution for creating an agile data warehouse and/or ingesting data from multiple sources to your data lake for further downstream processing. To this end, Qlik Compose offers two project types: Data Warehouse and Data Lake. This introduction will take a closer look at how these projects can help your organization overcome the hurdles typically faced when confronted with the challenge of setting up and maintaining an agile data warehouse, or when faced with challenge of ingesting data from multiple source to a single analytics-ready storage system.
Data warehouse projects
Traditional methods of designing, developing, and implementing data warehouses require large time and resource investments. The ETL stand-up development effort alone – multi-month and error-prone with prep times of up to 80 percent and expertise from specialized developers – often means your data model is out of date before your BI project even starts. Plus, the result of a traditional data warehouse design, development, and implementation process is often a system that can’t adapt to continually changing business requirements. Yet modifying your data warehouse diverts skilled resources from your more innovation-related projects. Consequently, your business ends up with your data warehouse becoming a bottleneck as much as an enabler of analytics.
Qlik Compose data warehouse projects allows you to automate these traditionally manual, repetitive data warehouse tasks: design, development, testing, deployment, operations, impact analysis, and change management. Qlik Compose automatically generates the task statements, data warehouse structures, and documentation your team needs to efficiently execute projects while tracking data lineage and ensuring integrity. Using Qlik Compose, your IT teams can respond fast – in days – to new business requests, providing accurate time, cost, and resource estimates. Then once projects are approved, your IT staff can finally deliver completed data warehouses, data marts, and BI environments in far less time.
Data warehouse projects architecture
The process is illustrated in the following diagram and described below:
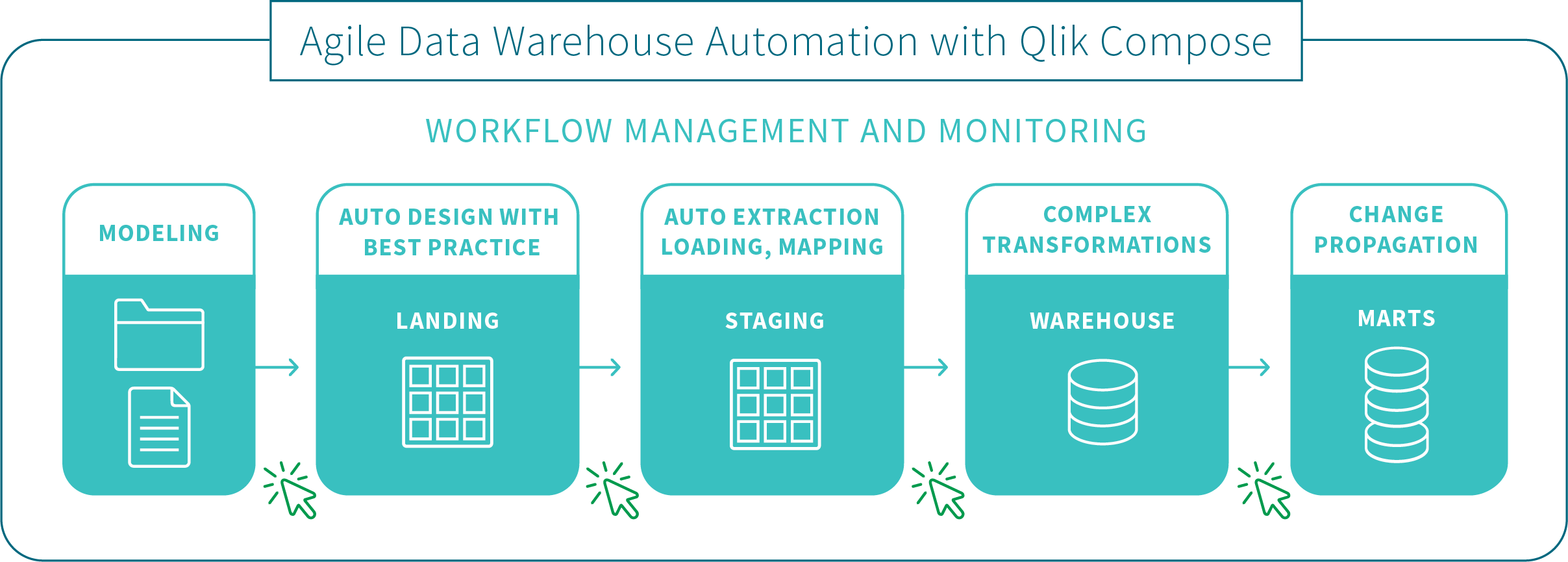
Key features
The comprehensive set of automation features in our Qlik Compose solution simplifies data warehousing projects. It eliminates the cumbersome and error-prone manual coding required by legacy data warehouse design and implementations’ many repetitive steps. In addition, our solution includes the operational features your business needs for ongoing data warehouse and data mart maintenance.
| Automation Features | Operational Features |
|---|---|
|
|
Data lake projects
Leverage Qlik Compose data lake projects to automate your data pipelines and create analytics-ready data sets. By automating data ingestion, schema creation, and continual updates, organizations realize faster time-to-value from their existing data lake investments.
Easy data structuring and transformation
An intuitive and guided user interface helps you build, model and execute data lake pipelines. Automatically generate schemas and Hive Catalog structures for operational data stores (ODS) and historical data stores (HDS) without manual coding.
