
Hacher des champs pour comparer les données de manière sécurisée
Avant de commencer
-
Vous avez précédemment créé une connexion au système stockant vos données source.
Ici, une connexion Amazon S3.
-
Vous avez précédemment ajouté le jeu de données contenant vos données source.
Téléchargez le fichier string-crops.csv. Il contient un jeu de données concernant des cultures récoltées au Mali, ainsi que les types de cultures, la valeur de production, les zones de récolte, etc.
-
Vous avez créé la connexion et le jeu de données associé qui contiendra les données traitées.
Ici, un jeu de données stocké dans le même bucket S3.
Procédure
-
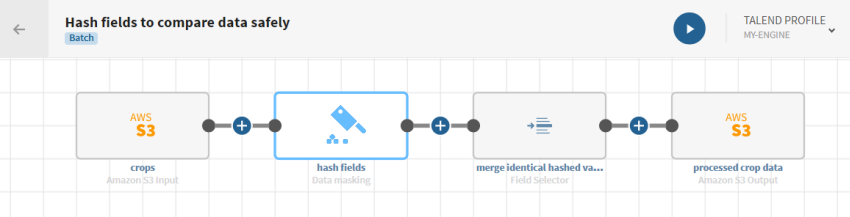
Cliquez sur ADD SOURCE pour ouvrir le panneau vous permettant de sélectionner vos données source, ici les données relatives aux cultures récoltées au Mali en 2005.
Exemple
-
Cliquez sur le bouton
 et ajoutez un processeur Data hashing au pipeline. Le panneau de configuration s'ouvre.
et ajoutez un processeur Data hashing au pipeline. Le panneau de configuration s'ouvre.
-
Dans la zone Configuration :
-
Cliquez sur l'icône
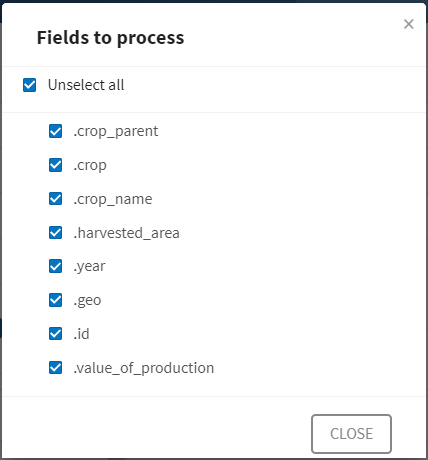
 près de la liste Fields to process (Champs à traiter) afin de sélectionner tous les champs, car vous souhaitez hacher toutes les valeurs en une fois.
près de la liste Fields to process (Champs à traiter) afin de sélectionner tous les champs, car vous souhaitez hacher toutes les valeurs en une fois.
-
Cliquez sur l'icône
-
Cliquez sur Save (Sauvegarder) pour sauvegarder votre configuration.
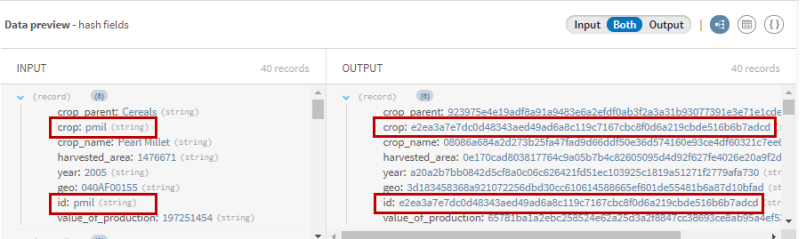
Examinez la prévisualisation du processeur afin de comparer vos données avant et après l'opération.
Tous les champs sont hachés et sécurisés. Vous pouvez voir que les champs crop et id ont la même valeur de sortie, ce qui signifie que la valeur originale est la même dans les deux champs.
-
Cliquez sur le bouton et ajoutez un processeur Field selector au pipeline. Le panneau de configuration s'ouvre.
-
Cliquez sur Save (Sauvegarder) pour sauvegarder votre configuration.
Examinez la prévisualisation du processeur afin de comparer vos données avant et après l'opération.

Résultats
Votre pipeline est en cours d’exécution, les données sont hachées, les champs identiques ont été fusionnés et réorganisés selon les conditions spécifiées et la sortie est envoyée vers le système cible défini.