
Definieren einer Gruppierungskampagne
Definieren Sie eine Kampagne, um den Data Stewards die Kennzeichnung eines Samples mit verdächtigen Datensätzen beim Matching extrem umfangreicher Datenvolumen über maschinelles Lernen („Machine Learning“) in Spark zu ermöglichen.
Prozedur
-
Wählen Sie Grouping (Gruppieren) als Kampagnentyp aus.
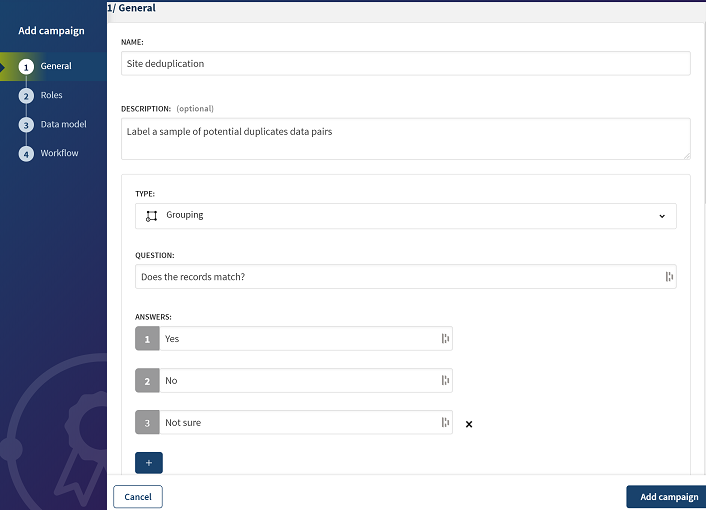
-
Über die Schaltfläche
 können Sie nach Bedarf weitere Auswahlmöglichkeiten hinzufügen. Geben Sie die Antworten in die Felder Answers (Antworten) ein, wie im obigen Screenshot gezeigt.
können Sie nach Bedarf weitere Auswahlmöglichkeiten hinzufügen. Geben Sie die Antworten in die Felder Answers (Antworten) ein, wie im obigen Screenshot gezeigt.