
Apache Spark BatchのtRuleSurvivorshipプロパティ
これらのプロパティは、[Spark Batch]ジョブのフレームワークで実行されているtRuleSurvivorshipを設定するために使われます。
[Spark Batch]のtRuleSurvivorshipコンポーネントは、データクオリティファミリーに属しています。
このフレームワークのコンポーネントは、すべてのビッグデータ対応のTalendプラットフォーム製品およびTalend Data Fabricで利用できます。
基本設定
| プロパティ | 説明 |
|---|---|
|
[Schema] (スキーマ)と[Edit schema] (スキーマを編集) |
|
|
[Group identifier] (グループ識別コード) |
必要なグループIDをコンテンツが示しているカラムを、入力スキーマから選択します。 |
|
[Rule package name] (ルールパッケージ名) |
このコンポーネントで作成するルールパッケージの名前を入力します。 |
| [Generate rules and survivorship flow] (ルールおよびサバイバーシップフローの生成) |
このコンポーネントで、ルールパッケージのルールをすべて定義するか、またはその一部を変更したら、 情報メモ注:
このステップは、変更を確定し、ランタイムで有効にするために必要なものです。同じ名前のルールパッケージが[Repository] (リポジトリー)内に既に存在する場合は、変更を確定すると上書きされます。それ以外の場合は、実行中に[Repository] (リポジトリー)のルールパッケージが優先します。 情報メモ警告: ルールパッケージ内で、2つのルールに同じ名前を使用することはできません。
|
|
[Rule table] (ルールテーブル) |
このテーブルに入力して、完全なサバイバー検証フローを作成します。基本的に、各ルールは実行ステップとして定義されます。したがって、このテーブル内で上から下に順番に、これらのルールがシーケンスを形成し、したがって、フローが形成されます。このテーブルのカラムは、以下のとおりです。 Order: サバイバー検証フローを定義するために、作成するルールの実行順序をリストから選択します。順序のタイプは以下の場合があります。
[Rule Name] (ルール名): 作成する各ルールの名前を入力します。このカラムは[Sequential] (順次)ルールでのみ利用できます。[Sequential] (順次)ルールはサバイバー検証フローのステップを定義するからです。ルール名に特殊文字を使用しないでください。特殊文字を使用すると、ジョブが正しく実行されない場合があります。ルール名では大文字と小文字が区別されません。 [Reference column] (参照カラム): 特定のルールを適用する必要のあるカラムを選択します。このコンポーネントのスキーマで定義したカラムです。このカラムは[Multi-target] (マルチターゲット)ルールでは利用できません。このルールは[Target column] (ターゲットカラム)のみを定義するためです。 [Function] (ファンクション): 特定の[Reference column] (参照カラム)を対象に実行する検証オペレーションのタイプを選択します。利用できるタイプは次のとおりです。
[Value] (値): [Function] (ファンクション)カラムで選択した[Match regex] (正規表現にマッチング)または[Expression] (式)ファンクションに対応する、目的の式を入力します。 [Target column] (ターゲットカラム): ステップが実行されると、特定の[Reference column] (参照カラム)からレコードフィールド値を検証し、特定の[Target column] (ターゲットカラム)から対応する値をベストとして選択します。このコンポーネントのスキーマカラムから、この[Target column] (ターゲットカラム)を選択します。 [Ignore blanks] (空白を無視する): 空白の値が無視されるようにしたいカラムの名前に対応するチェックボックスをオンにします。 |
|
[Define conflict rule] (競合ルールの定義) |
競合を解決するルールを[Conflict rule table] (競合ルールテーブル)内に作成できるようにする場合は、このチェックボックスを選択します。 |
