
メタデータを使ってHDFSからデータを読み取り
tHDFSInputコンポーネントを使えば、HDFSからデータを読み取れます。
始める前に
- このチュートリアルではHadoopクラスターを活用します。Hadoopクラスターが利用可能であることが必要です。
- また、HDFSメタデータが設定されていることも必要です(Hadoop クラスターメタデータ定義の作成とHadoop クラスターメタデータ定義のインポートをご覧ください)。
- HDFSにデータを書き込んでいること(メタデータを使ってHDFSにデータを書き込みをご覧ください)。
手順
-
[Edit schema] (スキーマを編集)の横にある[...]ボタンをクリックします。
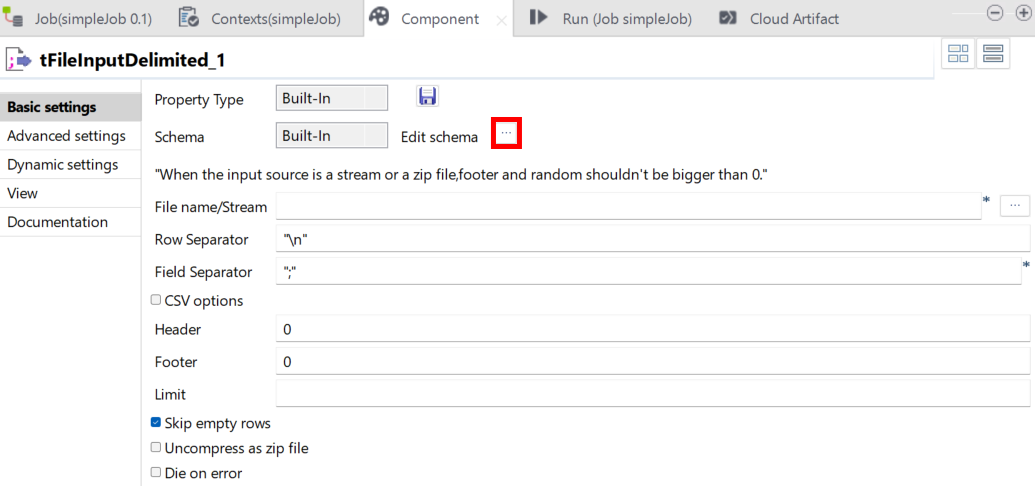
-
tSortRowコンポーネントを右クリックします。
-
tLogRowコンポーネントをクリックし、2つのコンポーネントをリンクします。
[Designer] (デザイナー)は次のようになります。
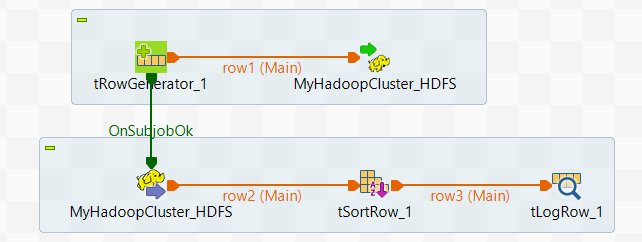
-
tLogRowコンポーネントをクリックし、2つのコンポーネントをリンクします。