
KMeans2D() evaluates the rows of the chart by applying k-means clustering, and for each chart row displays the cluster id of the cluster this data point has been assigned to. The columns that are used by the clustering algorithm are determined by the parameters coordinate_1, and coordinate_2, respectively. These are both aggregations. The number of clusters that are created is determined by the num_clusters parameter. Data can be optionally normalized by the norm parameter.
KMeans2D returns one value per data point. The returned value is a dual and is the integer value corresponding to the cluster each data point has been assigned to.
Syntax:
KMeans2D(num_clusters, coordinate_1, coordinate_2 [, norm])
Return data type: dual
Arguments:
| Argument | Description |
|---|---|
| num_clusters | Integer that specifies the number of clusters. |
| coordinate_1 | The aggregation that calculates the first coordinate, usually the x-axis of the scatter chart that can be made from the chart. The additional parameter, coordinate_2, calculates the second coordinate. |
| norm |
The optional normalization method applied to datasets before KMeans clustering. Possible values: 0 or ‘none’ for no normalization 1 or ‘zscore’ for z-score normalization 2 or ‘minmax’ for min-max normalization If no parameter is supplied or if the supplied parameter is incorrect, no normalization is applied. Z-score normalizes data based on feature mean and standard deviation. Z-score does not ensure each feature has the same scale but it is a better approach than min-max when dealing with outliers. Min-max normalization ensures that the features have the same scale by taking the minimum and maximum values of each and recalculating each datapoint. |
In this example, we create a scatter plot chart using the Iris dataset, and then use KMeans to color the data by expression.
We also create a variable for the num_clusters argument, and then use a variable input box to change the number of clusters.
The Iris data set is publicly available in a variety of formats. We have provided the data as an inline table to load using the data load editor in Qlik Sense. Note that we added an Id column to the data table for this example.
Iris data set: Inline load for data load editor in Qlik Sense
After loading the data in Qlik Sense, we do the following:
- Drag a Scatter plot chart onto a new sheet. Name the chart Petal (color by expression).
- Create a variable to specify the number of clusters. For the variable Name, enter KmeansPetalClusters. For the variable Definition, enter =2.
-
Configure Data for the chart:
- Under Dimensions, choose id for the field for Bubble. Enter Cluster Id for the Label.
- Under Measures, choose Sum([petal.length]) for the expression for X-axis.
Under Measures, choose Sum([petal.width]) for the expression for Y-axis.
Data settings for Petal (color by expression) chart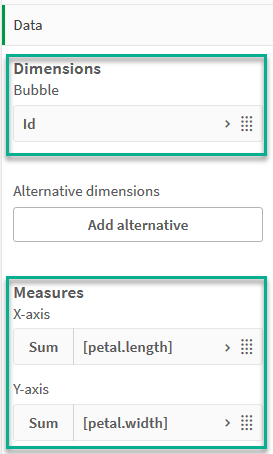
The data points are plotted on the chart.
Data points on Petal (color by expression) chart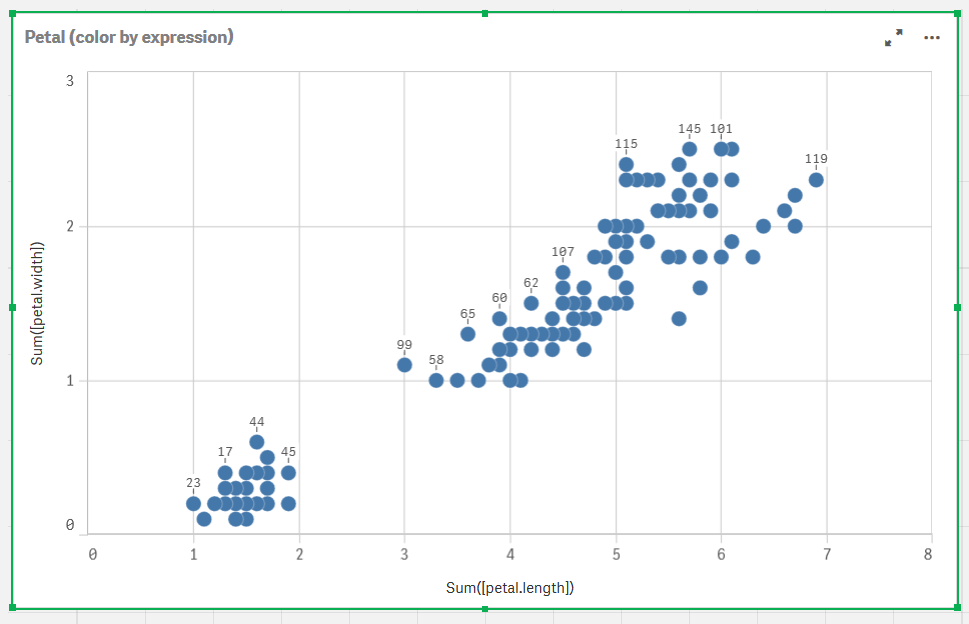
- Configure Appearance for the chart:
- Under Colors and legend, choose Custom for Colors.
