ビッグデータジョブの来歴を有効化
Cloudera Navigatorを使ってデータ来歴を設定
Cloudera Navigatorに対するサポートがTalend Sparkジョブに追加されました。
ジョブの実行にCloudera V5.5+を使用している場合は、Cloudera Navigatorを利用して特定のデータフローの来歴をトレースし、このジョブに使用されているコンポーネントおよびコンポーネント間のスキーマの変更を含め、このデータがSparkジョブによってどう生成されたかを確認できます。
CDP Private Cloud BaseやCDP Public Cloudを使ってジョブを実行している場合は、Apache Atlasのご使用をお勧めします。CDPダイナミックディストリビューションを使用している場合は、Cloudera NavigatorではなくApache Atlasが使われます。詳細は、Atlasを使ったデータ来歴の設定をご覧ください。
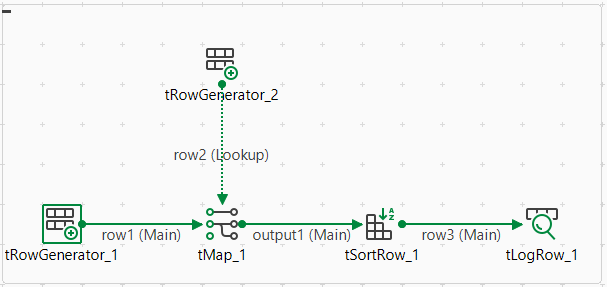
たとえば、以下のジョブをデザインし、それに関する来歴情報を生成するとします。
- [Run] (実行)をクリックしてビューを開き、[Hadoop configuration] (Hadoopの設定)タブをクリックします。Sparkジョブの場合、使用するタブは[Spark configuration] (Spark設定)です。
- [Distribution] (ディストリビューション)リストからClouderaを選択し、[Version] (バージョン)リストからCloudera 5.5を選択します。[Use Cloudera Navigator] (Cloudera Navigatorの使用)チェックボックスが表示されます。
このオプションを有効にしたら、以下のパラメーターを設定する必要があります。
-
[Username] (ユーザー名)および[Password] (パスワード): Cloudera Navigatorへの接続に使用する認証情報です。
-
Cloudera Navigator URL: Cloudera Navigatorの接続先を入力します。
-
[Cloudera Navigator Metadata URL] (Cloudera NavigatorメタデータURL): ナビゲーターメタデータの場所を入力します。
-
[Activate the autocommit option] (自動コミットオプションの有効化): このジョブの実行の最後にCloudera Navigatorが現在のジョブの来歴を生成するよう設定する場合は、このチェックボックスをオンにします。
このオプションを指定すると、Cloudera NavigatorはHDFSファイルとディレクトリー、HiveクエリーまたはPigスクリプトなど、利用可能なすべてのエンティティの来歴を生成するように強制されるため、ジョブの実行速度の低下を招くことから本番環境には推奨されません。
- [Kill the job if Cloudera Navigator fails] (Cloudera Navigatorにエラーが発生したらジョブを強制終了): このチェックボックスをオンにすると、Cloudera Navigatorへの接続が失敗した時にジョブの実行が停止されます。それ以外の場合は、解除してジョブが実行を継続できるようにしてください。
-
Disable SSL validation (SSL認証を無効化): SSL認証プロセスを経ずにCloudera Navigatorに接続することをジョブに指示する場合は、このチェックボックスをオンにします。
