
Fonctionnement d'un Job Talend Spark
Un Job Talend Spark peut être exécuté dans l'un des modes suivants :
-
Local : le Studio Talend construit l'environnement Spark en lui-même au moment de l'exécution locale du Job dans le Studio Talend. Avec ce mode, chaque processeur de la machine locale est utilisé comme Worker Spark pour effectuer les calculs. Ce mode requiert la configuration d'un minimum de paramètres dans la vue de configuration.
Notez que cette machine locale est la machine sur laquelle s'exécute le Job.
-
Standalone : le Studio Talend se connecte à un cluster compatible Spark pour exécuter le Job depuis ce cluster.
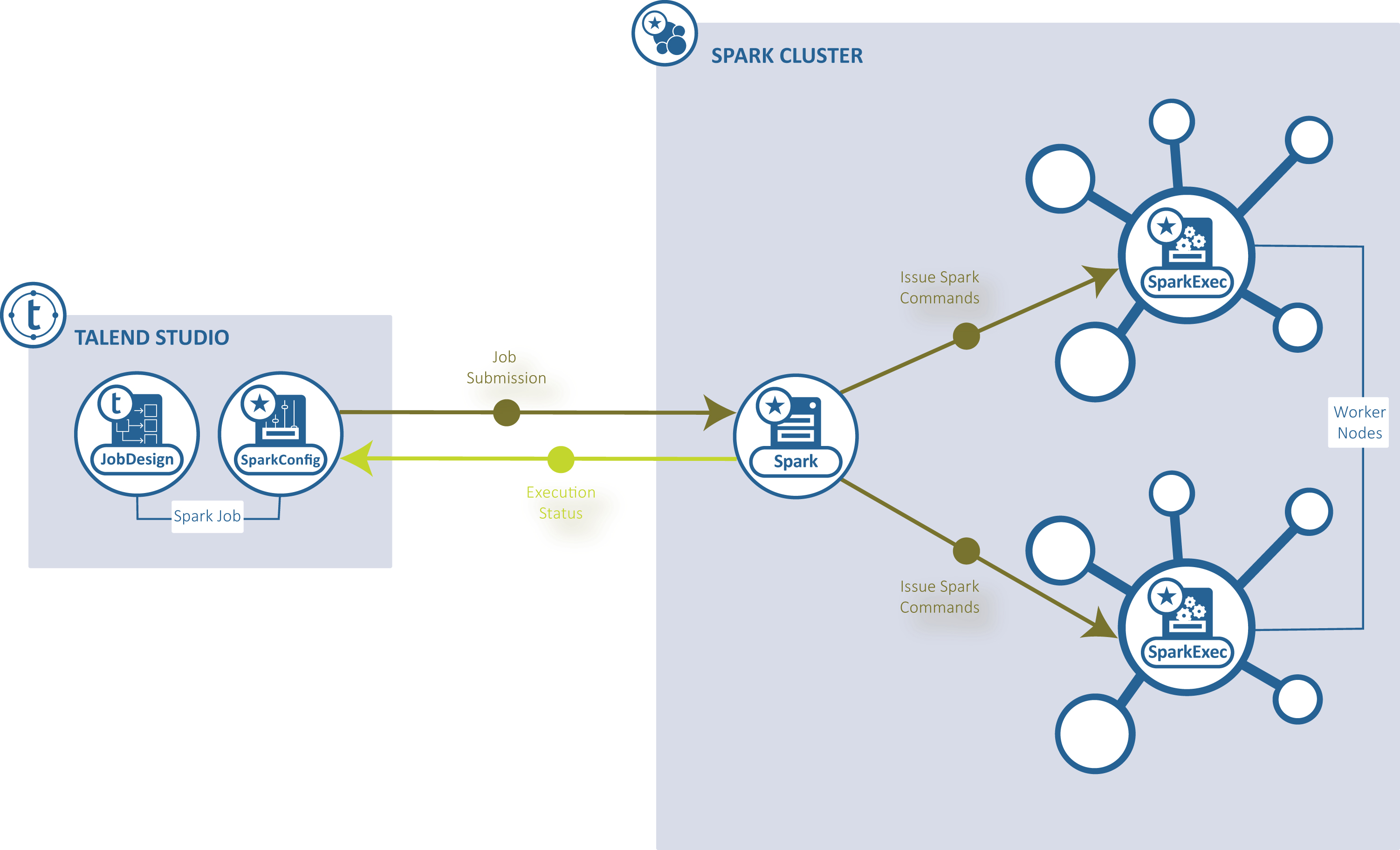
-
YARN client : le Studio Talend exécute le pilote Spark pour orchestrer comment le Job doit être exécuté puis envoie l'orchestration au service YARN d'un cluster Hadoop donné, afin que le Resource Manager de ce service YARN demande des ressources pour l'exécution.
