
Mapping Flat (Delimited or Positional) Objects
The flat representation allows delimited or positional flat documents to be processed with the structure. The delimited/positional support handles any kind of character or binary data. For this representation to work correctly, you must set up the flat element properties. The most common delimited representation is CSV (comma-separated values). You can import a CSV sample document, which will automatically set up the elements for CSV support. COBOL records are also supported using the flat representation, as a more flexible alternative to the specific COBOL representation.
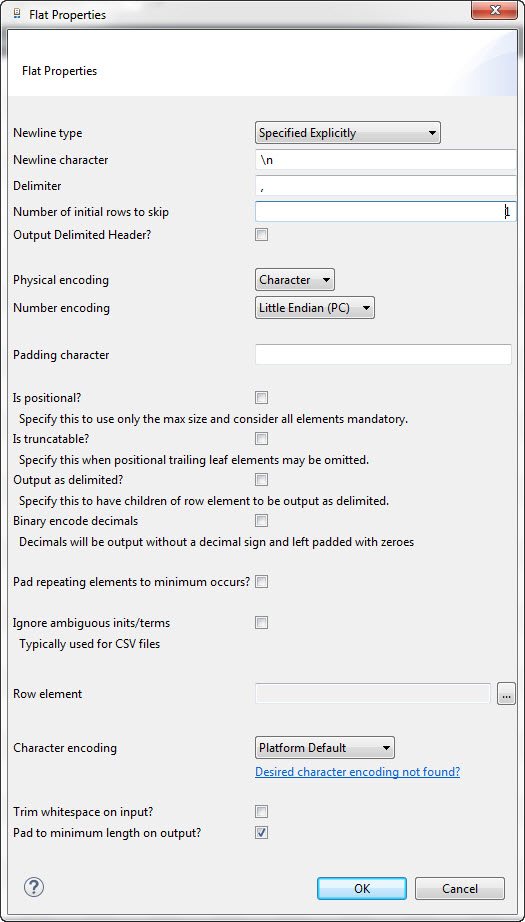
-
Initiator - For delimited use, this specifies characters that must appear either before or after an element. Depending on the setting of Include Element Initiator/Terminator, these characters may be considered part of the element. These values can be specified for elements at any level.
-
Include Initiator - For delimited use, this specifies whether the initiator/terminator characters are considered part of the element. If this is true, the characters will be put in the element's value on input, and the delimited initiator/terminator will not be written on output as they are assumed to be part of the element's value. This option is meaningful only for elements with a group type of none (that is, non container elements).
-
Release - Allows a character to be specified that's not considered part of the initiator/terminator characters.
-
Occurs - Defines the minimum and maximum number of times the element is allowed to occur.
-
Size - The minimum and maximum size of the element. A zero-sized element is sometimes handy to allow you to specify only an initiator or terminator.
-
Group Type - Allows elements to be organized as a sequence or choice of elements. A sequence requires each of the present child elements to occur in order, whereas a choice allows only one of the elements to occur. The initiator and terminator are respected to help determine which elements are present within choices and sequences.
-
Column - Used to indicate that the data starts at a certain column. The column is the number of characters after the last newline character.
-
Start Offset - Used to indicate the gap between the end of the previous element and the beginning of this element. Useful for positional data.
-
Quote Handling - Provides automatic handling of quotes around the element. You can specify that quotes are always required, or that they are optional. This is useful for CSV data.
-
Expression Trees - Use these to specify the conditions for when the element is to be read. For example, a certain element might not be present depending on the value of a preceding element, so you can specify this with an IfThen function in the Consume expression associated with the element.
-
Newline Character - In the structure editor, the newline character is specified as a \n, which is an abstract newline. In the Flat Representation Properties, you can specify the actual character sequence that the newline represents, allowing you to use the same structure specification for different actual newline sequences.
-
Physical Encoding - Binary data is fully supported. When using binary encoding, numeric values are formatted using their binary formats, for example a data type Integer (32) is formatted as 4 bytes. The data format allows you to override this for each element. For example, if a file is generally encoded as character data, but there are a few binary elements in it, you can use the data format to specify the elements that are binary.
-
Delimiter - Enter the character used to specify the boundary between separate, independent regions in the input data. If this is left blank, the delimiter is assumed to be a comma (,).
-
Number of initial rows to skip - In the case of CSV files, this property lets you specify the number of rows from the beginning of the file to skip.
-
Output Delimited Header? - In the case of CSV files, select this checkbox to add a delimited header to the output file generated.
-
Physical encoding - Choose between Character or Binary
-
Number encoding - Either big endian or little endian may be specified for all binary numeric values.
-
Padding character - Enter the character to be used when padding.
-
Is positional? - Treats the size of all elements as their maximum size (ignores the minimum size) and treats them all as mandatory (minimum occurrence of 1). This option is used to conveniently specify a positional usage.
-
Is truncatable? - Select this checkbox if it is acceptable for positional trailing leaf elements to be omitted.
-
Output as delimited? - Specify this to have children of row element to be output as delimited.
-
Binary encode decimals - By default, decimals have a decimal sign and are left padded with spaces when the positional option is set. Select this checkbox if you want decimals to be output without a decimal sign and left padded with zeroes.
-
Pad repeating elements to minimum occurs - Automatically add empty (padded with the appropriate padding character) elements to any elements that occur where the actual number of iterations is less than the minimum required number. This is set true by default for structures created by the COBOL importer.
-
Ignore ambiguous initiator/terminators - This makes the assumption that optional elements are handled sequentially in the order they appear. That is, if there is ambiguity about the next possible optional element to process, it is assumed to be the next optional element. Other optional elements are not considered. This is useful for CSV data when you want the trailing fields and their delimiters to be optional, and you want to end the record (line) early without specifying all of the delimiters (commas). This is the default when generating a structure from a CSV instance.
-
Row element: This lets you specify which element Talend Data Mapper should use to identify where a new row begins.
-
Character Encoding - The overall character encoding for the transformation is specified in the Flat Representation Properties.
-
Trim whitespace on input? - When you select this checkbox, any leading or trailing whitespace is removed automatically from the input data for all elements. The non-leading or trailing whitespace is not affected.
-
Generate Default Header? - When you select this checkbox, the option generates default column names (Col_1, Col_2, and so on) for a CSV file. You must only use this option on a file that does not have a header, as the importer does not check if the file has a header already.