この機能は、ジョブのテストを容易にするためのものですが、プロダクションクラスターで使用することは推奨されません。
-
この時点までに、Cloudera Navigatorへの接続がセットアップ済みとなっています。このジョブを実行する時は、Cloudera Navigator内に来歴が自動的に生成されています。
ジョブを正しく実行するには、[Spark configuration] (Spark設定)タブでさらにその他のパラメーターを設定する必要があります。
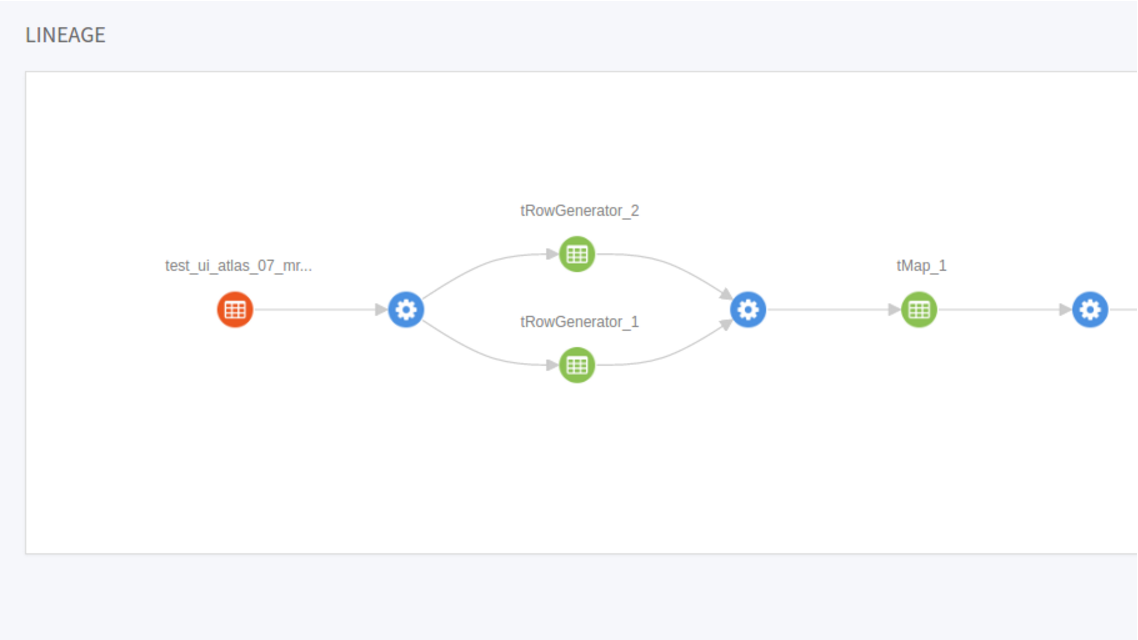
ジョブの実行が完了したら、このジョブによって書かれたデータをCloudera Navigatorで検索し、Cloudera Navigatorでこのデータの来歴を確認します。
この来歴グラフをTalend Studio内のジョブと比較すると、すべてのコンポーネントがこのグラフに表示されていることが確認できます。また、各コンポーネントのアイコンを展開し、使用されているスキーマを読むことができます。
Cloudera NavigatorではClouderaSDKライブラリー (英語のみ)を使用して機能が提供されるため、このSDKライブラリーのバージョンと互換性があるはずです。Cloudera Navigatorのバージョンは、ClouderaディストリビューションによってインストールされたCloudera Managerによって決まります。また、Navigatorのバージョンに基づいて、対応しているSDKが自動的に使用されます。
ただし、Cloudera Navigatorのバージョンによっては、対応しているSDKのバージョンがない場合があります。Cloudera SDKのバージョンと互換性があるNavigatorのバージョンの詳細は、Cloudera NavigatorとSDKバージョンの互換性 (英語のみ)に関するClouderaのドキュメンテーションをご覧ください。
Talend StudioでサポートされているCloudera Navigatorバージョンの詳細は、Talendジョブの対応Cloudera Navigatorバージョンをご覧ください。
Atlasを使ってデータ来歴を設定
Apache Atlasに対するサポートがTalend Sparkジョブに追加されました。
ジョブの実行にHortonworks Data Platform V2.4以降を使用しており、HortonworksクラスターにApache Atlasがインストールされている場合は、Atlasを利用して特定のデータフローの来歴をトレースし、このジョブに使用されているコンポーネントおよびコンポーネント間のスキーマの変更を含め、このデータがSparkジョブによってどう生成されたかを確認できます。ClouderaクラスターにApache Atlasがインストールされており、CDP Private Cloud BaseまたはCDP Public Cloudを使って自分のジョブを実行している場合は、ジョブの実行でAtlasを使うこともできます。
- Hortonworks Data Platform V2.4の場合、Talend StudioによるサポートはAtlas 0.5のみになります。
- Hortonworks Data Platform V2.5の場合、Talend StudioによるサポートはAtlas 0.7のみになります。
- Hortonworks Data Platform V3.14の場合、Talend StudioによるサポートはAtlas 1.1のみになります。