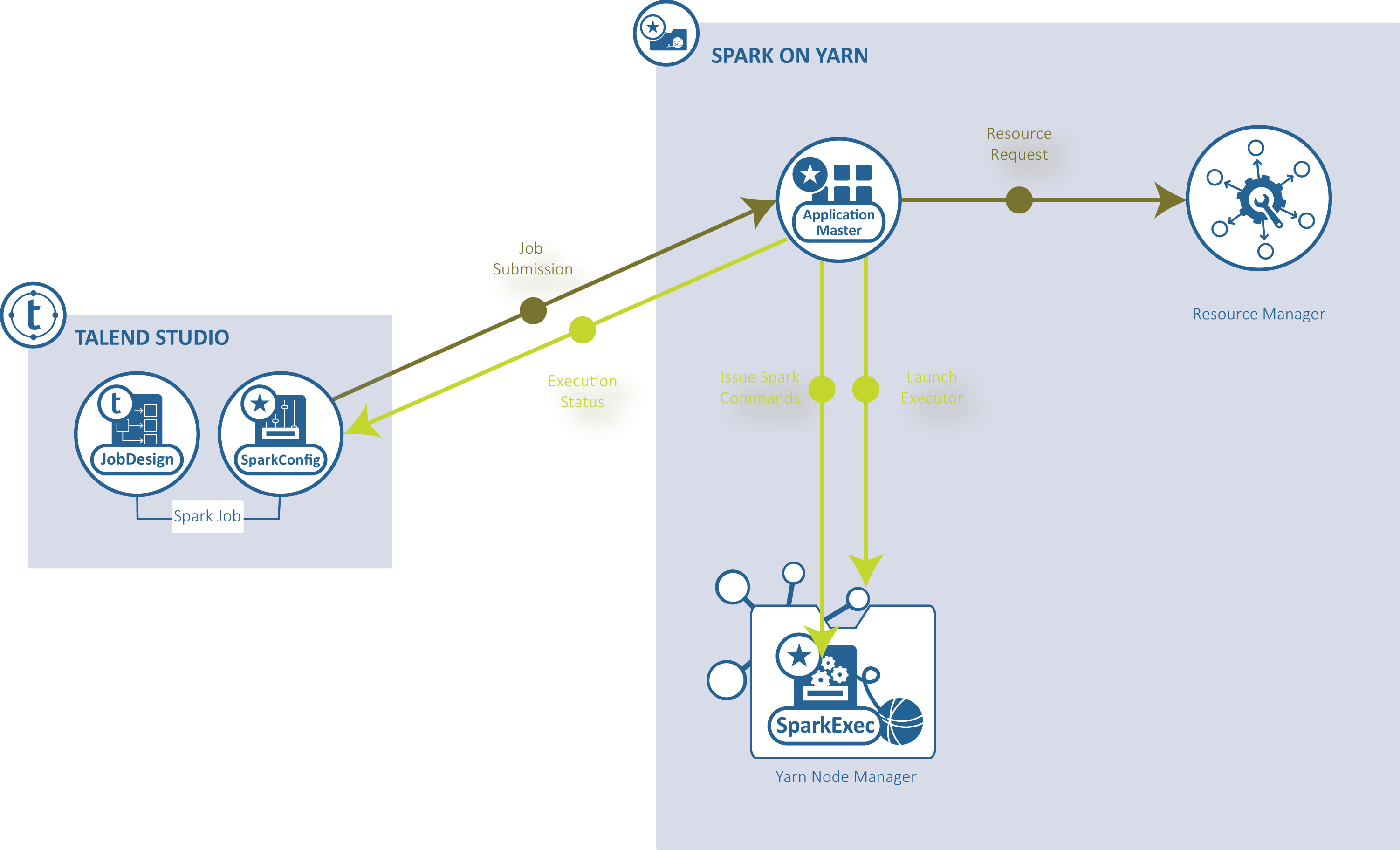
-
YARN cluster : le Studio Talend soumet des Jobs à YARN et ApplicationMaster et en collecte les informations d'exécution. Le pilote Spark s'exécute sur le cluster et peut s'exécuter indépendamment de votre Studio Talend.