- Choose to color the chart By expression.
Enter the following for Expression: kmeans2d($(KmeansPetalClusters), Sum([petal.length]), Sum([petal.width]))
Note that KmeansPetalClusters is the variable that we set to 2.
Alternatively, enter the following: kmeans2d(2, Sum([petal.length]), Sum([petal.width]))
- Deselect the check box for The expression is a color code.
- Enter the following for Label: Cluster Id
Appearance settings for Petal (color by expression) chart
The two clusters on the chart are colored by the KMeans expression.
Clusters colored by expression on Petal (color by expression) chart
-
Add a Variable input box for the number of clusters.
- Under Custom objects in the Assets panel, choose Qlik Dashboard bundle. If we did not have access to the dashboard bundle, we could still change the number of clusters using the variable that we created, or directly as an integer in the expression.
- Drag a Variable input box onto the sheet.
- Under Appearance, click General.
- Enter the following for Title: Clusters
- Click Variable.
- Choose the following variable for Name: KmeansPetalClusters.
- Choose Slider for Show as.
- Choose Values, and configure the settings as required,
Appearance for Clusters variable input box
When we are done editing, we can change the number of clusters using the slider in the Clusters variable input box.

Auto-clustering
KMeans functions support auto-clustering using a method called depth difference (DeD). When a user sets 0 for the number of clusters, an optimal number of clusters for that dataset is determined. Note that while an integer for the number of clusters (k) is not explicitly returned, it is calculated within the KMeans algorithm. For example, if 0 is specified in the function for the value of KmeansPetalClusters or set through a variable input box, cluster assignments are automatically calculated for the dataset based on an optimal number of clusters.
KMeans depth difference method determines optimal number of clusters when (k) is set to 0

Iris data set: Inline load for data load editor in Qlik Sense
IrisData:
Load * Inline [
sepal.length, sepal.width, petal.length, petal.width, variety, id
5.1, 3.5, 1.4, 0.2, Setosa, 1
4.9, 3, 1.4, 0.2, Setosa, 2
4.7, 3.2, 1.3, 0.2, Setosa, 3
4.6, 3.1, 1.5, 0.2, Setosa, 4
5, 3.6, 1.4, 0.2, Setosa, 5
5.4, 3.9, 1.7, 0.4, Setosa, 6
