
Convertir des Jobs
Vous pouvez créer un Job en le convertissant depuis un framework différent, par exemple depuis Standard vers Spark.
Cette option est recommandée si les composants utilisés dans un Job source sont également disponibles pour le Job cible. Par exemple, si vous devez convertir un Job Standard en un Job Spark Batch.
Procédure
-
Modifiez les informations du Job, si nécessaire.
Si vous devez modifier des informations contenues dans les champs en lecture seule, utilisez l'assistant [Project settings] pour effectuer ces modifications. Pour plus d'informations, consultez Personnalisation des paramètres du projet.
Exemple
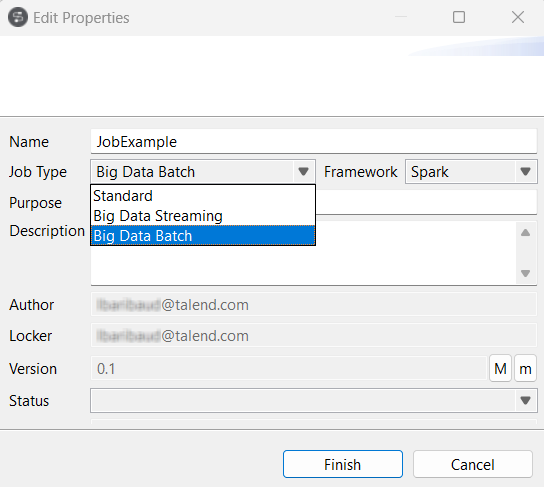
Résultats
Le Job converti s'affiche sous le nœud Big Data Batch.
Vous pouvez également sélectionner l'option Duplicate dans le menu contextuel pour accéder à la conversion ; cette approche vous permet de conserver le Job source avec son framework original et en crée un doublon dans le framework cible.
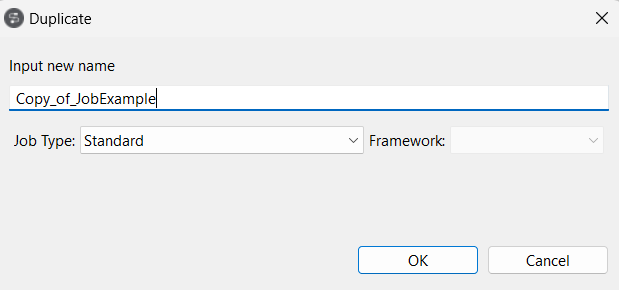
Vous pouvez également reproduire cette procédure pour convertir un Job Spark en un Job standard ou vers d'autres frameworks. Pour ce faire, sélectionnez l'option Edit Big Data Batch properties dans le menu contextuel.
Dans un Job standard, si vous utilisez une connexion à Hadoop précédemment définie dans le référentiel et que vous cliquez sur le bouton Finish, l'assistant [Select node] s'ouvre et vous permet de sélectionner cette connexion ainsi que de la réutiliser automatiquement dans le Job Spark à créer.
Chaque composant apparaissant dans l'assistant est utilisé par le Job source standard. En le sélectionnant, vous réutilisez les métadonnées de connexion Hadoop qu'il contient dans le Job Spark que vous créez.