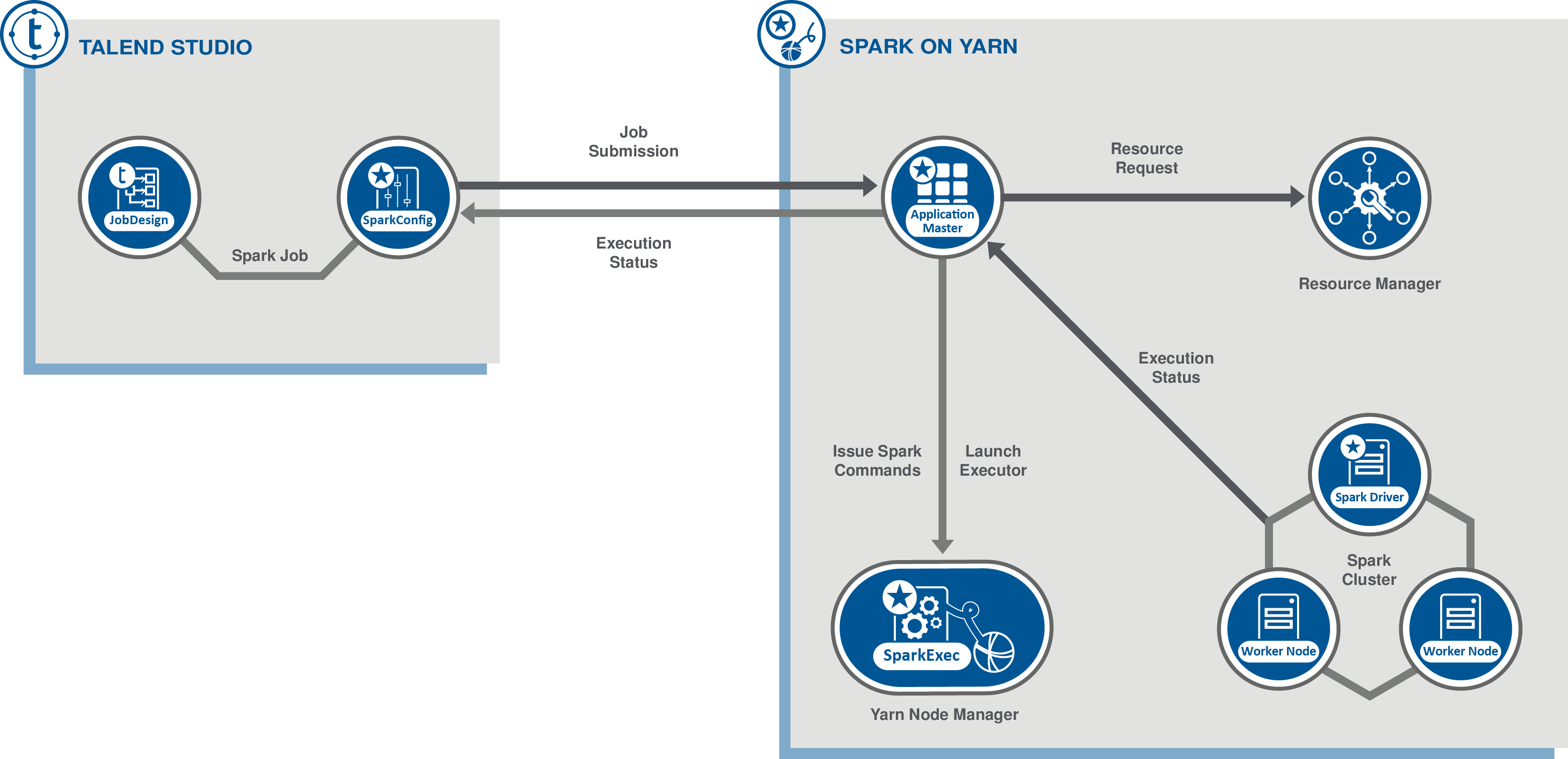
Dans le Studio Talend, vous pouvez créer un Job Spark à l'aide des composants Spark dédiés et configurer la connexion au cluster à utiliser. Lors de l'exécution, cette configuration permet au Studio Talend de communiquer directement avec le cluster pour effectuer les opérations suivantes :
-
soumettre le Job Spark au serveur Master en mode Standalone ou au serveur ApplicationMaster, en mode Yarn client ou Yarn cluster du cluster utilisé,
-
copier les ressources du Job dans le système de fichiers distribué du même cluster. Le cluster termine le reste de l'exécution : l'initialisation du Job, la génération de l'ID du Job et l'envoi des informations de progression de l'exécution ainsi que les résultats dans le Studio Talend.