|
[Conflict rule table] (競合ルールテーブル) |
このテーブルに入力して、競合を解決するルールを作成します。このテーブルのカラムは、以下のとおりです。 [Rule name] (ルール名): 作成する各ルールの名前を入力します。ルール名に特殊文字を使用しないでください。特殊文字を使用すると、ジョブが正しく実行されない場合があります。 [Conflicting column] (競合するカラム): ステップが実行されると、特定の[Reference column] (参照カラム)からレコードフィールド値を検証し、特定の[Conflicting column] (競合するカラム)から対応する値をベストとして選択します。このコンポーネントのスキーマカラムから、この[Conflicting column] (競合するカラム)を選択します。 [Function] (ファンクション): 特定の[Conflicting column] (競合するカラム)を対象に実行する検証オペレーションのタイプを選択します。利用できるタイプは、[Rule table] (ルールテーブル)内のタイプと、以下のタイプです。
[Value] (値): [Function] (ファンクション)カラムで選択した[Match regex] (正規表現にマッチング)または[Expression] (式)ファンクションに対応する、目的の式を入力します。 [Reference column] (参照カラム): 特定の競合ルールを適用する必要のあるカラムを選択します。このコンポーネントのスキーマで定義したカラムです。 [Ignore blanks] (空白を無視する): 空白の値が無視されるようにしたいカラムの名前に対応するチェックボックスをオンにします。 [Disable] (無効化): 対応するルールを無効にするには、チェックボックスをオンにします。 |
詳細設定
| プロパティ | 説明 |
|---|---|
|
[Set the number of partitions by GID] (GIDごとのパーティション数の設定) |
各グループを分割して作成するパーティションの数を入力します。 |
グローバル変数
| 変数 | 説明 |
|---|---|
|
グローバル変数 |
ERROR_MESSAGE: エラーが発生した時にコンポーネントによって生成されるエラーメッセージ。これはAfter変数で、文字列を返します。この変数はコンポーネントにこのチェックボックスが存在し、[Die on error] (エラー発生時に強制終了)がオフになっている場合のみ機能します。 Flow変数はのコンポーネントの実行中に機能し、After変数はコンポーネントの実行後に機能します。 フィールドまたは式に変数を入力する場合は、Ctrl + スペースを押して変数リストにアクセスし、使用する変数を選択します。 変数の詳細は、コンテキストと変数を使用をご覧ください。 |
使用方法
| 使用方法のガイダンス | 説明 |
|---|---|
|
使用ルール |
このコンポーネントは中間ステップとして使用されます。 このコンポーネントは、所属するSpark Batchのコンポーネントのパレットと共に、Spark Batchジョブを作成している場合にだけ表示されます。 特に明記していない限り、このドキュメンテーションのシナリオでは、標準ジョブ、つまり従来の Talend Data Integrationジョブだけを扱います。 |
|
[Spark Connection] (Spark接続) |
[Run] (実行)ビューの[Spark configuration] (Spark設定)タブで、ジョブ全体でのSparkクラスターへの接続を定義します。また、ジョブでは、依存jarファイルを実行することを想定しているため、Sparkがこれらのjarファイルにアクセスできるように、これらのファイルの転送先にするファイルシステム内のディレクトリーを指定する必要があります。
この接続は、ジョブごとに有効になります。 Databricksと共にSpark 3.Xでジョブを実行する場合は、Databricksクラスターに移動し、Databricksランタイムバージョン10.1 (Apache Spark 3.2.0、Scala 2.12を含む)以降を選択します。それ以前のバージョンはサポートされていません。
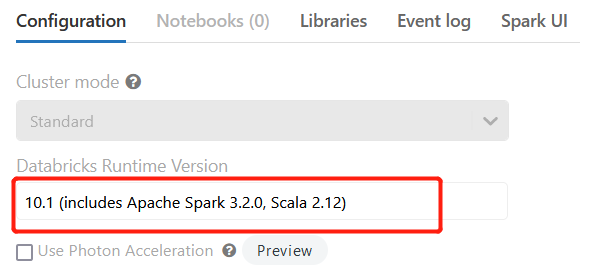 Scalaのバージョンが2.12.13以降であることをチェックします。 |