
Big Data
|
Funktion |
Beschreibung |
Verfügbar in |
|---|---|---|
| Neue Komponenten für die Unterstützung des Iceberg-Tabellenformats in Standard-Jobs | Für Ihre Standard-Jobs in Talend Studio sind jetzt Iceberg-Komponenten verfügbar. Die folgenden Komponenten ermöglichen Ihnen die Arbeit mit Iceberg-kompatiblen Datenbanken über JDBC:
|
Alle abonnementbasierte Produkte von Talend mit Big Data |
| Unterstützung für den Standalone-Modus mit Spark Universal 3.4.x | Sie können Ihre Spark Batch- und Spark Streaming-Jobs jetzt unter Rückgriff auf Spark Universal mit Spark 3.4.x im Standalone-Modus ausführen. Die Konfiguration erfolgt entweder in der Ansicht Spark Configuration (Spark-Konfiguration) Ihrer Spark-Jobs oder im Metadaten-Assistenten Hadoop Cluster Connection (Hadoop-Clusterverbindung). Bei der Auswahl dieses Modus stellt Talend Studio eine Verbindung zu einem Spark-fähigen benutzerspezifischen Cluster für die Ausführung des Jobs ausgehend von diesem Cluster her. Mit der Betaversion dieser Funktion wird keine Unterstützung für Hive und HBase geboten. Spark-Jobs mit Avro-Komponenten werden im Augenblick ebenfalls nicht unterstützt. 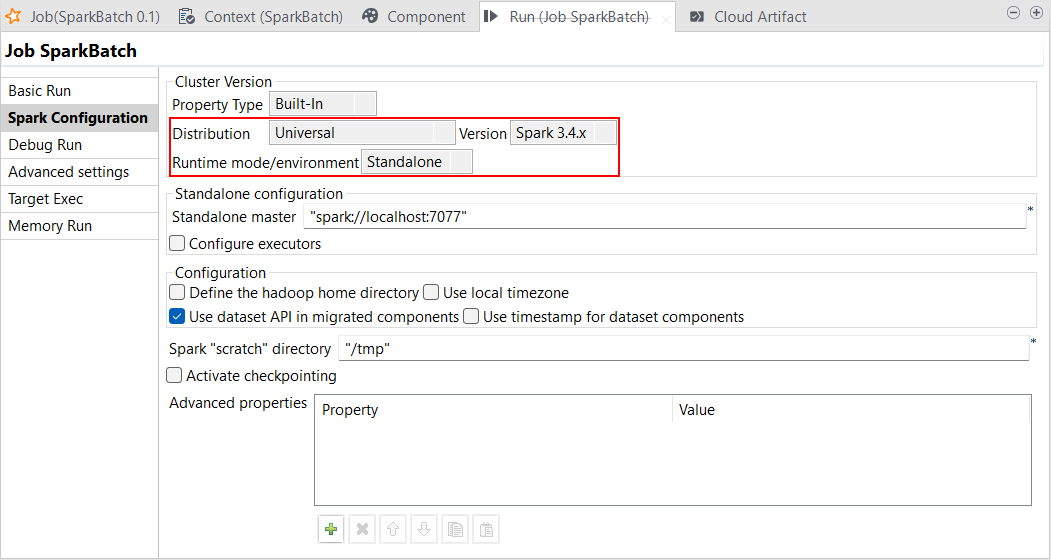
|
Alle abonnementbasierte Produkte von Talend mit Big Data |
| Unterstützung für CDP Private Cloud Base 7.1.8 mit Spark 3.3.x | Es wird jetzt Unterstützung für CDP Private Cloud Base 7.1.8 mit Spark 3.3.x geboten. Sie können Ihre Spark-Jobs in CDP Private Cloud Base 7.1.8 unter Verwendung des Modus Yarn cluster (Yarn-Cluster) in Spark Universal ausführen. |
Alle abonnementbasierte Produkte von Talend mit Big Data |