4.6, 3.4, 1.4, 0.3, Setosa, 7
5, 3.4, 1.5, 0.2, Setosa, 8
4.4, 2.9, 1.4, 0.2, Setosa, 9
4.9, 3.1, 1.5, 0.1, Setosa, 10
5.4, 3.7, 1.5, 0.2, Setosa, 11
4.8, 3.4, 1.6, 0.2, Setosa, 12
4.8, 3, 1.4, 0.1, Setosa, 13
4.3, 3, 1.1, 0.1, Setosa, 14
5.8, 4, 1.2, 0.2, Setosa, 15
5.7, 4.4, 1.5, 0.4, Setosa, 16
5.4, 3.9, 1.3, 0.4, Setosa, 17
5.1, 3.5, 1.4, 0.3, Setosa, 18
5.7, 3.8, 1.7, 0.3, Setosa, 19
5.1, 3.8, 1.5, 0.3, Setosa, 20
5.4, 3.4, 1.7, 0.2, Setosa, 21
5.1, 3.7, 1.5, 0.4, Setosa, 22
4.6, 3.6, 1, 0.2, Setosa, 23
5.1, 3.3, 1.7, 0.5, Setosa, 24
4.8, 3.4, 1.9, 0.2, Setosa, 25
5, 3, 1.6, 0.2, Setosa, 26
5, 3.4, 1.6, 0.4, Setosa, 27
5.2, 3.5, 1.5, 0.2, Setosa, 28
5.2, 3.4, 1.4, 0.2, Setosa, 29
4.7, 3.2, 1.6, 0.2, Setosa, 30
4.8, 3.1, 1.6, 0.2, Setosa, 31
5.4, 3.4, 1.5, 0.4, Setosa, 32
5.2, 4.1, 1.5, 0.1, Setosa, 33
5.5, 4.2, 1.4, 0.2, Setosa, 34
4.9, 3.1, 1.5, 0.1, Setosa, 35
5, 3.2, 1.2, 0.2, Setosa, 36
5.5, 3.5, 1.3, 0.2, Setosa, 37
4.9, 3.1, 1.5, 0.1, Setosa, 38
4.4, 3, 1.3, 0.2, Setosa, 39
5.1, 3.4, 1.5, 0.2, Setosa, 40
5, 3.5, 1.3, 0.3, Setosa, 41
4.5, 2.3, 1.3, 0.3, Setosa, 42
4.4, 3.2, 1.3, 0.2, Setosa, 43
5, 3.5, 1.6, 0.6, Setosa, 44
5.1, 3.8, 1.9, 0.4, Setosa, 45
4.8, 3, 1.4, 0.3, Setosa, 46
5.1, 3.8, 1.6, 0.2, Setosa, 47
4.6, 3.2, 1.4, 0.2, Setosa, 48
5.3, 3.7, 1.5, 0.2, Setosa, 49
5, 3.3, 1.4, 0.2, Setosa, 50
7, 3.2, 4.7, 1.4, Versicolor, 51
6.4, 3.2, 4.5, 1.5, Versicolor, 52
6.9, 3.1, 4.9, 1.5, Versicolor, 53
5.5, 2.3, 4, 1.3, Versicolor, 54
6.5, 2.8, 4.6, 1.5, Versicolor, 55
5.7, 2.8, 4.5, 1.3, Versicolor, 56
6.3, 3.3, 4.7, 1.6, Versicolor, 57
4.9, 2.4, 3.3, 1, Versicolor, 58
6.6, 2.9, 4.6, 1.3, Versicolor, 59
5.2, 2.7, 3.9, 1.4, Versicolor, 60
5, 2, 3.5, 1, Versicolor, 61
5.9, 3, 4.2, 1.5, Versicolor, 62
6, 2.2, 4, 1, Versicolor, 63
6.1, 2.9, 4.7, 1.4, Versicolor, 64
5.6, 2.9, 3.6, 1.3, Versicolor, 65
6.7, 3.1, 4.4, 1.4, Versicolor, 66
5.6, 3, 4.5, 1.5, Versicolor, 67
5.8, 2.7, 4.1, 1, Versicolor, 68
6.2, 2.2, 4.5, 1.5, Versicolor, 69
5.6, 2.5, 3.9, 1.1, Versicolor, 70
5.9, 3.2, 4.8, 1.8, Versicolor, 71
6.1, 2.8, 4, 1.3, Versicolor, 72
6.3, 2.5, 4.9, 1.5, Versicolor, 73
6.1, 2.8, 4.7, 1.2, Versicolor, 74
6.4, 2.9, 4.3, 1.3, Versicolor, 75
6.6, 3, 4.4, 1.4, Versicolor, 76
6.8, 2.8, 4.8, 1.4, Versicolor, 77
6.7, 3, 5, 1.7, Versicolor, 78
6, 2.9, 4.5, 1.5, Versicolor, 79
5.7, 2.6, 3.5, 1, Versicolor, 80
5.5, 2.4, 3.8, 1.1, Versicolor, 81
