
Définir la règle de rapprochement
Procédure
-
Dans la vue Basic settings du tMatchGroup, cliquez sur Preview pour ouvrir l'assistant de configuration et définir la clé de rapprochement et la fonction de consolidation.
 Vous pouvez utiliser l'assistant de configuration pour importer des règles de rapprochement créées puis testées dans le Studio et stockées dans le référentiel et les utiliser dans vos Jobs de rapprochement. Pour plus d'informations, consultez Import de règles de mise en correspondance depuis le référentiel du Studio.Il est important d'avoir le même type d'algorithme de rapprochement sélectionné dans les propriétés simples du composant et défini dans l'assistant de configuration. Sinon, le Job s'exécute avec les valeurs par défaut pour les paramètres qui ne sont pas compatibles avec les deux algorithmes.
Vous pouvez utiliser l'assistant de configuration pour importer des règles de rapprochement créées puis testées dans le Studio et stockées dans le référentiel et les utiliser dans vos Jobs de rapprochement. Pour plus d'informations, consultez Import de règles de mise en correspondance depuis le référentiel du Studio.Il est important d'avoir le même type d'algorithme de rapprochement sélectionné dans les propriétés simples du composant et défini dans l'assistant de configuration. Sinon, le Job s'exécute avec les valeurs par défaut pour les paramètres qui ne sont pas compatibles avec les deux algorithmes. -
Cliquez sur le bouton Chart dans l'assistant pour exécuter le Job avec la configuration définie et obtenir les résultats directement dans l'assistant.
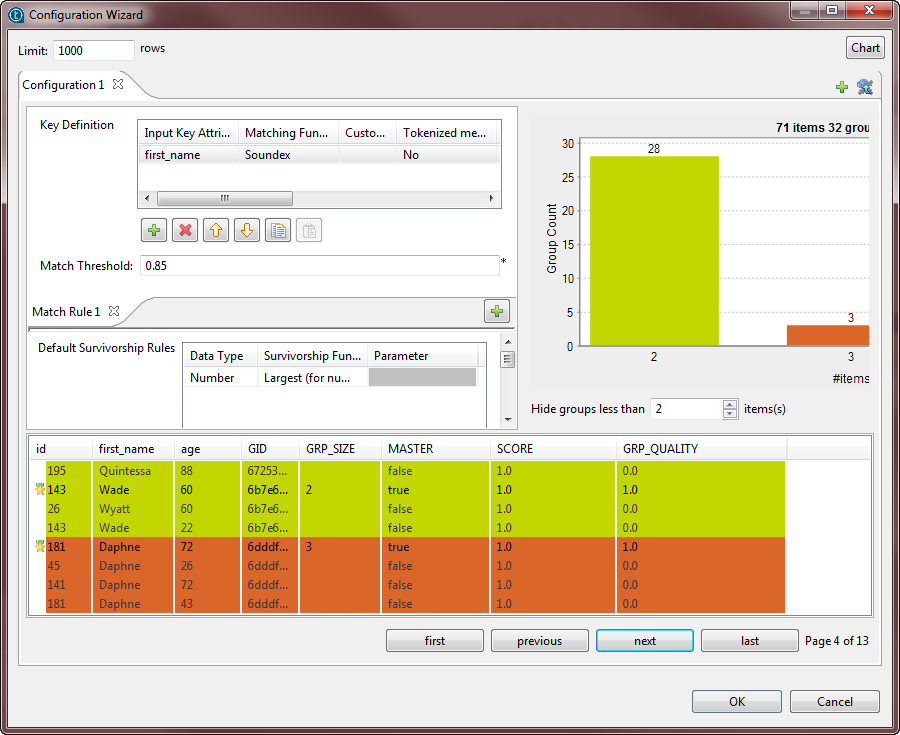 Le diagramme de rapprochement donne une vue globale des doublons dans les données analysées. La table de rapprochement indique les détails des éléments dans chaque groupe, colore les groupes selon les couleurs du diagramme de rapprochement et indique par true les enregistrements maître. L'enregistrement maître de chaque groupe est le résultat de la fusion de deux enregistrements similaires selon l'algorithme phonétique et la règle de consolidation. L'enregistrement maître est un nouvel enregistrement qui n'existe pas dans les données d'entrée.
Le diagramme de rapprochement donne une vue globale des doublons dans les données analysées. La table de rapprochement indique les détails des éléments dans chaque groupe, colore les groupes selon les couleurs du diagramme de rapprochement et indique par true les enregistrements maître. L'enregistrement maître de chaque groupe est le résultat de la fusion de deux enregistrements similaires selon l'algorithme phonétique et la règle de consolidation. L'enregistrement maître est un nouvel enregistrement qui n'existe pas dans les données d'entrée.