
Configurer le composant tMatchGroup
Procédure
-
Cliquez sur le bouton près du champ Edit schema pour voir les schémas d'entrée et de sortie et effectuer des modifications dans le schéma de sortie, si nécessaire.
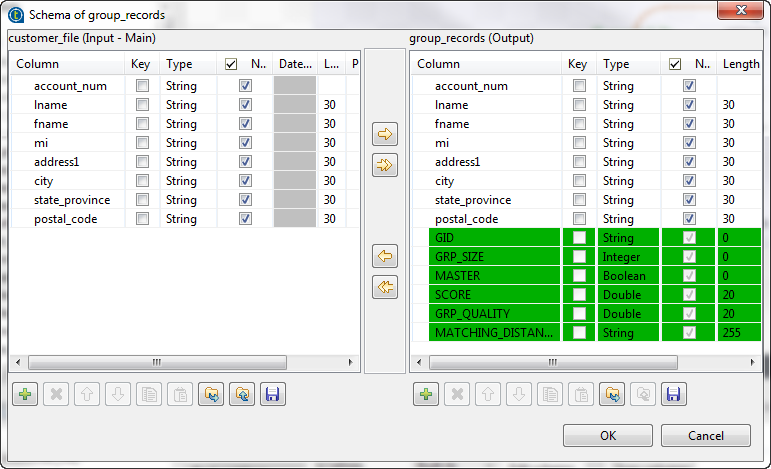 Dans le schéma de sortie de ce composant, vous pouvez voir des colonnes standard en lecture seule. Pour plus d'informations, consultez Propriétés du tMatchGroup Standard.
Dans le schéma de sortie de ce composant, vous pouvez voir des colonnes standard en lecture seule. Pour plus d'informations, consultez Propriétés du tMatchGroup Standard. -
Cliquez sur le bouton […] près de Configure match rules pour ouvrir l'assistant de configuration et configurez le composant et les règles de rapprochement.
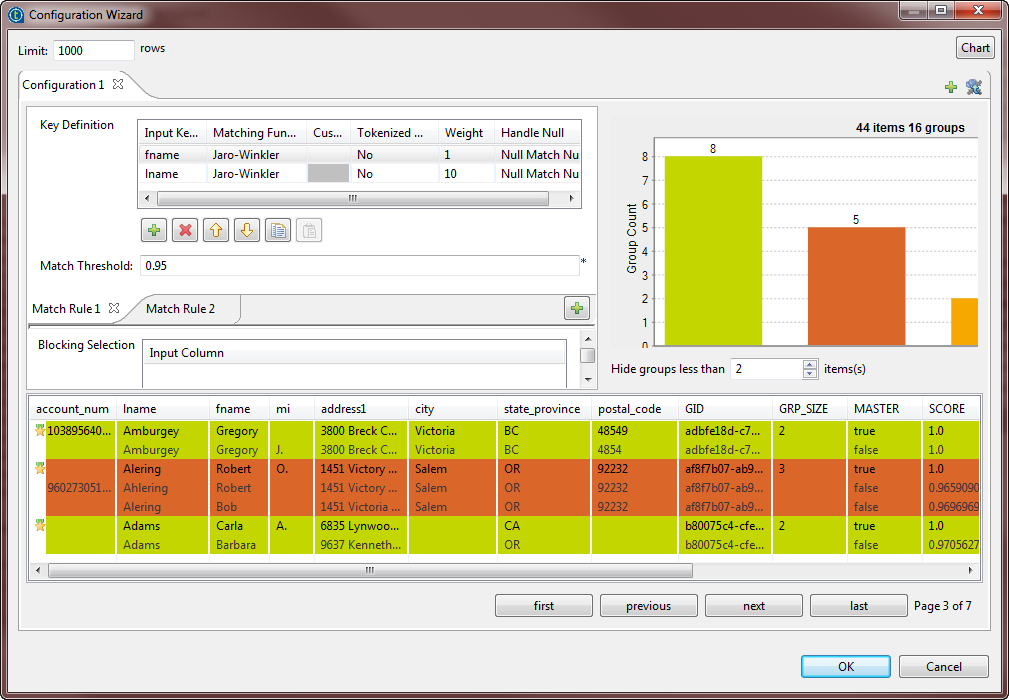 Vous pouvez utiliser l'assistant de configuration pour importer des règles de rapprochement créées puis testées dans le Studio et stockées dans le référentiel et les utiliser dans vos Jobs de rapprochement. Pour plus d'informations, consultez Import de règles de mise en correspondance depuis le référentiel du Studio.Il est important d'importer ou de définir dans les propriétés simples du composant le même type de règle, sinon, le Job s'exécute avec les valeurs par défaut des paramètres n'étant pas compatibles avec le deux algorithmes.
Vous pouvez utiliser l'assistant de configuration pour importer des règles de rapprochement créées puis testées dans le Studio et stockées dans le référentiel et les utiliser dans vos Jobs de rapprochement. Pour plus d'informations, consultez Import de règles de mise en correspondance depuis le référentiel du Studio.Il est important d'importer ou de définir dans les propriétés simples du composant le même type de règle, sinon, le Job s'exécute avec les valeurs par défaut des paramètres n'étant pas compatibles avec le deux algorithmes. -
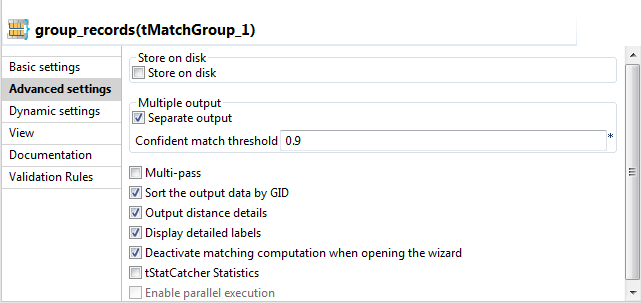
Cliquez sur l'onglet Advanced settings et configurez les paramètres avancés du tMatchGroup comme suit :
-
Cochez la case Separate output.