5.5, 2.4, 3.7, 1, Versicolor, 82
5.8, 2.7, 3.9, 1.2, Versicolor, 83
6, 2.7, 5.1, 1.6, Versicolor, 84
5.4, 3, 4.5, 1.5, Versicolor, 85
6, 3.4, 4.5, 1.6, Versicolor, 86
6.7, 3.1, 4.7, 1.5, Versicolor, 87
6.3, 2.3, 4.4, 1.3, Versicolor, 88
5.6, 3, 4.1, 1.3, Versicolor, 89
5.5, 2.5, 4, 1.3, Versicolor, 90
5.5, 2.6, 4.4, 1.2, Versicolor, 91
6.1, 3, 4.6, 1.4, Versicolor, 92
5.8, 2.6, 4, 1.2, Versicolor, 93
5, 2.3, 3.3, 1, Versicolor, 94
5.6, 2.7, 4.2, 1.3, Versicolor, 95
5.7, 3, 4.2, 1.2, Versicolor, 96
5.7, 2.9, 4.2, 1.3, Versicolor, 97
6.2, 2.9, 4.3, 1.3, Versicolor, 98
5.1, 2.5, 3, 1.1, Versicolor, 99
5.7, 2.8, 4.1, 1.3, Versicolor, 100
6.3, 3.3, 6, 2.5, Virginica, 101
5.8, 2.7, 5.1, 1.9, Virginica, 102
7.1, 3, 5.9, 2.1, Virginica, 103
6.3, 2.9, 5.6, 1.8, Virginica, 104
6.5, 3, 5.8, 2.2, Virginica, 105
7.6, 3, 6.6, 2.1, Virginica, 106
4.9, 2.5, 4.5, 1.7, Virginica, 107
7.3, 2.9, 6.3, 1.8, Virginica, 108
6.7, 2.5, 5.8, 1.8, Virginica, 109
7.2, 3.6, 6.1, 2.5, Virginica, 110
6.5, 3.2, 5.1, 2, Virginica, 111
6.4, 2.7, 5.3, 1.9, Virginica, 112
6.8, 3, 5.5, 2.1, Virginica, 113
5.7, 2.5, 5, 2, Virginica, 114
5.8, 2.8, 5.1, 2.4, Virginica, 115
6.4, 3.2, 5.3, 2.3, Virginica, 116
6.5, 3, 5.5, 1.8, Virginica, 117
7.7, 3.8, 6.7, 2.2, Virginica, 118
7.7, 2.6, 6.9, 2.3, Virginica, 119
6, 2.2, 5, 1.5, Virginica, 120
6.9, 3.2, 5.7, 2.3, Virginica, 121
5.6, 2.8, 4.9, 2, Virginica, 122
7.7, 2.8, 6.7, 2, Virginica, 123
6.3, 2.7, 4.9, 1.8, Virginica, 124
6.7, 3.3, 5.7, 2.1, Virginica, 125
7.2, 3.2, 6, 1.8, Virginica, 126
6.2, 2.8, 4.8, 1.8, Virginica, 127
6.1, 3, 4.9, 1.8, Virginica, 128
6.4, 2.8, 5.6, 2.1, Virginica, 129
7.2, 3, 5.8, 1.6, Virginica, 130
7.4, 2.8, 6.1, 1.9, Virginica, 131
7.9, 3.8, 6.4, 2, Virginica, 132
6.4, 2.8, 5.6, 2.2, Virginica, 133
6.3, 2.8, 5.1, 1.5, Virginica, 134
6.1, 2.6, 5.6, 1.4, Virginica, 135
7.7, 3, 6.1, 2.3, Virginica, 136
6.3, 3.4, 5.6, 2.4, Virginica, 137
6.4, 3.1, 5.5, 1.8, Virginica, 138
6, 3, 4.8, 1.8, Virginica, 139
6.9, 3.1, 5.4, 2.1, Virginica, 140
6.7, 3.1, 5.6, 2.4, Virginica, 141
6.9, 3.1, 5.1, 2.3, Virginica, 142
5.8, 2.7, 5.1, 1.9, Virginica, 143
6.8, 3.2, 5.9, 2.3, Virginica, 144
6.7, 3.3, 5.7, 2.5, Virginica, 145
6.7, 3, 5.2, 2.3, Virginica, 146
6.3, 2.5, 5, 1.9, Virginica, 147
6.5, 3, 5.2, 2, Virginica, 148
6.2, 3.4, 5.4, 2.3, Virginica, 149
5.9, 3, 5.1, 1.8, Virginica, 150
];