Note InformationsRemarque : Lorsque vous sélectionnez une colonne de dates sur laquelle appliquer un algorithme ou un algorithme de rapprochement, vous pouvez choisir ce que vous souhaitez comparer dans le format de date.
Par exemple, si vous souhaitez comparer uniquement l'année, attribuez le type Date à la colonne concernée dans le schéma du composant puis saisissez "yyyy" dans le champ Date Pattern. Le composant convertit le format de date en une chaîne de caractères, selon le modèle défini dans le schéma, avant de comparer les chaînes de caractères.

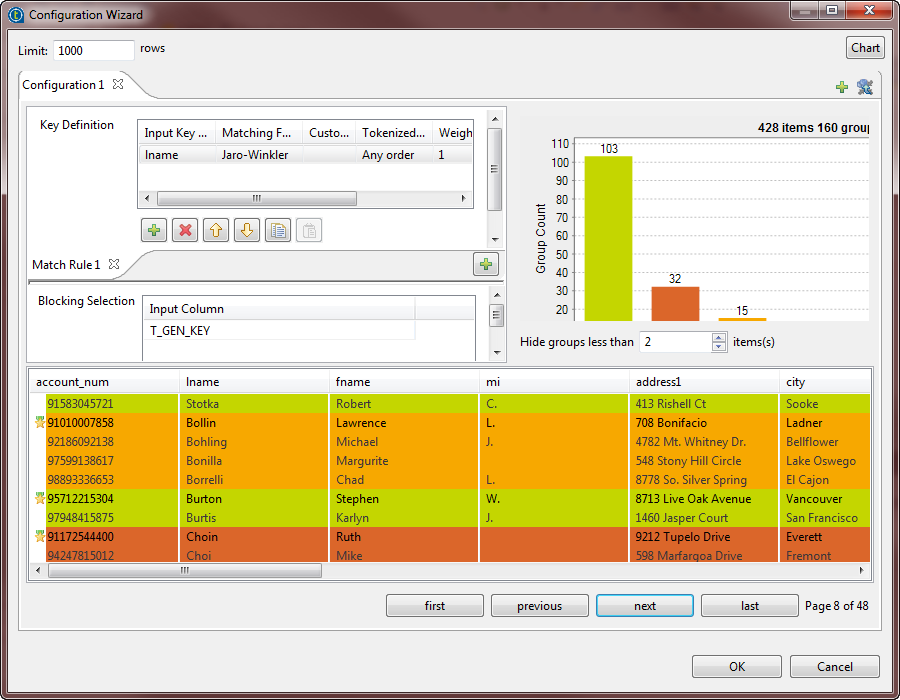
 et importez les clés de rapprochement depuis les règles de rapprochement créées et testées dans la perspective Profiling du Studio Talend et utilisez-les dans votre Job. Sinon, définissez les paramètres, des clés de rapprochement comme décrit dans les étapes ci-dessous.
Il est important d'importer ou de définir dans les propriétés simples du composant le même type de règle, sinon, le Job s'exécute avec les valeurs par défaut des paramètres n'étant pas compatibles avec le deux algorithmes.
et importez les clés de rapprochement depuis les règles de rapprochement créées et testées dans la perspective Profiling du Studio Talend et utilisez-les dans votre Job. Sinon, définissez les paramètres, des clés de rapprochement comme décrit dans les étapes ci-dessous.
Il est important d'importer ou de définir dans les propriétés simples du composant le même type de règle, sinon, le Job s'exécute avec les valeurs par défaut des paramètres n'étant pas compatibles avec le deux algorithmes.