
Finaliser et exécuter le Job
Procédure
- Double-cliquez sur chaque composant tLogRow pour afficher sa vue Basic settings et définir ses propriétés.
- Sauvegardez votre Job et appuyez sur F6 pour l'exécuter.
Résultats
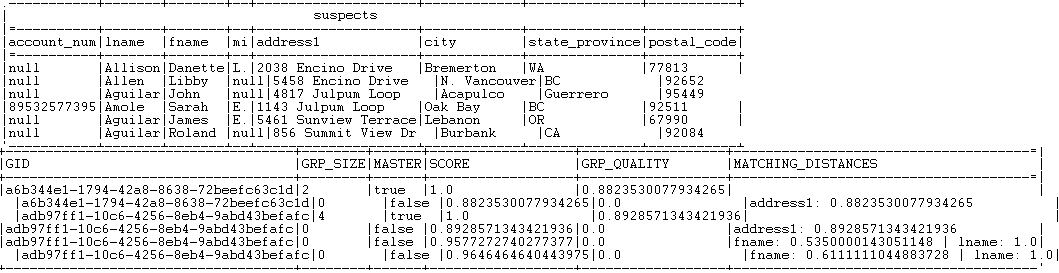
Vous pouvez constater que les enregistrements sont regroupés dans trois groupes différents. Chaque enregistrement est listé dans un des trois groupes, selon la valeur du score de groupe, représentant la distance minimale calculée dans le groupe.
L'identifiant de chaque groupe, de type String, s'affiche dans la colonnes GID à côté de l'enregistrement correspondant. L'identifiant est de type Long pour les Jobs migrés depuis d'anciennes versions. Si vous souhaitez avoir un identifiant de groupe de type String, remplacez le composant tMatchGroup dans le Job importé par un tMatchGroup de la Palette.
Le nombre d'enregistrements dans chacun des trois blocs de sortie est listé dans la colonne GRP_SIZE et calculé uniquement sur l'enregistrement maître. La colonne MASTER indique par true ou false si l'enregistrement correspondant est un enregistrement maître ou non. La colonne SCORE liste la distance calculée entre l'enregistrement d'entrée et l'enregistrement maître, selon les algorithmes de correspondance Jaro-Winkler et Jaro.
Le Job évalue les enregistrements par rapport à la première règle et les enregistrements qui correspondent à celle-ci ne sont pas évalués par rapport à la seconde règle.
Tous les enregistrements dont le score de groupe est compris dans l'intervalle de correspondance, 0.95 ou 0.85 selon la règle appliquée et le seuil de confiance défini dans les paramètres avancés du tMatchGroup sont listés dans le flux de sortie Suspects.
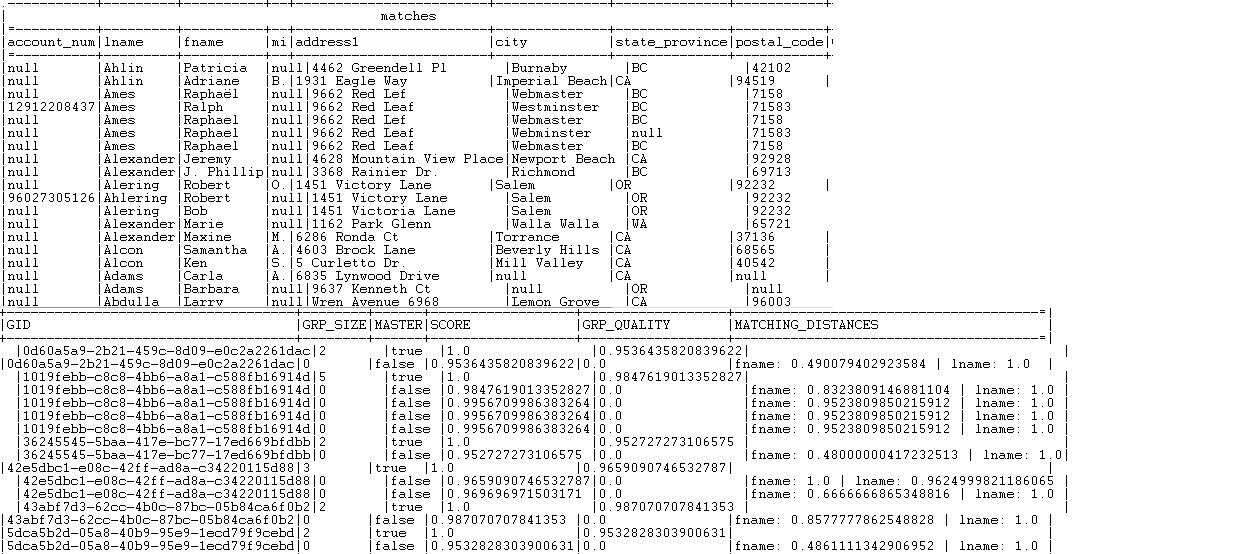
Tous les enregistrements dont le score de groupe est supérieur ou égal à l'une des probabilités de correspondance sont listés dans le flux de sortie Matches.
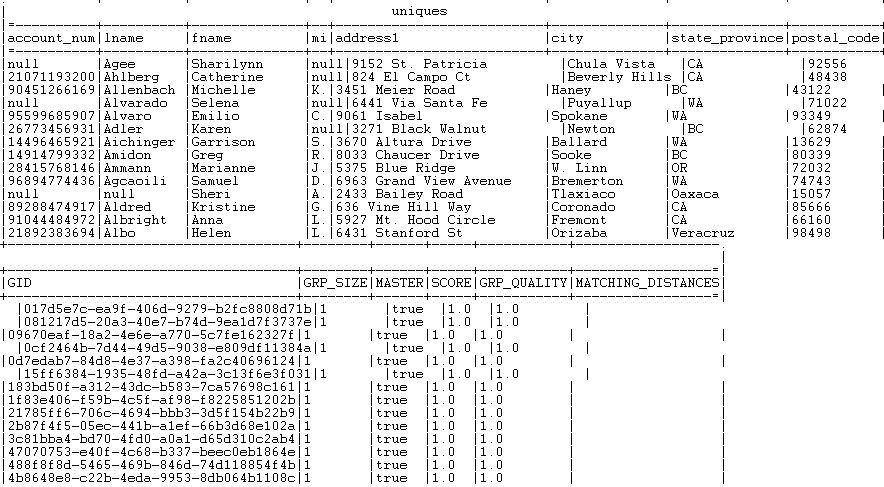
Tous les enregistrements dont la taille du groupe est égale à 1 sont listés dans le flux de sortie Uniques.
Pour un autre scénario regroupant les enregistrements de sortie en un seul flux de sortie basé sur une clé fonctionnelle générée, consultez Comparer les colonnes et regrouper dans le flux de sortie les enregistrements en doublon ayant la même clé fonctionnelle dans la section Identification.