
与您的大数据平台建立连接
如果在 Repository (存储库) 中建立与给定大数据平台的连接,此后每次需要使用该平台时,无需再配置与该平台的连接。
本示例中使用的大数据平台是 Databricks V5.4 集群,以及 Azure Data Lake Storage Gen2。
开始之前
-
确保已在 Databricks 中正确创建 Spark 集群。
有关更多信息,请参阅 Databricks 文档中的创建 Databricks 工作区 (仅提供英文版本)。
- 您有一个 Azure 帐户。
- 已正确创建 Azure Data Lake Storage Gen2 的存储帐户,并且您对其具有适当的读取和写入权限。有关如何创建这种存储帐户的更多信息,请参阅 Azure 文档中的创建启用了 Azure Data Lake Storage Gen2 的存储帐户 (仅提供英文版本)。
-
当前视图为 集成 透视图。
关于此任务
步骤
-
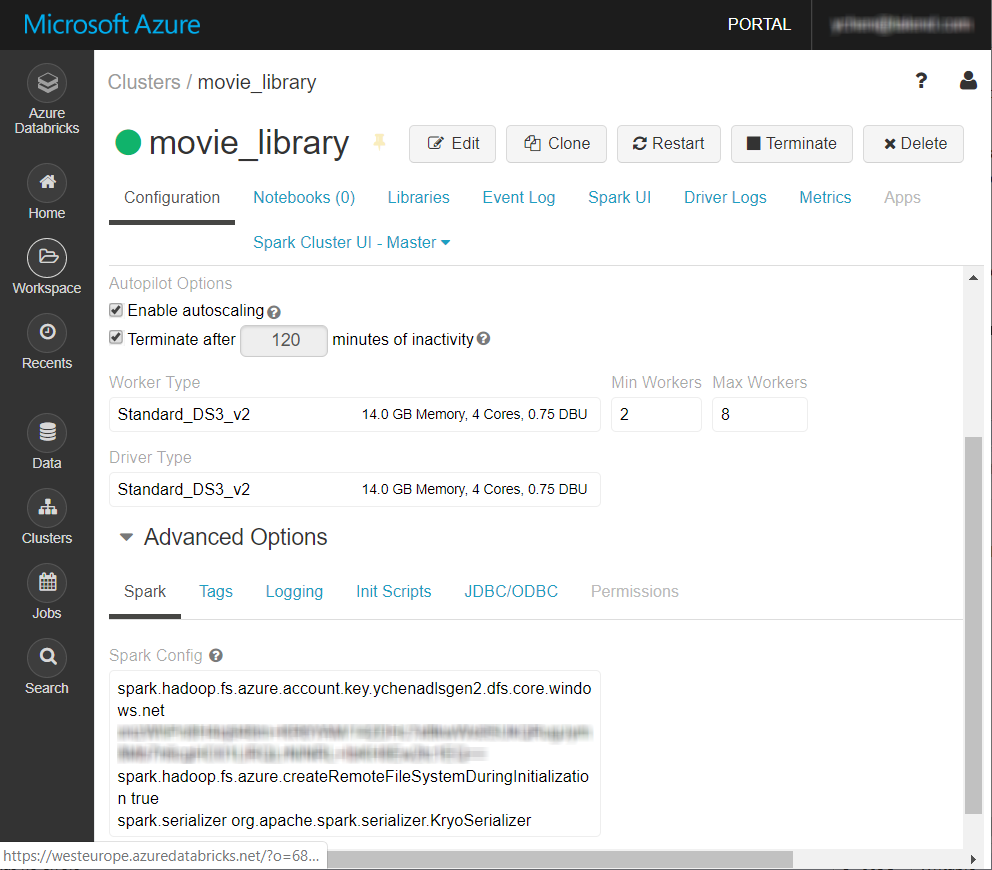
在 Databricks 集群页面的 Configuration (配置) 选项卡上,向下滚动到页面底部的 Spark 选项卡。
示例
-
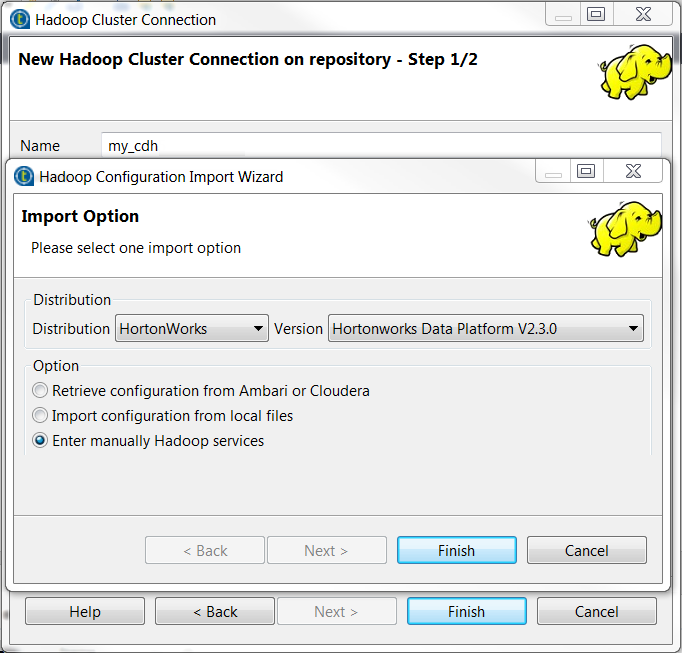
选中 Enter manually Hadoop services (手动输入 Hadoop 服务) 复选框,手动输入正在创建的 Databricks 连接的配置信息。
结果
新连接 (本示例中名为 movie_library) 将显示在 Repository (存储库) 树视图的 Hadoop cluster (Hadoop 集群) 文件夹下。