
Vérifier les composants de transformation
Procédure
-
Double-cliquez sur le tSortRow afin d'ouvrir sa vue Component.
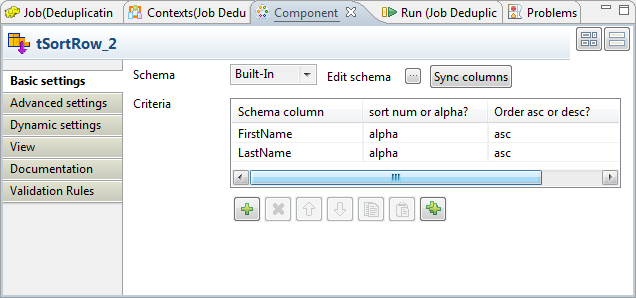 Ce composant garde la configuration utilisée dans le Job d'origine. Il trie les données d'entrée par ordre alphabétique à partir des colonnes FirstName et LastName.
Ce composant garde la configuration utilisée dans le Job d'origine. Il trie les données d'entrée par ordre alphabétique à partir des colonnes FirstName et LastName. -
Double-cliquez sur le tUniqRow pour ouvrir sa vue Component.
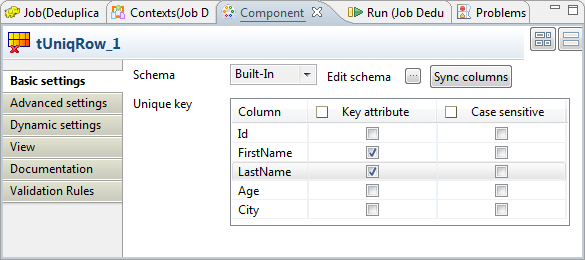 Le composant garde également la configuration utilisée dans le Job d'origine. Il sépare les données d'entrée en un flux Uniques et un flux Duplicates (Doublons), puis envoie les données uniques dans le tHDFSOutput et les doublons dans le tJDBCOutput.
Le composant garde également la configuration utilisée dans le Job d'origine. Il sépare les données d'entrée en un flux Uniques et un flux Duplicates (Doublons), puis envoie les données uniques dans le tHDFSOutput et les doublons dans le tJDBCOutput.