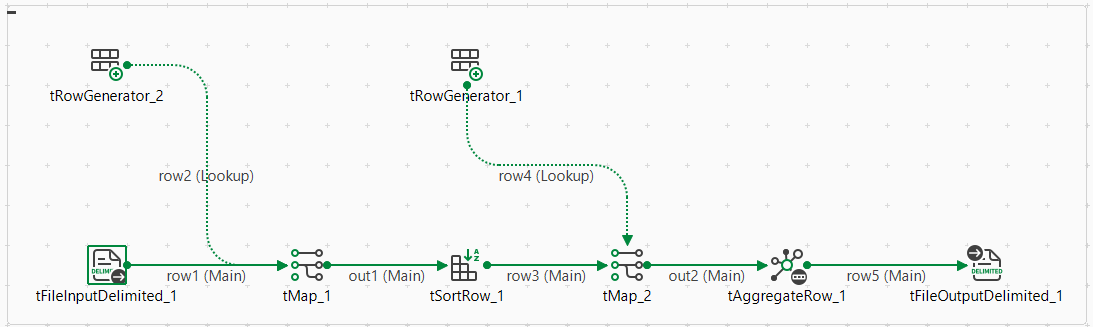
たとえば以下のSpark Batchジョブをデザインし、そこでAtlas内にそれに関する来歴情報を生成するとします。
このジョブでは、入力データの生成にtRowGeneratorを使用し、データ処理にtMapとtSortRowを使用し、データを別の形式に出力するのに他のコンポーネントを使用します。
- [Run] (実行)をクリックしてビューを開き、[Spark configuration] (Spark設定)タブをクリックします。
- [Distribution] (ディストリビューション)リストと[Version] (バージョン)リストからHortonworksディストリビューションを選択します。[Use Atlas] (Atlasを使用)チェックボックスが表示されます。
このオプションを有効にしたら、以下のパラメーターを設定する必要があります。
-
Atlas URL: Atlasの接続先を入力します。http://name_of_your_atlas_node:portとなる場合がほとんどです。
-
[Username] (ユーザー名)および[Password] (パスワード)フィールドに、Atlasにアクセスするための認証情報を入力します。
-
Atlas設定フォルダーの設定: AtlasクラスターにSSLや読み取りタイムアウトなどのカスタムプロパティが含まれている場合は、このチェックボックスをオンにし、表示されるフィールドにローカルマシンのディレクトリーを入力し、このディレクトリーにAtlasのatlas-application.propertiesファイルを入れます。こうすることでジョブが有効になり、これらのカスタムプロパティを利用できるようになります。
この設定ファイルは、クラスターの管理者に尋ねる必要があります。このファイルの詳細は、[Atlas configuration] (Atlas設定) (英語のみ)のクライアント設定セクションをご覧ください。
- [Die on error] (エラー発生時に強制終了): Atlasへの接続の問題など、Atlas関連の問題が発生した場合にジョブの実行を停止する場合は、このチェックボックスをオンにします。それ以外の場合は、解除してジョブが実行を継続できるようにしてください。
-
この時点までに、Atlasへの接続がセットアップ済みとなっています。このジョブを実行する時は、Atlas内に来歴が自動的に生成されています。
ジョブを正しく実行するには、[Spark configuration] (Spark設定)タブでさらにその他のパラメーターを設定する必要があります。詳細は、Spark Batchジョブを作成をご覧ください。
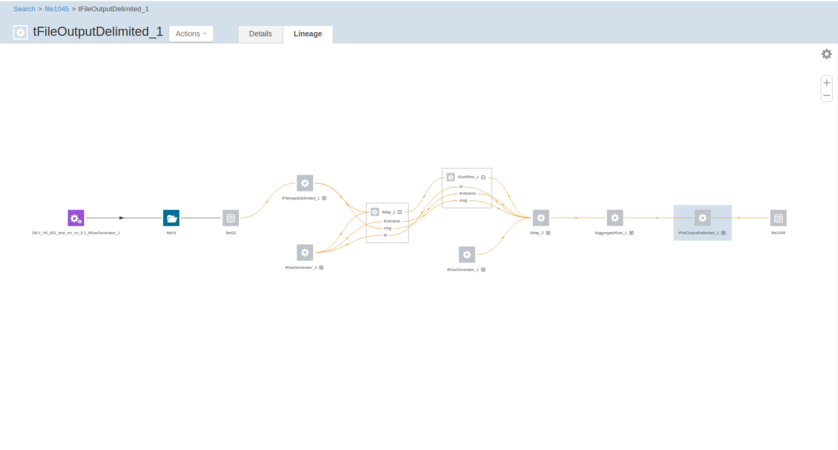
ジョブの実行が完了したら、このジョブによって書かれた来歴情報をAtlasで検索し、そこで来歴を読みます。
Atlas来歴を読み取り
-
-
ジョブ自体。
-
tRowGeneratorまたはtSortRowなど、データスキーマを使用するジョブ内のコンポーネント。tHDFSConfigurationなどの接続または設定コンポーネントはスキーマを使用しないため、これらは考慮されません。
-
-
Talend: ジョブによって生成されたすべてのエンティティに。
-
TalendComponent: すべてのコンポーネントエンティティに。
-
TalendJob: すべてのジョブエンティティに。
Atlasでこれらのタグの1つを直接クリックすれば、対応するエンティティが表示されます。