Continuous updates
Be confident that your ODS and HDS accurately represent your source systems.
- Use change data capture (CDC) to enable real-time analytics with less administrative and processing overhead.
- Efficiently process initial loading with parallel threading.
- Leverage time-based partitioning with transactional consistency to ensure that only transactions completed within a specified time are processed.
Historical data store
Derive analytics-specific data sets from a full historical data store (HDS).
- New rows are automatically appended to HDS as data updates arrive from source systems.
- New HDS records are automatically time-stamped, enabling the creation of trend analysis and other time-oriented analytic data marts.
- Supports data models that include Type-2, slowing changing dimensions.
Data lake project architecture
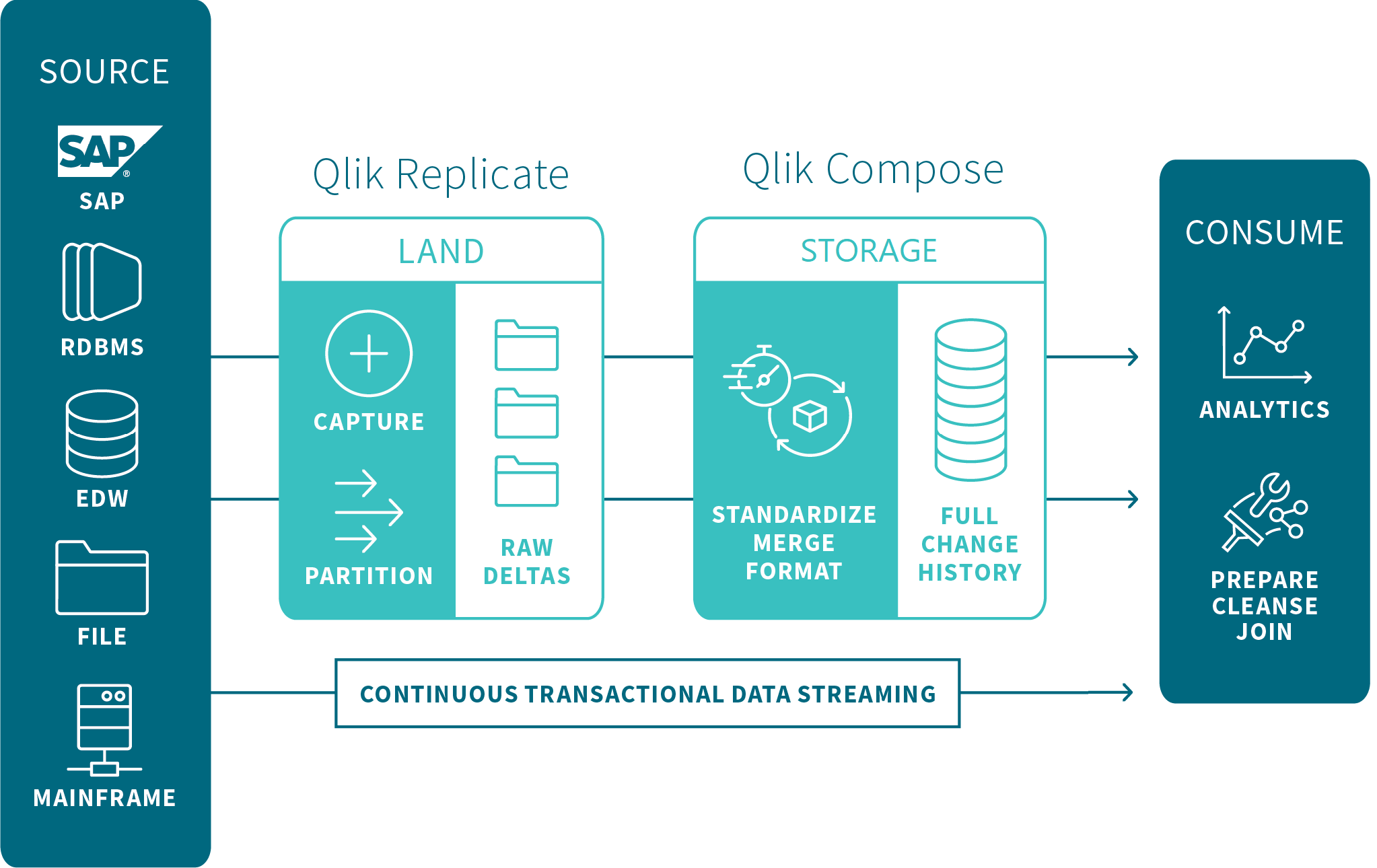
The flow is as follows:
-
Land: The source tables are loaded into the Landing Zone using Qlik Replicate or other third-party replication tools.
When using Qlik Replicate to move the source table to the Landing Zone, you can define either a Full Load replication task or a Full Load and Store Changes task to constantly propagate the source table changes to the Landing Zone in write-optimized format.
- Store: After the source tables are present in the Landing Zone, Compose auto-generates metadata based on the data source(s). Once the metadata and the mappings between the tables in the Landing Zone and the Storage Zone have been finalized, Compose creates and populates the Storage Zone tables in read-optimized format, ready for consumption by downstream applicaitons.
It should be noted that even though setting up the initial project involves both manual and automatic operations, once the project is set up, you can automate the tasks by designing a Workflow in Compose and/or utilizing the Compose scheduler.