
Big Data
|
Fonctionnalité |
Description |
Disponible dans |
|---|---|---|
| Support d'Amazon EMR 6.6.0 et 6.7.0 avec Spark Universal 3.2.x |
Vous pouvez à présent exécuter vos Jobs Spark sur un cluster Amazon EMR, à l'aide de Spark Universal avec Spark 3.2.x en mode Yarn cluster. Vous pouvez la configurer dans la vue Spark Configuration (Configuration de Spark) de vos Jobs Spark ou dans l'assistant de métadonnées Hadoop Cluster Connection (Connexion au cluster Hadoop). Lorsque vous sélectionnez ce mode, le Studio Talend est compatible avec Amazon EMR 6.6.0 et 6.7.0. |
Tous les produits Talend avec Big Data nécessitant souscription |
|
Support du Runtime Databricks 11.x avec Spark Universal 3.3.x |
Vous pouvez à présent exécuter vos Jobs Spark Batch et Streaming sur des clusters de jobs et des clusters universels Databricks sur Google Cloud Platform (GCP), AWS et Azure, à l'aide de Spark Universal avec Spark 3.3.x. Vous pouvez la configurer dans la vue Spark Configuration (Configuration de Spark) de vos Jobs Spark ou dans l'assistant de métadonnées Hadoop Cluster Connection (Connexion au cluster Hadoop). Lorsque vous sélectionnez ce mode, le Studio Talend est compatible avec la version 11.x de Databricks. Avec la disponibilité générale de cette fonctionnalité, les problèmes connus suivants ont été corrigés :

|
Tous les produits Talend avec Big Data nécessitant souscription |
|
Support de BigDecimal dans le tRedshiftOutput |
Vous pouvez à présent utiliser des valeurs BigDecimal dans le schéma du composant tRedshiftOutput, dans vos Jobs Spark Batch.
|
Tous les produits Talend avec Big Data nécessitant souscription |
|
Support du tGSConfiguration avec Spark Universal |
Vous pouvez à présent utiliser le composant tGSConfiguration pour fournir l'accès à Google Storage avec d'autres composants d'entrée et de sortie. Cette fonctionnalité s'applique aux Jobs Spark Batch et Spark Streaming. |
Tous les produits Talend avec Big Data nécessitant souscription |
|
Support du registre de schémas |
Vous pouvez à présent utiliser le registre de schémas dans les Jobs Spark Streaming avec les composants suivants :
Le registre de schémas permet au Studio Talend d'enregistrer des informations concernant des enregistrements Avro. 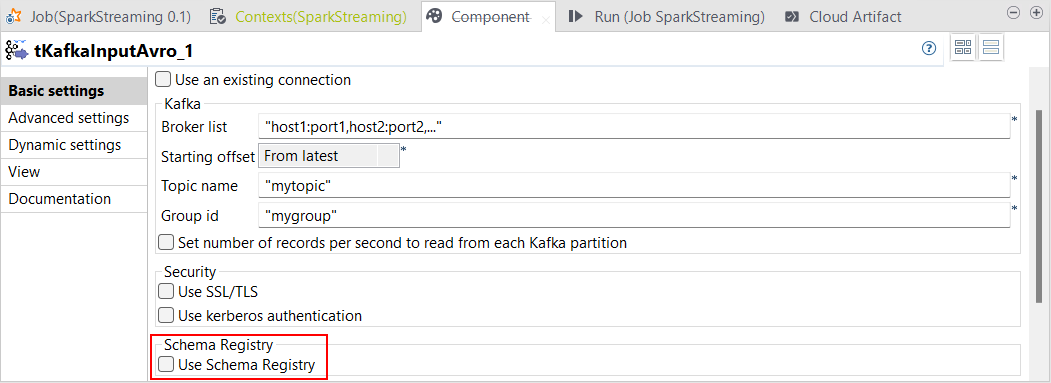
|
Tous les produits Talend avec Big Data nécessitant souscription |
|
Support de S3 Select |
Vous pouvez à présent utiliser S3 Select avec le tFileInputDelimited et le tFileInputJSON lorsque vous utilisez le composant tS3Configuration comme composant de stockage dans vos Jobs Spark s'exécutant avec Spark Universal en mode YARN cluster (avec un cluster Amazon EMR) ou en mode Databricks. S3 Select vous permet de réduire le volume de données récupérées de S3 à l'aide de requêtes Spark SQL. Lorsque vous exécutez vos Jobs Spark sur Databricks, le bucket S3 doit se trouver dans la même région que le cluster, sinon vous obtenez une exception S3 côté cluster. |
Tous les produits Talend avec Big Data nécessitant souscription |