Le composant crée trois flux de sortie séparés : Unique rows, Confident groups et Uncertain groups.
Si la case n'est pas cochée, le composant tMatchGroup n'a qu'un flux de sortie regroupant toutes les données de sortie. Pour un scénario d'exemple, consultez Comparer les colonnes et regrouper dans le flux de sortie les enregistrements en doublon ayant la même clé fonctionnelle dans la section Identification.
-
Cochez la case Sort the output data by GID afin de classer les données de sortie selon l'identifiant de leur groupe.
-
Cochez les cases Output distance details et Display detailed labels.
Le composant écrit en sortie la colonne MATCHING_DISTANCES. Cette colonne donne la distance entre les colonnes d'entrée et la colonne maître. Elle donne également le nom des colonnes mises en correspondance avec les enregistrements.
-
Cochez la case Deactivate matching computation when opening the wizard si vous ne souhaitez pas exécuter les règles de rapprochement lors de la prochaine ouverture de l'assistant.
-
-
Dans l'assistant, cliquez sur le bouton Chart afin d'exécuter le Job dans la configuration définie. Les résultats de la correspondance s'affichent directement dans l'assistant.
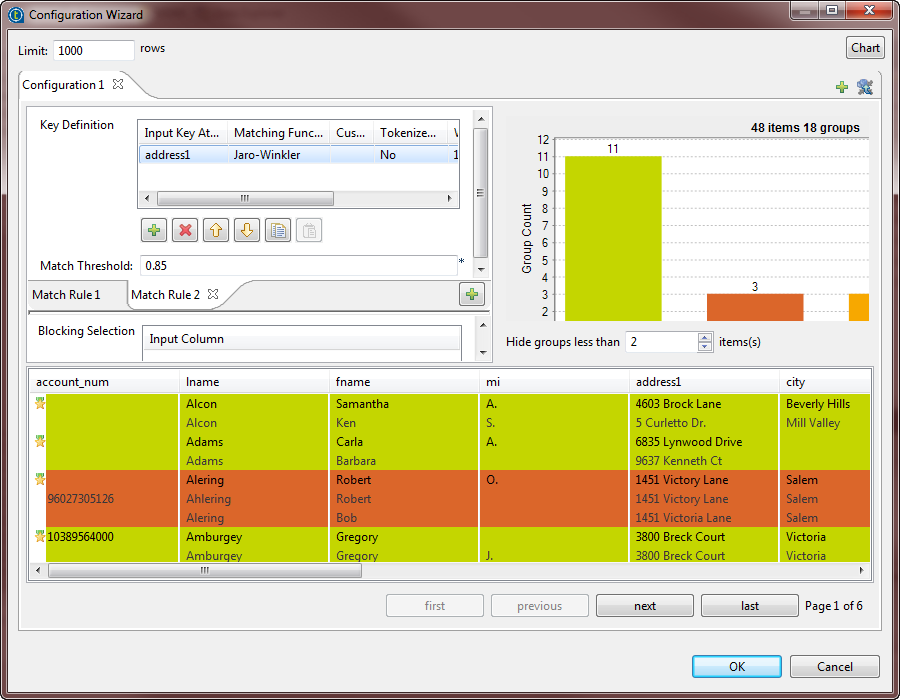 Le diagramme de rapprochement donne une vue globale des doublons dans les données analysées. La table des correspondances donne les détails des éléments de chaque groupe et les colore selon leur couleur dans le graphique des correspondances.Le Job effectue une opération de mise en correspondance de type OR. Il évalue les enregistrements de données par rapport à la première règle et les enregistrements qui correspondent à celle-ci ne sont pas évalués par rapport à la seconde règle. La colonne MATCHING_DISTANCES vous permet de voir la règle qui a été utilisée sur chaque enregistrement. Certains enregistrements sont rapprochés selon la seconde règle utilisant address1 comme attribut de clé et les autres enregistrements du groupe sont rapprochés selon la première règle utilisant les attributs de clés lname and fname.Vous pouvez configurer le paramètre Hide groups less than afin de définir les groupes à afficher dans le graphique et la table des correspondances.
Le diagramme de rapprochement donne une vue globale des doublons dans les données analysées. La table des correspondances donne les détails des éléments de chaque groupe et les colore selon leur couleur dans le graphique des correspondances.Le Job effectue une opération de mise en correspondance de type OR. Il évalue les enregistrements de données par rapport à la première règle et les enregistrements qui correspondent à celle-ci ne sont pas évalués par rapport à la seconde règle. La colonne MATCHING_DISTANCES vous permet de voir la règle qui a été utilisée sur chaque enregistrement. Certains enregistrements sont rapprochés selon la seconde règle utilisant address1 comme attribut de clé et les autres enregistrements du groupe sont rapprochés selon la première règle utilisant les attributs de clés lname and fname.Vous pouvez configurer le paramètre Hide groups less than afin de définir les groupes à afficher dans le graphique et la table des correspondances.