Notez qu'un Job Spark Talend n'est pas identique à un Job Spark comme expliqué dans la documentation Spark d'Apache. Un Job Spark Talend génère un ou plusieurs job(s) Spark (en termes Apache Spark), selon la manière dont vous créez le Job Talend dans l'espace de modélisation graphique du Studio Talend. Pour plus d'informations concernant les jobs Spark, consultez le glossaire (uniquement en anglais) de la documentation officielle Apache Spark (en anglais).
Chaque composant dans un Job Talend Spark sait comment générer les tâches spécifiques lui permettant d'accomplir sa mission (les classes dans le code généré) et comment rassembler toutes les tâches pour former le Job. Chaque connexion entre les composants génère une structure (un enregistrement Avro) pouvant contenir des données et est compatible avec la sérialisation Spark. Les composants sont optimisés pour leurs tâches spécifiques. Lors de l'exécution, ces classes générées sont envoyées dans les nœuds pour exécuter les données. Les structures contenant les données sont également envoyées entre les nœuds durant les phases de distribution et le Job Talend lui-même coordonne les jobs Spark générés.
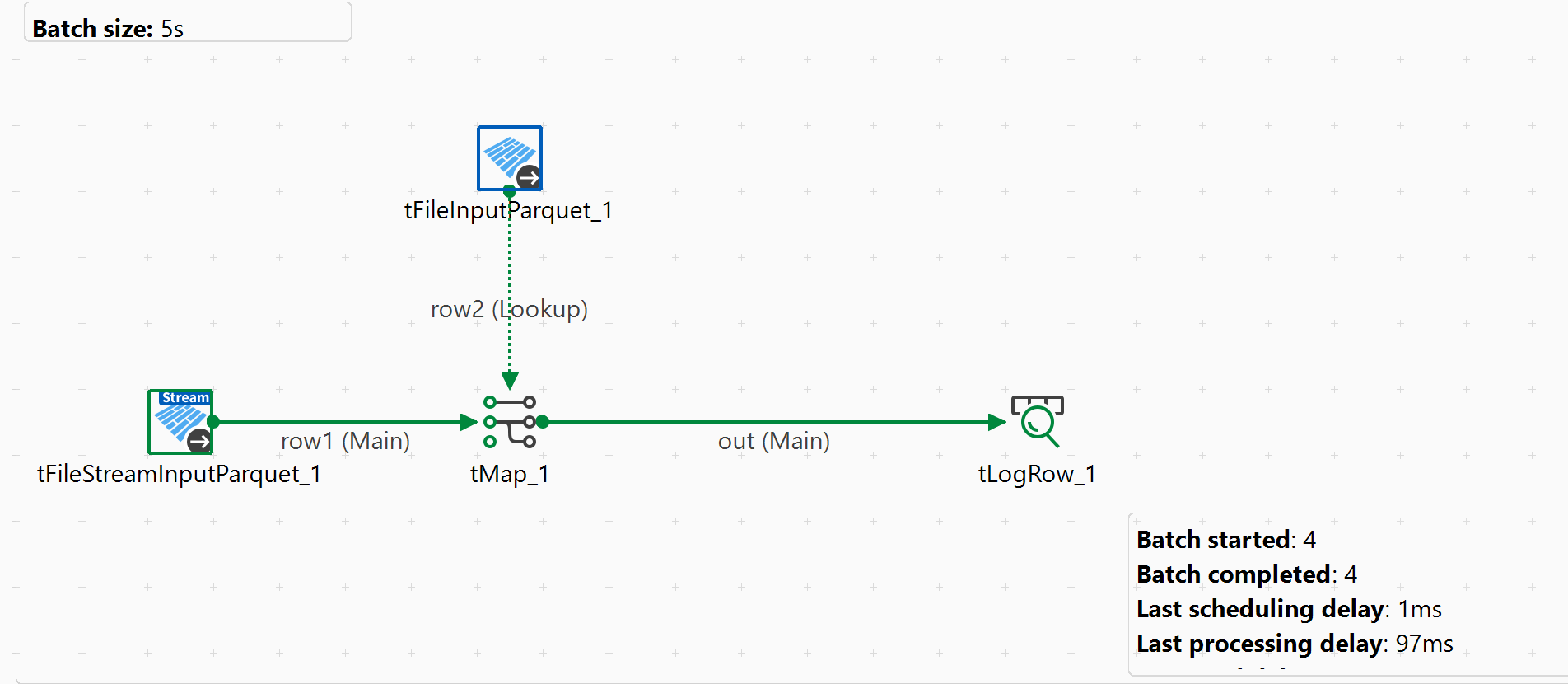
Lorsque vous exécutez le Job, des informations statistiques sont affichées dans l'espace de modélisation graphique du Job pour indiquer la progression des calculs Spark coordonnées par le Job.
