
デシジョンツリーとランダムフォレストアルゴリズムを使ってデータを分析
デシジョンツリーは、特徴空間の再帰的バイナリパーティショニングを行う欲張りなアルゴリズムです。
ツリーノードでの情報利得を最大化できるよう、パーティショニングはそれぞれ、考えられるパーティショニングの集合から最適なパーティショニングを選択することで貪欲に選択されます。情報利得は、特定のノードでラベルの同質性を測るノードの不純物と関連しています。
現在の実装では、分類で次の2つの不純物測定方法を利用できます。
- ジニ不純物
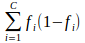
- fiがノードでのラベルiの頻度であるエントロピ
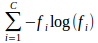 。
。
分割するには、継続的な各特徴は分離される必要があります。各特徴のビン数は、[Max Bins] (最大ビン)パラメーターによって管理されています。このパラメーターの値を増やせば、アルゴリズムは分割候補を多く考慮およびきめ細かい分割を決定できるようになります。ただし、計算が複雑化します。以下の条件が1つ満たされるとすぐに、デシジョンツリーの構築が停止します:
- ノード深度はツリーの最大深度に等しいです。より深いデシジョンツリーはよりわかりやすいですが、消費量が多く、過剰適合の原因となることがあります。
- [Min Info Gain] (最小情報利得)より大きい情報利得を与える分割候補がありません。
- それぞれ[Min Instances Per Node] (ノードあたりの最小インスタンス)行が少なくとも1つ含まれている子ノードを生成する分割候補がありません。
ランダムフォレストアルゴリズムは、データセットのサブセットおよび特徴のサブセットでデシジョンツリーアルゴリズムを何度も(numTreesというパラメーターによって制御される)実行します。
2つのサブセットは、2つのパラメーターによって処理されます:
- サブサンプリングレート: このパラメーターは、フォレスト内の各デシジョンツリーのトレーニングに使用される入力データセットの割合を指定します。交換によるサンプリングを行うと、データセットは作成されます。これは、ある行が何度も出現できることを意味します。
- サブセット戦略: このパラメーターは各ツリーの考慮される特徴の数を指定します。以下の値を1つ指定できます:
- auto: 作戦はフォレスト内のツリーの数に自動的に基づきます。
- all: 特徴の合計数が分割対象となります。
- sqrt: 特徴の合計数の平方根が特徴の数として考慮されます。
- log2: Mが特徴の合計数であるlog2(M)の結果が特徴の数として考慮されます。
これによって、さまざまなツリーが生成されます。ツリーのセットで多数決を採れば、新しい値を予測できます。