
配置输入数据
tFileInputDelimited 组件配置为将数据从 DBFS 加载到作业中。
开始之前
-
源文件 movies.csv 和 directors.txt 已如 将文件上传到 DBFS (Databricks 文件系统) 中所述上传到 DBFS。
-
movie.csv 文件的元数据已在 Repository (存储库) 中 File delimited (分隔文件) 节点下设置。
如果尚未执行此操作,请参阅准备影片元数据以创建元数据。
步骤
-
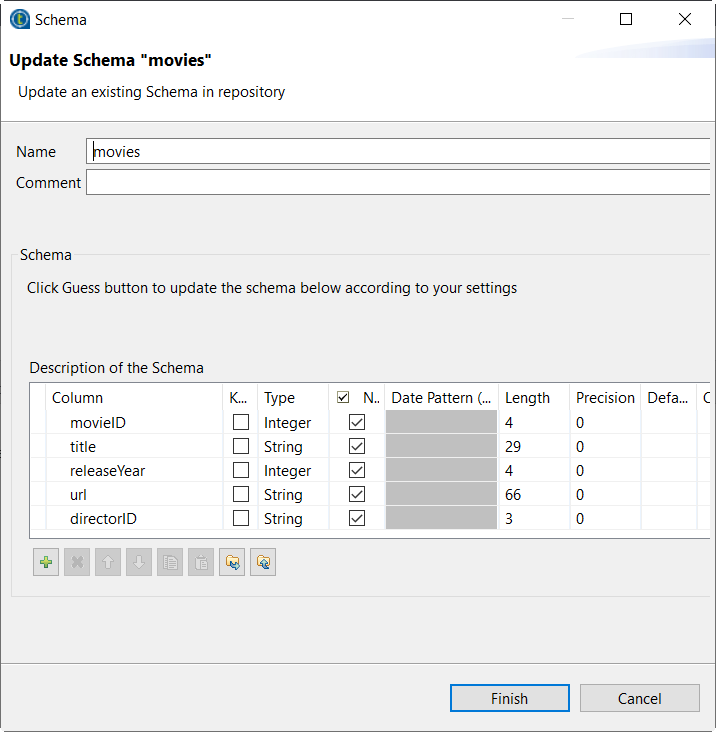
双击该 schema 元数据节点,打开其向导。
-
单击
 按钮,将 schema 导出到本地目录。
按钮,将 schema 导出到本地目录。
-
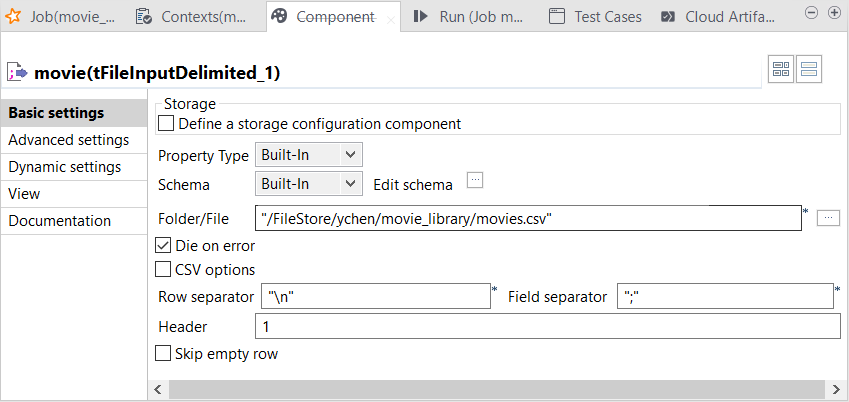
双击 movie (影片) tFileInputDelimited 组件打开其 Component (组件) 视图。
-
单击 Edit schema (编辑 schema) 以打开 schema 编辑器,然后单击
 按钮以导入之前从 Repository (存储库) 的 File delimited (分隔文件) 元数据中导出的影片 schema。
按钮以导入之前从 Repository (存储库) 的 File delimited (分隔文件) 元数据中导出的影片 schema。
-
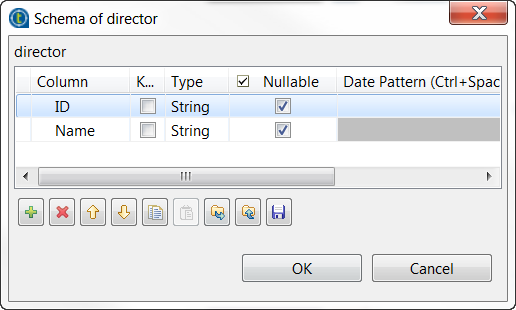
双击 director (导演) tFileInputDelimited 组件打开其 Component (组件) 视图。

-
单击 [+] 按钮两次添加两行,并在 Column (列) 列中,将其分别重命名为 ID 和 Name (名称)。
结果
输入组件现在即会配置为将影片数据和导演数据加载到作业。