L'image suivante présente un exemple de Jobs Talend Spark Batch dans lequel des informations statistiques sont affichées en vert :
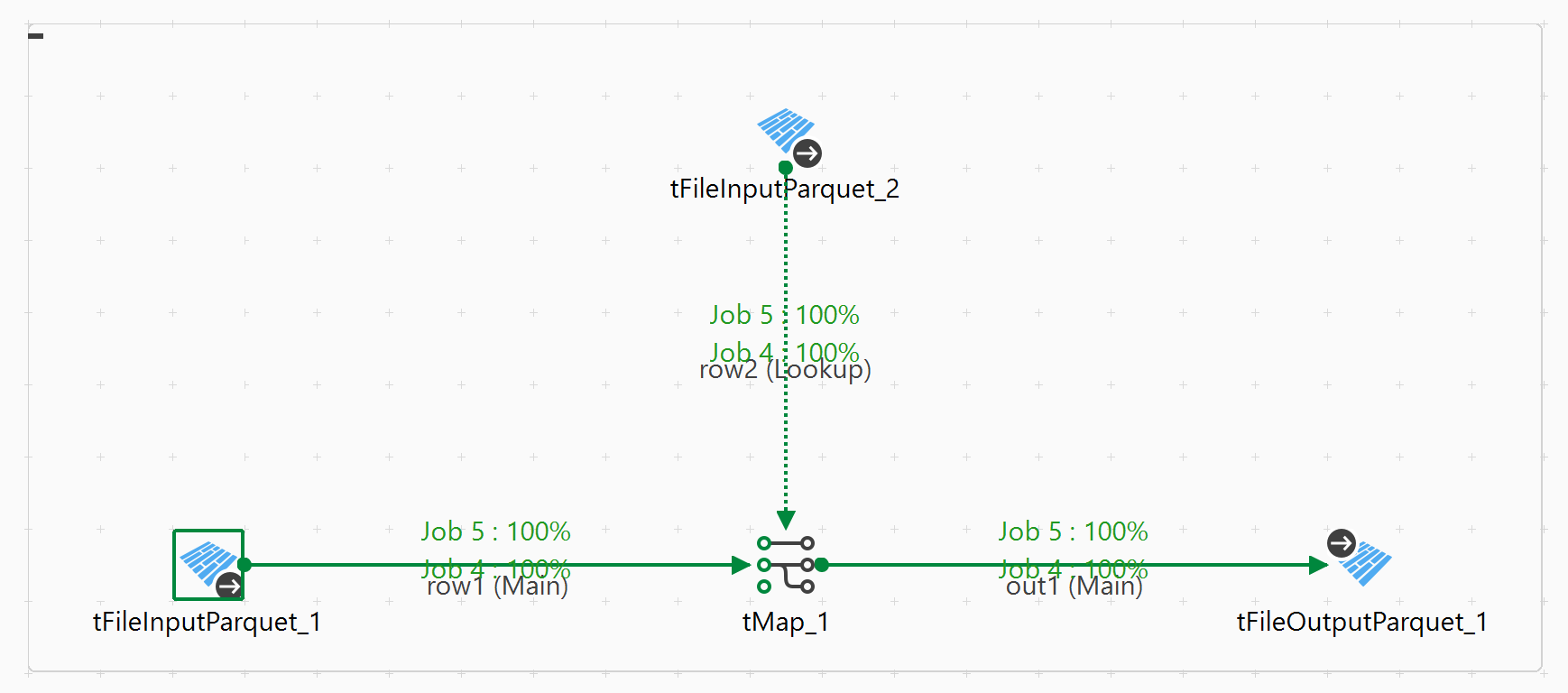
Dans cet exemple, deux Jobs Spark, job 4 et job 5, sont créés et vous pouvez constater qu'ils sont terminés à 100 %.
Les informations d'exécution d'un Job Talend Spark sont enregistrées par le service HistoryServer du cluster à utiliser. Vous pouvez consulter la console Web du service pour voir les informations d'exécution. Le nom du Job dans la console est automatiquement construit pour suivre la structure suivante : ProjectName_JobName_JobVersion, par exemple, LOCALPROJECT_wordcount_0.1.